 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Infused Binaural Audio Generation using Hierarchical Cross-Modal Attention
Aug 10, 2021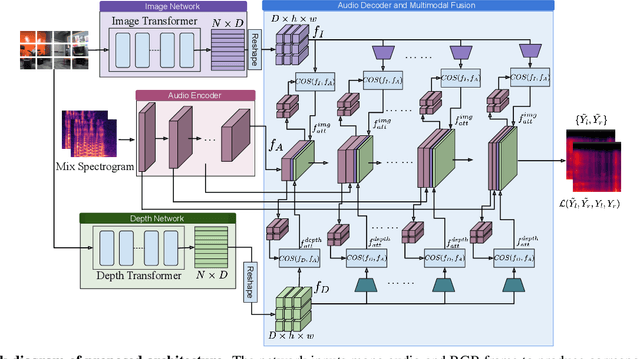
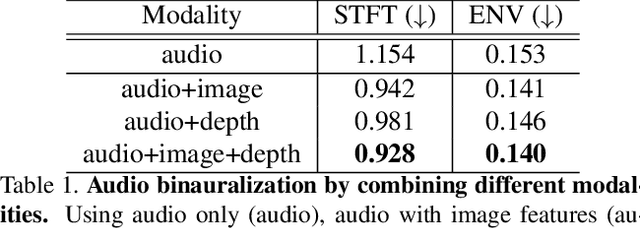
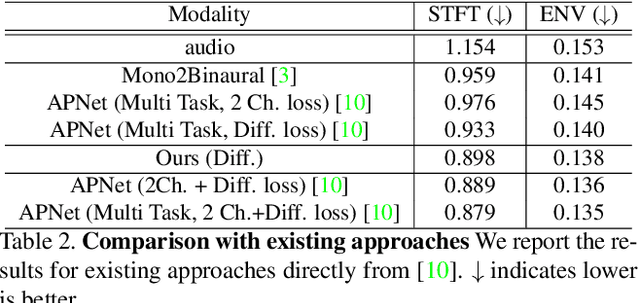

Binaural audio gives the listener the feeling of being in the recording place and enhances the immersive experience if coupled with AR/VR. But the problem with binaural audio recording is that it requires a specialized setup which is not possible to fabricate within handheld devices as compared to traditional mono audio that can be recorded with a single microphone. In order to overcome this drawback, prior works have tried to uplift the mono recorded audio to binaural audio as a post processing step conditioning on the visual input. But all the prior approaches missed other most important information required for the task, i.e. distance of different sound producing objects from the recording setup. In this work, we argue that the depth map of the scene can act as a proxy for encoding distance information of objects in the scene and show that adding depth features along with image features improves the performance both qualitatively and quantitatively. We propose a novel encoder-decoder architecture, where we use a hierarchical attention mechanism to encode the image and depth feature extracted from individual transformer backbone, with audio features at each layer of the decoder.
