 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Step Closer to Ground Truth: A Multi-Scale Residual-Aware Representation Learning Pipeline for Predicting Time Series Data
Jun 09, 2026Transformer-based models have emerged as leading paradigms in time-series forecasting in recent years, employing self-attention mechanisms to capture long-range dependencies. Despite their success, these single-stage forecasting architectures exhibit persistent systematic residual biases arising from structural discrepancies, unmodeled stochastic components, or inadequate multi-scale temporal representations. This limitation persists when residuals are treated as irreducible noise, precluding adaptive correction of structured error patterns. To address this limitation, we introduce a two-stage, model-agnostic framework that explicitly decouples forecasting and residual learning into distinct stages of representation learning. A base transformer first generates the initial predictions. Subsequently, a dedicated meta-corrector dynamically models structured error patterns across multivariate channels, preserves cross-variable dependencies, and iteratively refines the residual bias of the base transformer. By formalizing this pipeline as a hypothesis space expansion, our framework addresses approximation limitations inherent in single-stage architectures, removes reliance on restrictive assumptions, and enables end-to-end learning of complex error dynamics. Evaluated on eight popular benchmark datasets using established protocols, our approach achieves state-of-the-art performance, with significant improvements in standard metrics (MSE, MAE). The results demonstrate the framework's ability to mitigate systematic biases and enhance robustness to complex temporal dynamics, advancing the practical applicability of transformer-based forecasting models.
Beyond Real Weights: Hypercomplex Representations for Stable Quantization
Dec 09, 2025Multimodal language models (MLLMs) require large parameter capacity to align high-dimensional visual features with linguistic representations, making them computationally heavy and difficult to deploy efficiently. We introduce a progressive reparameterization strategy that compresses these models by gradually replacing dense feed-forward network blocks with compact Parameterized Hypercomplex Multiplication (PHM) layers. A residual interpolation schedule, together with lightweight reconstruction and knowledge distillation losses, ensures that the PHM modules inherit the functional behavior of their dense counterparts during training. This transition yields substantial parameter and FLOP reductions while preserving strong multimodal alignment, enabling faster inference without degrading output quality. We evaluate the approach on multiple vision-language models (VLMs). Our method maintains performance comparable to the base models while delivering significant reductions in model size and inference latency. Progressive PHM substitution thus offers an architecture-compatible path toward more efficient multimodal reasoning and complements existing low-bit quantization techniques.
LAET: A Layer-wise Adaptive Ensemble Tuning Framework for Pretrained Language Models
Nov 14, 2025



Natural Language Processing (NLP) has transformed the financial industry, enabling advancements in areas such as textual analysis, risk management, and forecasting. Large language models (LLMs) like BloombergGPT and FinMA have set new benchmarks across various financial NLP tasks, including sentiment analysis, stock movement prediction, and credit risk assessment. Furthermore, FinMA-ES, a bilingual financial LLM, has also demonstrated strong performance using the FLARE and FLARE-ES benchmarks. However, the high computational demands of these models limit the accessibility of many organizations. To address this, we propose Layer-wise Adaptive Ensemble Tuning (LAET), a novel strategy that selectively fine-tunes the most effective layers of pre-trained LLMs by analyzing hidden state representations while freezing less critical layers. LAET significantly reduces computational overhead while enhancing task-specific performance. Our approach shows strong results in financial NLP tasks, outperforming existing benchmarks and state-of-the-art LLMs such as GPT-4, even with smaller LLMs ($\sim$3B parameters). This work bridges cutting-edge financial NLP research and real-world deployment with efficient and scalable models for financial applications.
LegalRAG: A Hybrid RAG System for Multilingual Legal Information Retrieval
Apr 19, 2025Natural Language Processing (NLP) and computational linguistic techniques are increasingly being applied across various domains, yet their use in legal and regulatory tasks remains limited. To address this gap, we develop an efficient bilingual question-answering framework for regulatory documents, specifically the Bangladesh Police Gazettes, which contain both English and Bangla text. Our approach employs modern Retrieval Augmented Generation (RAG) pipelines to enhance information retrieval and response generation. In addition to conventional RAG pipelines, we propose an advanced RAG-based approach that improves retrieval performance, leading to more precise answers. This system enables efficient searching for specific government legal notices, making legal information more accessible. We evaluate both our proposed and conventional RAG systems on a diverse test set on Bangladesh Police Gazettes, demonstrating that our approach consistently outperforms existing methods across all evaluation metrics.
Chittron: An Automatic Bangla Image Captioning System
Sep 02, 2018

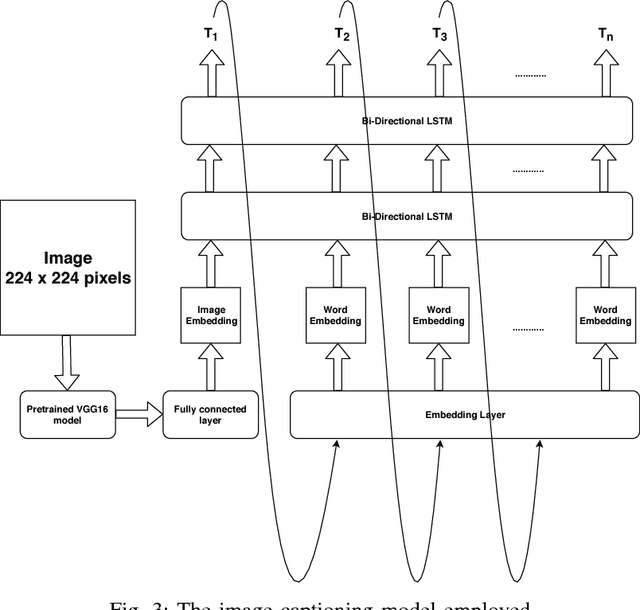

Automatic image caption generation aims to produce an accurate description of an image in natural language automatically. However, Bangla, the fifth most widely spoken language in the world, is lagging considerably in the research and development of such domain. Besides, while there are many established data sets to related to image annotation in English, no such resource exists for Bangla yet. Hence, this paper outlines the development of "Chittron", an automatic image captioning system in Bangla. Moreover, to address the data set availability issue, a collection of 16,000 Bangladeshi contextual images has been accumulated and manually annotated in Bangla. This data set is then used to train a model which integrates a pre-trained VGG16 image embedding model with stacked LSTM layers. The model is trained to predict the caption when the input is an image, one word at a time. The results show that the model has successfully been able to learn a working language model and to generate captions of images quite accurately in many cases. The results are evaluated mainly qualitatively. However, BLEU scores are also reported. It is expected that a better result can be obtained with a bigger and more varied data set.
BanglaLekha-Isolated: A Comprehensive Bangla Handwritten Character Dataset
Feb 22, 2017


Bangla handwriting recognition is becoming a very important issue nowadays. It is potentially a very important task specially for Bangla speaking population of Bangladesh and West Bengal. By keeping that in our mind we are introducing a comprehensive Bangla handwritten character dataset named BanglaLekha-Isolated. This dataset contains Bangla handwritten numerals, basic characters and compound characters. This dataset was collected from multiple geographical location within Bangladesh and includes sample collected from a variety of aged groups. This dataset can also be used for other classification problems i.e: gender, age, district. This is the largest dataset on Bangla handwritten characters yet.