 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemCSE: Semantic Contrastive Sentence Embeddings Using LLM-Generated Summaries For Scientific Abstracts
Jul 17, 2025



We introduce SemCSE, an unsupervised method for learning semantic embeddings of scientific texts. Building on recent advances in contrastive learning for text embeddings, our approach leverages LLM-generated summaries of scientific abstracts to train a model that positions semantically related summaries closer together in the embedding space. This resulting objective ensures that the model captures the true semantic content of a text, in contrast to traditional citation-based approaches that do not necessarily reflect semantic similarity. To validate this, we propose a novel benchmark designed to assess a model's ability to understand and encode the semantic content of scientific texts, demonstrating that our method enforces a stronger semantic separation within the embedding space. Additionally, we evaluate SemCSE on the comprehensive SciRepEval benchmark for scientific text embeddings, where it achieves state-of-the-art performance among models of its size, thus highlighting the benefits of a semantically focused training approach.
Resolving References to Objects in Photographs using the Words-As-Classifiers Model
Jun 03, 2016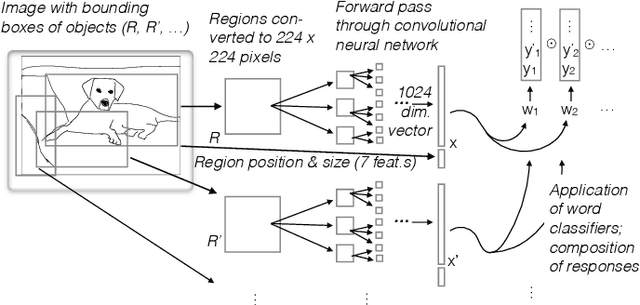
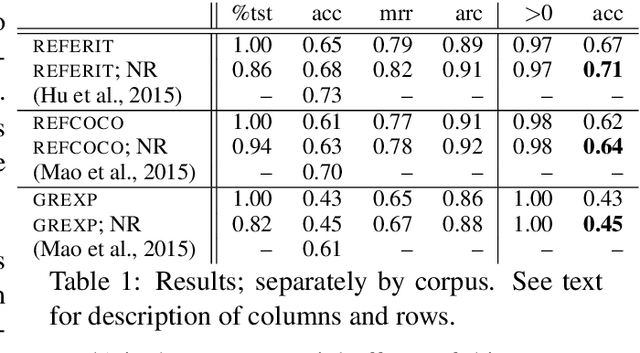

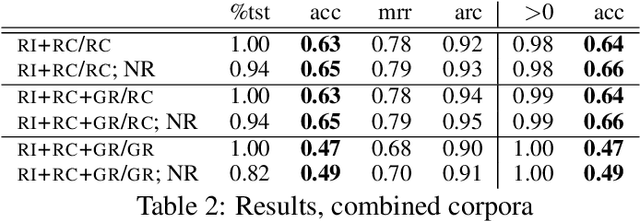
A common use of language is to refer to visually present objects. Modelling it in computers requires modelling the link between language and perception. The "words as classifiers" model of grounded semantics views words as classifiers of perceptual contexts, and composes the meaning of a phrase through composition of the denotations of its component words. It was recently shown to perform well in a game-playing scenario with a small number of object types. We apply it to two large sets of real-world photographs that contain a much larger variety of types and for which referring expressions are available. Using a pre-trained convolutional neural network to extract image features, and augmenting these with in-picture positional information, we show that the model achieves performance competitive with the state of the art in a reference resolution task (given expression, find bounding box of its referent), while, as we argue, being conceptually simpler and more flexible.