Learning User-Interpretable Descriptions of Black-Box AI System Capabilities
Jul 28, 2021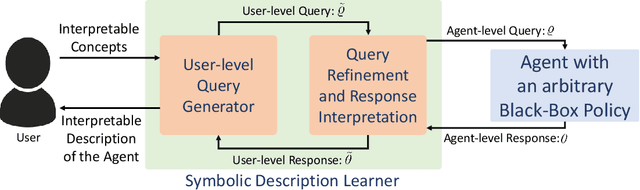


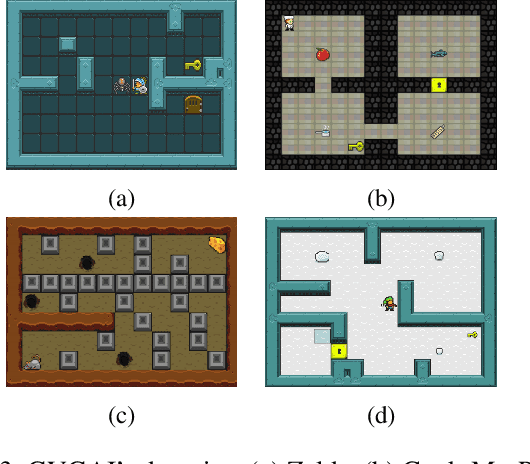
Several approaches have been developed to answer specific questions that a user may have about an AI system that can plan and act. However, the problems of identifying which questions to ask and that of computing a user-interpretable symbolic description of the overall capabilities of the system have remained largely unaddressed. This paper presents an approach for addressing these problems by learning user-interpretable symbolic descriptions of the limits and capabilities of a black-box AI system using low-level simulators. It uses a hierarchical active querying paradigm to generate questions and to learn a user-interpretable model of the AI system based on its responses. In contrast to prior work, we consider settings where imprecision of the user's conceptual vocabulary precludes a direct expression of the agent's capabilities. Furthermore, our approach does not require assumptions about the internal design of the target AI system or about the methods that it may use to compute or learn task solutions. Empirical evaluation on several game-based simulator domains shows that this approach can efficiently learn symbolic models of AI systems that use a deterministic black-box policy in fully observable scenarios.
Planning for Proactive Assistance in Environments with Partial Observability
May 02, 2021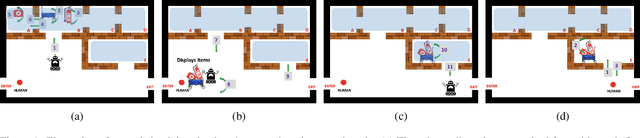
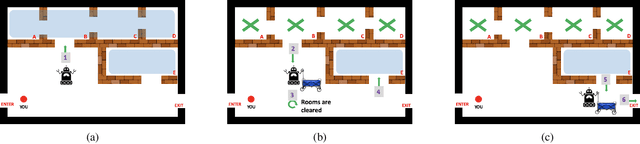
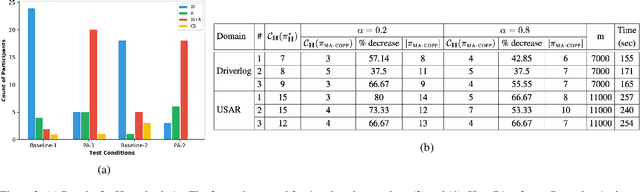
This paper addresses the problem of synthesizing the behavior of an AI agent that provides proactive task assistance to a human in settings like factory floors where they may coexist in a common environment. Unlike in the case of requested assistance, the human may not be expecting proactive assistance and hence it is crucial for the agent to ensure that the human is aware of how the assistance affects her task. This becomes harder when there is a possibility that the human may neither have full knowledge of the AI agent's capabilities nor have full observability of its activities. Therefore, our \textit{proactive assistant} is guided by the following three principles: \textbf{(1)} its activity decreases the human's cost towards her goal; \textbf{(2)} the human is able to recognize the potential reduction in her cost; \textbf{(3)} its activity optimizes the human's overall cost (time/resources) of achieving her goal. Through empirical evaluation and user studies, we demonstrate the usefulness of our approach.
