 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstruction of FuzzyFind Dictionary using Golay Coding Transformation for Searching Applications
Mar 22, 2015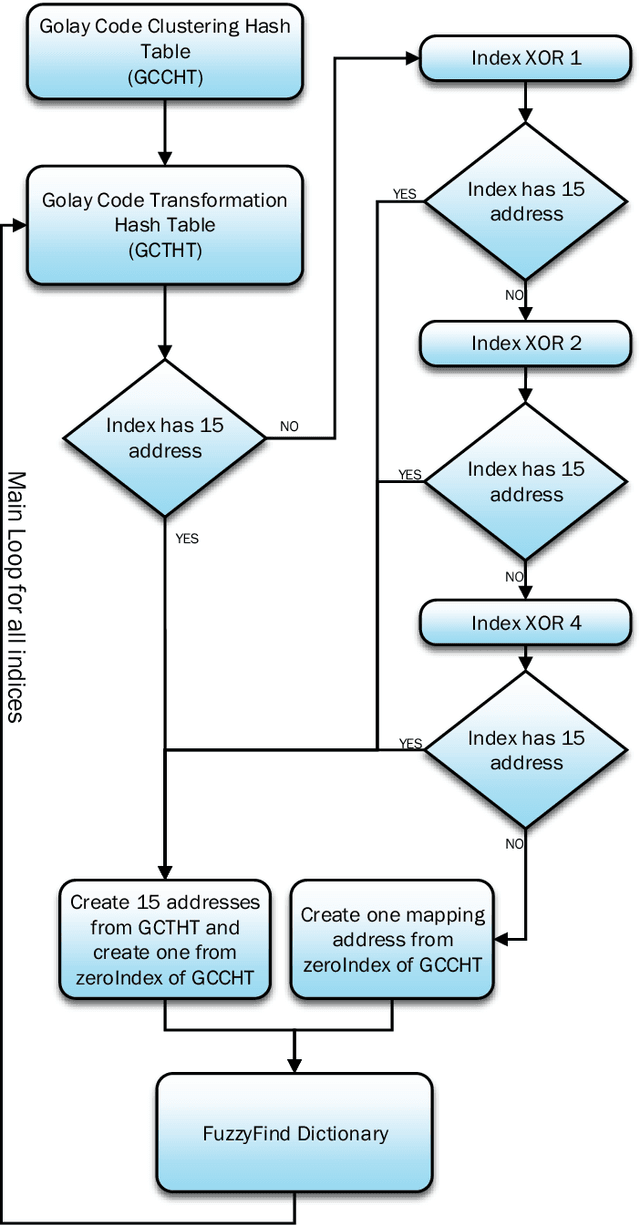
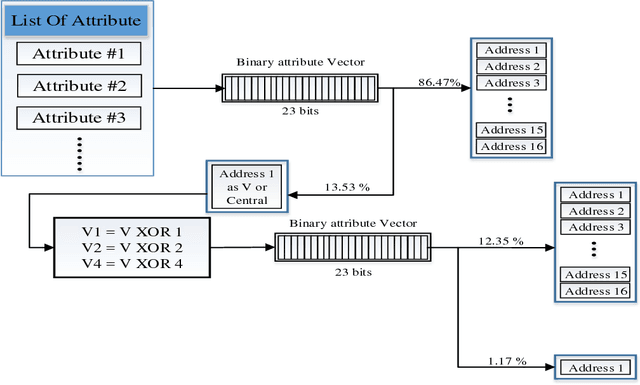

Searching through a large volume of data is very critical for companies, scientists, and searching engines applications due to time complexity and memory complexity. In this paper, a new technique of generating FuzzyFind Dictionary for text mining was introduced. We simply mapped the 23 bits of the English alphabet into a FuzzyFind Dictionary or more than 23 bits by using more FuzzyFind Dictionary, and reflecting the presence or absence of particular letters. This representation preserves closeness of word distortions in terms of closeness of the created binary vectors within Hamming distance of 2 deviations. This paper talks about the Golay Coding Transformation Hash Table and how it can be used on a FuzzyFind Dictionary as a new technology for using in searching through big data. This method is introduced by linear time complexity for generating the dictionary and constant time complexity to access the data and update by new data sets, also updating for new data sets is linear time depends on new data points. This technique is based on searching only for letters of English that each segment has 23 bits, and also we have more than 23-bit and also it could work with more segments as reference table.
