 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Prompts with English Tools: A Benchmark
Jan 08, 2026Large Language Models (LLMs) are now integral to numerous industries, increasingly serving as the core reasoning engine for autonomous agents that perform complex tasks through tool-use. While the development of Arabic-native LLMs is accelerating, the benchmarks for evaluating their capabilities lag behind, with most existing frameworks focusing on English. A critical and overlooked area is tool-calling, where the performance of models prompted in non-English languages like Arabic is poorly understood, especially since these models are often pretrained on predominantly English data. This paper addresses this critical gap by introducing the first dedicated benchmark for evaluating the tool-calling and agentic capabilities of LLMs in the Arabic language. Our work provides a standardized framework to measure the functional accuracy and robustness of models in Arabic agentic workflows. Our findings reveal a huge performance gap: when users interact in Arabic, tool-calling accuracy drops by an average of 5-10\%, regardless of whether the tool descriptions themselves are in Arabic or English. By shedding light on these critical challenges, this benchmark aims to foster the development of more reliable and linguistically equitable AI agents for Arabic-speaking users.
Construction of FuzzyFind Dictionary using Golay Coding Transformation for Searching Applications
Mar 22, 2015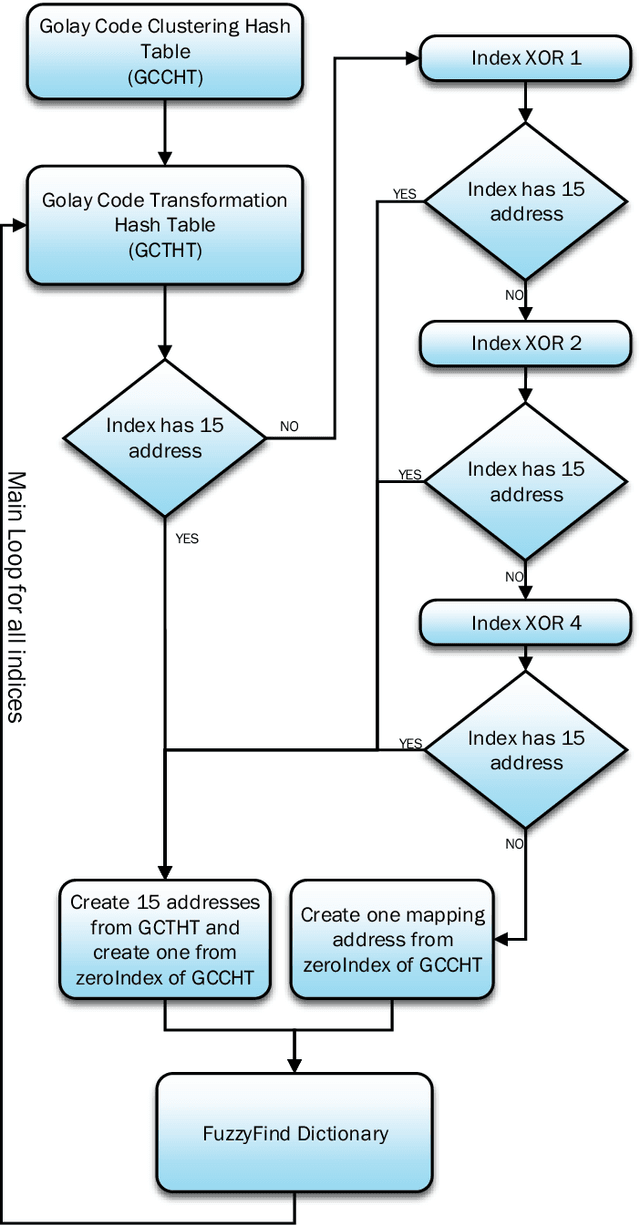
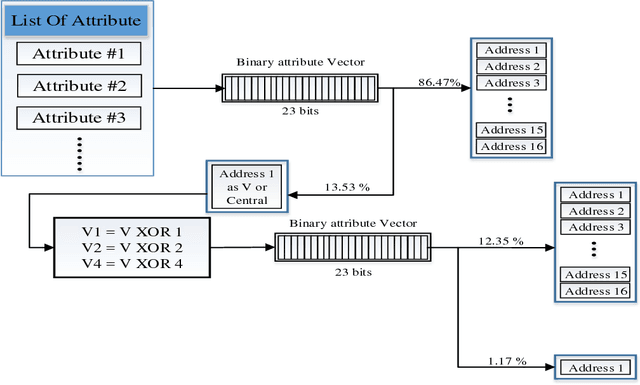

Searching through a large volume of data is very critical for companies, scientists, and searching engines applications due to time complexity and memory complexity. In this paper, a new technique of generating FuzzyFind Dictionary for text mining was introduced. We simply mapped the 23 bits of the English alphabet into a FuzzyFind Dictionary or more than 23 bits by using more FuzzyFind Dictionary, and reflecting the presence or absence of particular letters. This representation preserves closeness of word distortions in terms of closeness of the created binary vectors within Hamming distance of 2 deviations. This paper talks about the Golay Coding Transformation Hash Table and how it can be used on a FuzzyFind Dictionary as a new technology for using in searching through big data. This method is introduced by linear time complexity for generating the dictionary and constant time complexity to access the data and update by new data sets, also updating for new data sets is linear time depends on new data points. This technique is based on searching only for letters of English that each segment has 23 bits, and also we have more than 23-bit and also it could work with more segments as reference table.