Beyond Image to Depth: Improving Depth Prediction using Echoes
Apr 03, 2021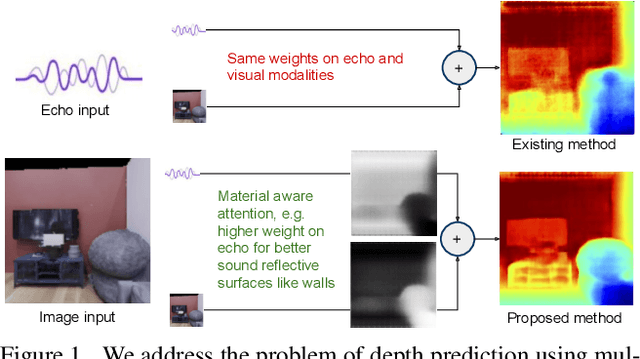
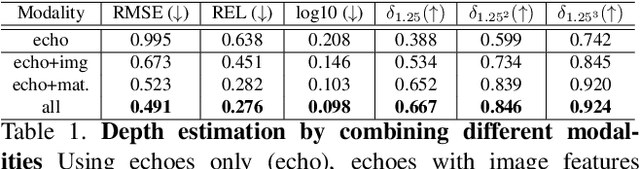
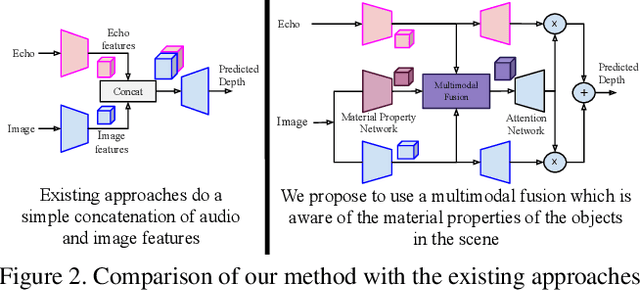
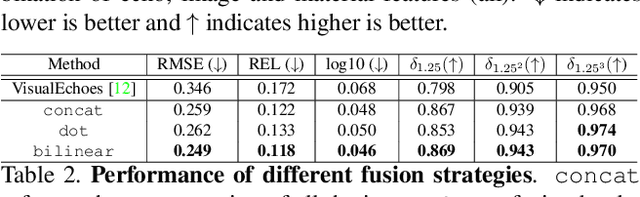
We address the problem of estimating depth with multi modal audio visual data. Inspired by the ability of animals, such as bats and dolphins, to infer distance of objects with echolocation, some recent methods have utilized echoes for depth estimation. We propose an end-to-end deep learning based pipeline utilizing RGB images, binaural echoes and estimated material properties of various objects within a scene. We argue that the relation between image, echoes and depth, for different scene elements, is greatly influenced by the properties of those elements, and a method designed to leverage this information can lead to significantly improved depth estimation from audio visual inputs. We propose a novel multi modal fusion technique, which incorporates the material properties explicitly while combining audio (echoes) and visual modalities to predict the scene depth. We show empirically, with experiments on Replica dataset, that the proposed method obtains 28% improvement in RMSE compared to the state-of-the-art audio-visual depth prediction method. To demonstrate the effectiveness of our method on larger dataset, we report competitive performance on Matterport3D, proposing to use it as a multimodal depth prediction benchmark with echoes for the first time. We also analyse the proposed method with exhaustive ablation experiments and qualitative results. The code and models are available at https://krantiparida.github.io/projects/bimgdepth.html
Exploiting Local Geometry for Feature and Graph Construction for Better 3D Point Cloud Processing with Graph Neural Networks
Mar 28, 2021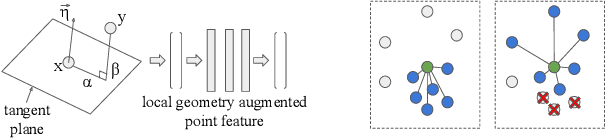
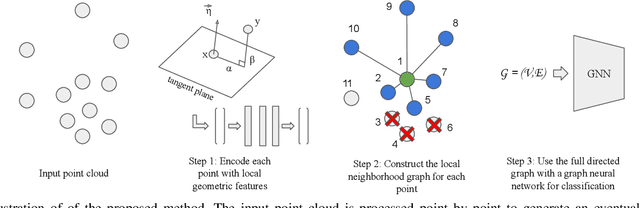
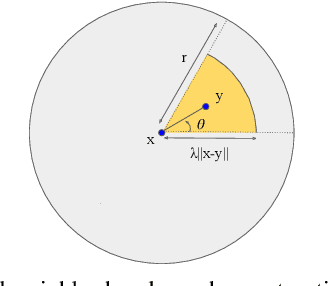
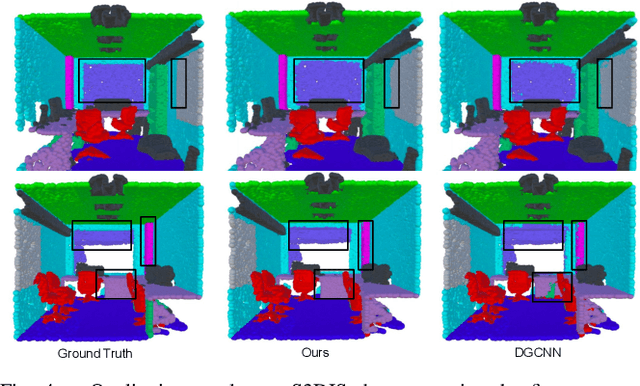
We propose simple yet effective improvements in point representations and local neighborhood graph construction within the general framework of graph neural networks (GNNs) for 3D point cloud processing. As a first contribution, we propose to augment the vertex representations with important local geometric information of the points, followed by nonlinear projection using a MLP. As a second