Novel Metaknowledge-based Processing Technique for Multimedia Big Data clustering challenges
Mar 01, 2015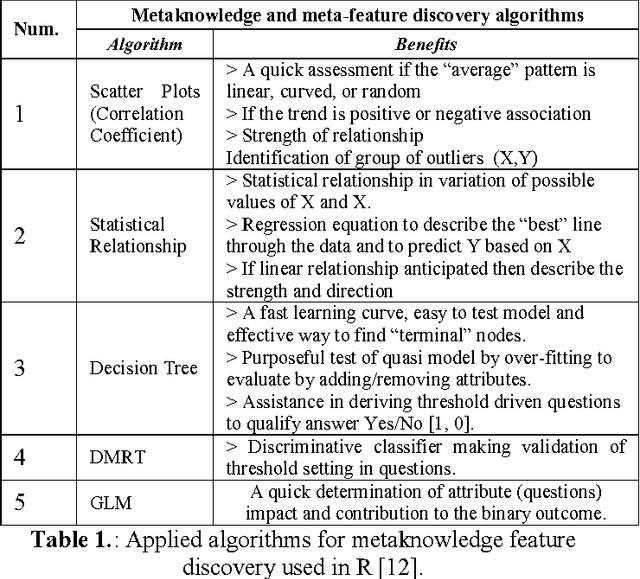
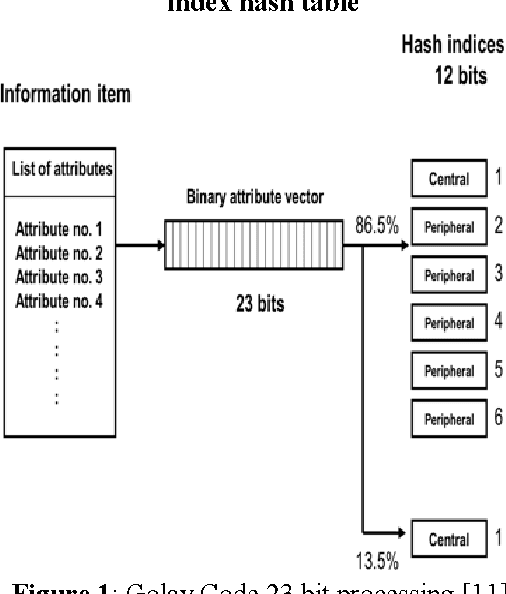

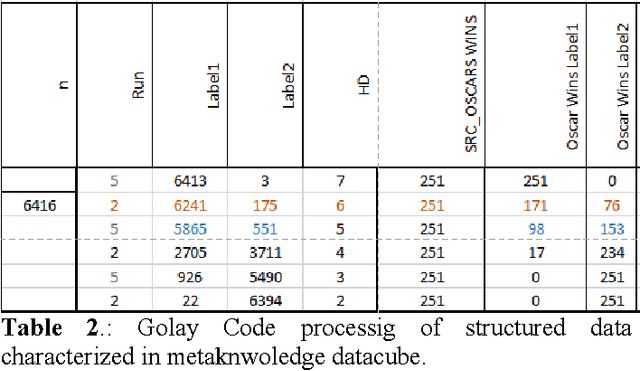
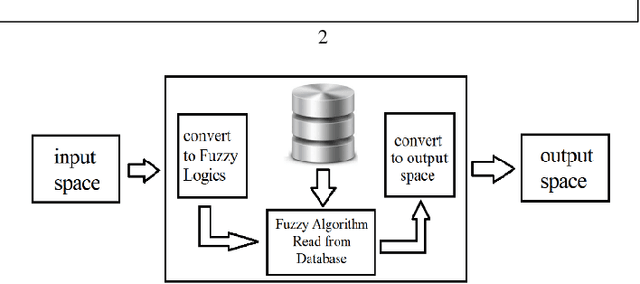
Past research has challenged us with the task of showing relational patterns between text-based data and then clustering for predictive analysis using Golay Code technique. We focus on a novel approach to extract metaknowledge in multimedia datasets. Our collaboration has been an on-going task of studying the relational patterns between datapoints based on metafeatures extracted from metaknowledge in multimedia datasets. Those selected are significant to suit the mining technique we applied, Golay Code algorithm. In this research paper we summarize findings in optimization of metaknowledge representation for 23-bit representation of structured and unstructured multimedia data in order to
23-bit Metaknowledge Template Towards Big Data Knowledge Discovery and Management
Mar 01, 2015
The global influence of Big Data is not only growing but seemingly endless. The trend is leaning towards knowledge that is attained easily and quickly from massive pools of Big Data. Today we are living in the technological world that Dr. Usama Fayyad and his distinguished research fellows discussed in the introductory explanations of Knowledge Discovery in Databases (KDD) predicted nearly two decades ago. Indeed, they were precise in their outlook on Big Data analytics. In fact, the continued improvement of the interoperability of machine learning, statistics, database building and querying fused to create this increasingly popular science- Data Mining and Knowledge Discovery. The next generation computational theories are geared towards helping to extract insightful knowledge from even larger volumes of data at higher rates of speed. As the trend increases in popularity, the need for a highly adaptive solution for knowledge discovery will be necessary. In this research paper, we are introducing the investigation and development of 23 bit-questions for a Metaknowledge template for Big Data Processing and clustering purposes. This research aims to demonstrate the construction of this methodology and proves the validity and the beneficial utilization that brings Knowledge Discovery from Big Data.