contribution, we propose to improve the graph construction for GNNs for 3D point clouds. The existing methods work with a k-nn based approach for constructing the local neighborhood graph. We argue that it might lead to reduction in coverage in case of dense sampling by sensors in some regions of the scene. The proposed methods aims to counter such problems and improve coverage in such cases. As the traditional GNNs were designed to work with general graphs, where vertices may have no geometric interpretations, we see both our proposals as augmenting the general graphs to incorporate the geometric nature of 3D point clouds. While being simple, we demonstrate with multiple challenging benchmarks, with relatively clean CAD models, as well as with real world noisy scans, that the proposed method achieves state of the art results on benchmarks for 3D classification (ModelNet40) , part segmentation (ShapeNet) and semantic segmentation (Stanford 3D Indoor Scenes Dataset). We also show that the proposed network achieves faster training convergence, i.e. ~40% less epochs for classification. The project details are available at https://siddharthsrivastava.github.io/publication/geomgcnn/
Learning Sampling Distributions for Efficient High-Dimensional Motion Planning
Dec 01, 2020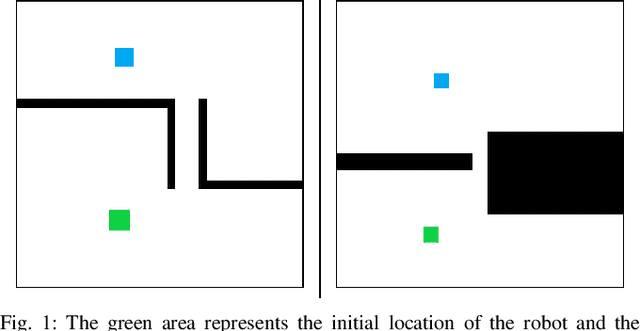
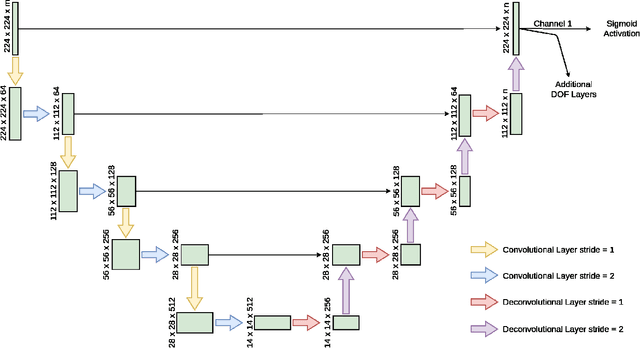


Robot motion planning involves computing a sequence of valid robot configurations that take the robot from its initial state to a goal state. Solving a motion planning problem optimally using analytical methods is proven to be PSPACE-Hard. Sampling-based approaches have tried to approximate the optimal solution efficiently. Generally, sampling-based planners use uniform samplers to cover the entire state space. In this paper, we propose a deep-learning-based framework that identifies robot configurations in the environment that are important to solve the given motion planning problem. These states are used to bias the sampling distribution in order to reduce the planning time. Our approach works with a unified network and generates domain-dependent network parameters based on the environment and the robot. We evaluate our approach with Learn and Link planner in three different settings. Results show significant improvement in motion planning times when compared with current sampling-based motion planners.
Learning Generalized Relational Heuristic Networks for Model-Agnostic Planning
Jul 10, 2020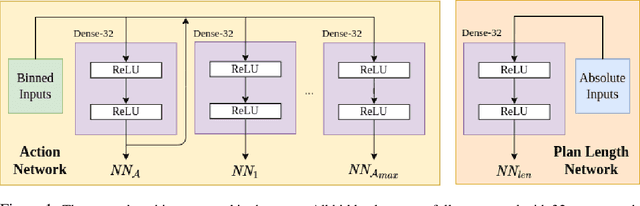
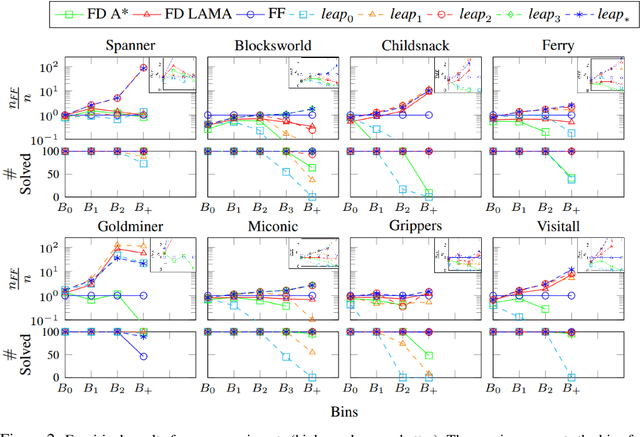
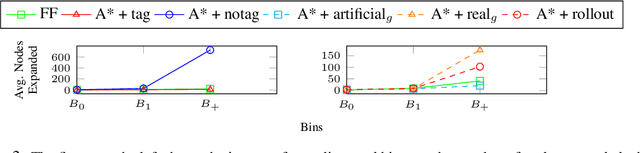
Computing goal-directed behavior (sequential decision-making, or planning) is essential to designing efficient AI systems. Due to the computational complexity of planning, current approaches rely primarily upon hand-coded symbolic domain models and hand-coded heuristic-function generators for efficiency. Learned heuristics for such problems have been of limited utility as they are difficult to apply to problems with objects and object quantities that are significantly different from those in the training data. This paper develops a new approach for learning generalized heuristics in the absence of symbolic domain models using deep neural networks that utilize an input predicate vocabulary but are agnostic to object names and quantities. It uses an abstract state representation to facilitate data efficient, generalizable learning. Empirical evaluation on a range of benchmark domains show that in contrast to prior approaches, generalized heuristics computed by this method can be transferred easily to problems with different objects and with object quantities much larger than those in the training data.
Learning Generalized Models by Interrogating Black-Box Autonomous Agents
Feb 06, 2020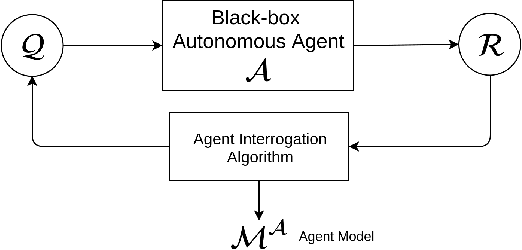
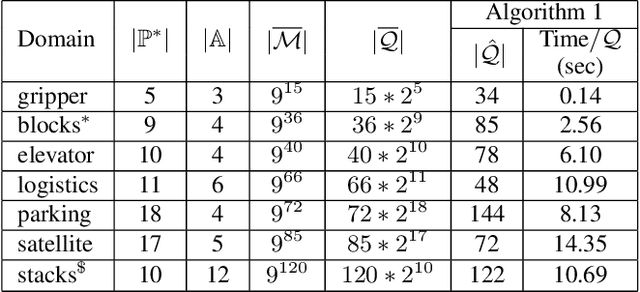

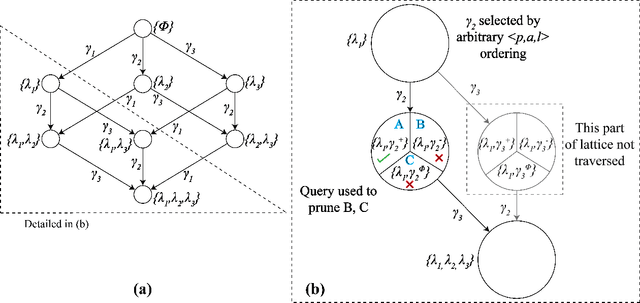
This paper develops a new approach for estimating a relational model of a non-stationary black-box autonomous agent that can plan and act. In this approach, the user may ask an autonomous agent a series of questions, which the agent answers truthfully. Our main contribution is an algorithm that generates an interrogation policy in the form of a contingent sequence of questions to be posed to the agent. Answers to these questions are used to derive a minimal, functionally indistinguishable class of agent models. This approach requires a minimal query-answering capability from the agent. Empirical evaluation of our approach shows that despite the intractable space of possible models, our approach allows correct and scalable estimation of relational STRIPS-like agent models for a class of black-box autonomous agents.
Bridging the Gap: Providing Post-Hoc Symbolic Explanations for Sequential Decision-Making Problems with Black Box Simulators
Feb 04, 2020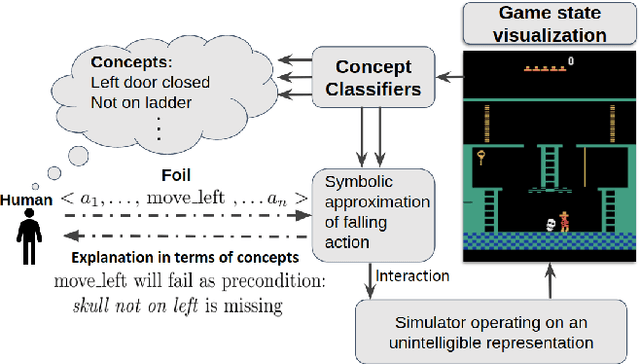
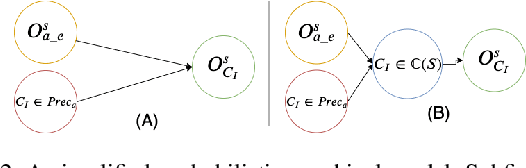
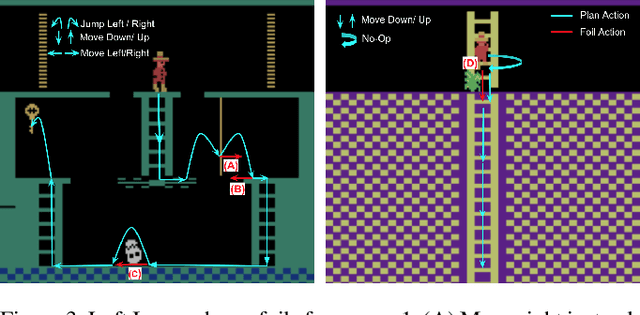
As more and more complex AI systems are introduced into our day-to-day lives, it becomes important that everyday users can work and interact with such systems with relative ease. Orchestrating such interactions require the system to be capable of providing explanations and rationale for its decisions and be able to field queries about alternative decisions. A significant hurdle to allowing for such explanatory dialogue could be the mismatch between the complex representations that the systems use to reason about the task and the terms in which the user may be viewing the task. This paper introduces methods that can be leveraged to provide contrastive explanations in terms of user-specified concepts for deterministic sequential decision-making settings where the system dynamics may be best represented in terms of black box simulators. We do this by assuming that system dynamics can at least be partly captured in terms of symbolic planning models, and we provide explanations in terms of these models. We implement this method using a simulator for a popular Atari game (Montezuma's Revenge) and perform user studies to verify whether people would find explanations generated in this form useful.
Balancing Goal Obfuscation and Goal Legibility in Settings with Cooperative and Adversarial Observers
May 25, 2019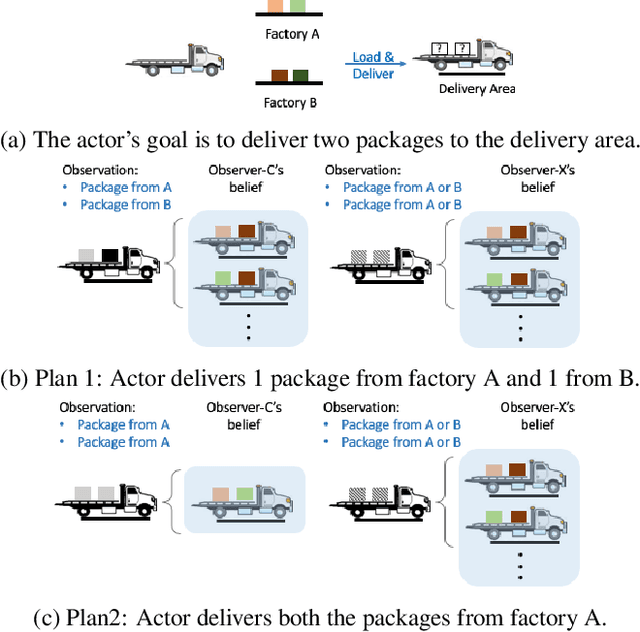
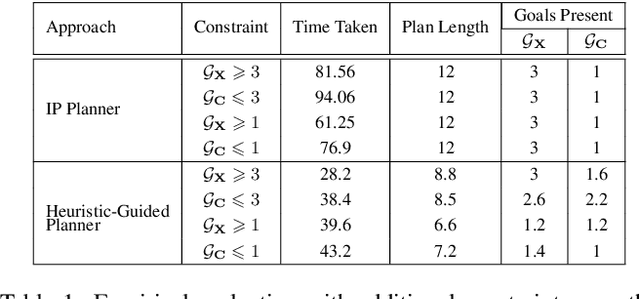
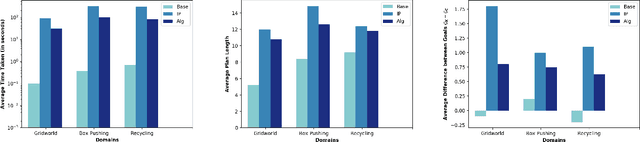
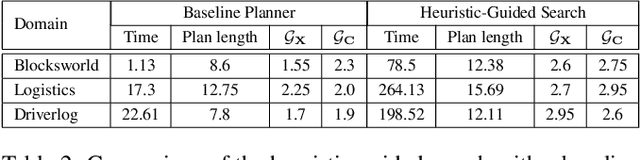
In order to be useful in the real world, AI agents need to plan and act in the presence of others, who may include adversarial and cooperative entities. In this paper, we consider the problem where an autonomous agent needs to act in a manner that clarifies its objectives to cooperative entities while preventing adversarial entities from inferring those objectives. We show that this problem is solvable when cooperative entities and adversarial entities use different types of sensors and/or prior knowledge. We develop two new solution approaches for computing such plans. One approach provides an optimal solution to the problem by using an IP solver to provide maximum obfuscation for adversarial entities while providing maximum legibility for cooperative entities in the environment, whereas the other approach provides a satisficing solution using heuristic-guided forward search to achieve preset levels of obfuscation and legibility for adversarial and cooperative entities respectively. We show the feasibility and utility of our algorithms through extensive empirical evaluation on problems derived from planning benchmarks.