 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Option Learning and Discovery for Stochastic Path Planning
Sep 30, 2022
This paper addresses the problem of reliably and efficiently solving broad classes of long-horizon stochastic path planning problems. Starting with a vanilla RL formulation with a stochastic dynamics simulator and an occupancy matrix of the environment, our approach computes useful options with policies as well as high-level paths that compose the discovered options. Our main contributions are (1) data-driven methods for creating abstract states that serve as endpoints for helpful options, (2) methods for computing option policies using auto-generated option guides in the form of dense pseudo-reward functions, and (3) an overarching algorithm for composing the computed options. We show that this approach yields strong guarantees of executability and solvability: under fairly general conditions, the computed option guides lead to composable option policies and consequently ensure downward refinability. Empirical evaluation on a range of robots, environments, and tasks shows that this approach effectively transfers knowledge across related tasks and that it outperforms existing approaches by a significant margin.
Relational Abstractions for Generalized Reinforcement Learning on Symbolic Problems
Apr 27, 2022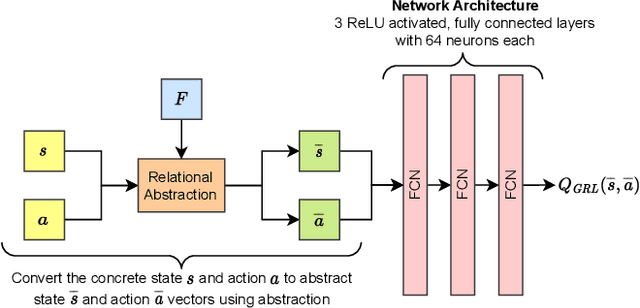
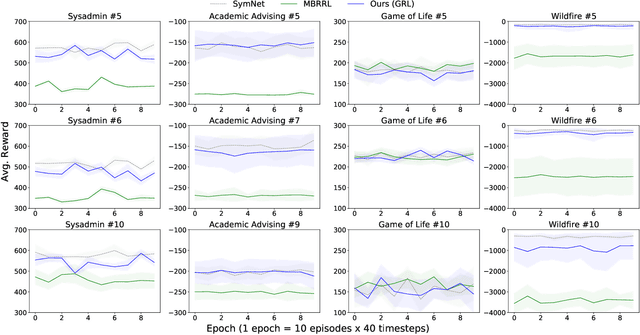
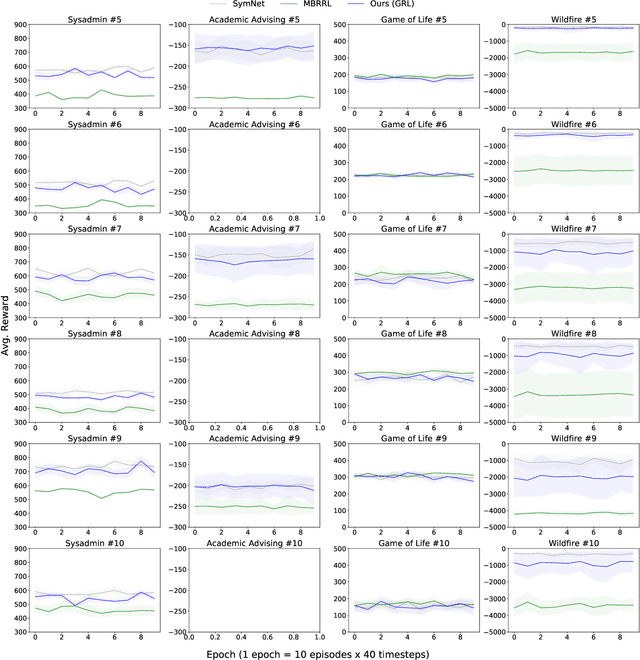
Reinforcement learning in problems with symbolic state spaces is challenging due to the need for reasoning over long horizons. This paper presents a new approach that utilizes relational abstractions in conjunction with deep learning to learn a generalizable Q-function for such problems. The learned Q-function can be efficiently transferred to related problems that have different object names and object quantities, and thus, entirely different state spaces. We show that the learned generalized Q-function can be utilized for zero-shot transfer to related problems without an explicit, hand-coded curriculum. Empirical evaluations on a range of problems show that our method facilitates efficient zero-shot transfer of learned knowledge to much larger problem instances containing many objects.
Preliminary Results on Using Abstract AND-OR Graphs for Generalized Solving of Stochastic Shortest Path Problems
Apr 08, 2022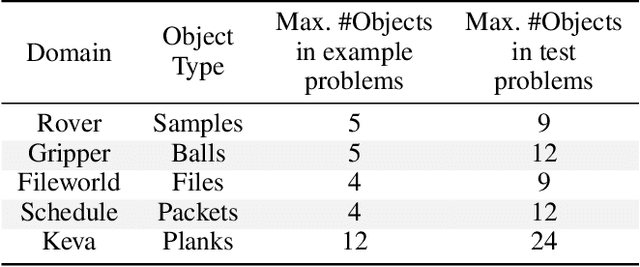
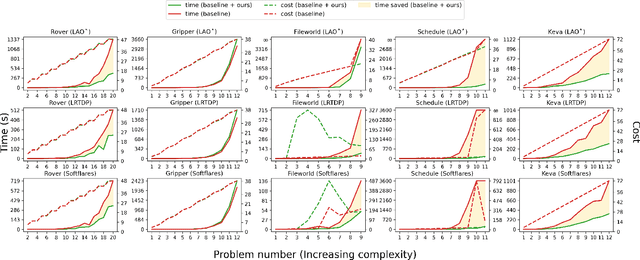
Several goal-oriented problems in the real-world can be naturally expressed as Stochastic Shortest Path Problems (SSPs). However, a key difficulty for computing solutions for problems in the SSP framework is that the computational requirements often make finding solutions to even moderately sized problems intractable. Solutions to many of such problems can often be expressed as generalized policies that are quite easy to compute from small examples and are readily applicable to problems with a larger number of objects and/or different object names. In this paper, we provide a preliminary study on using canonical abstractions to compute such generalized policies and represent them as AND-OR graphs that translate to simple non-deterministic, memoryless controllers. Such policy structures naturally lend themselves to a hierarchical approach for solving problems and we show that our approach can be embedded in any SSP solver to compute hierarchically optimal policies. We conducted an empirical evaluation on some well-known planning benchmarks and difficult robotics domains and show that our approach is promising, often computing optimal policies significantly faster than state-of-art SSP solvers.
Differential Assessment of Black-Box AI Agents
Mar 24, 2022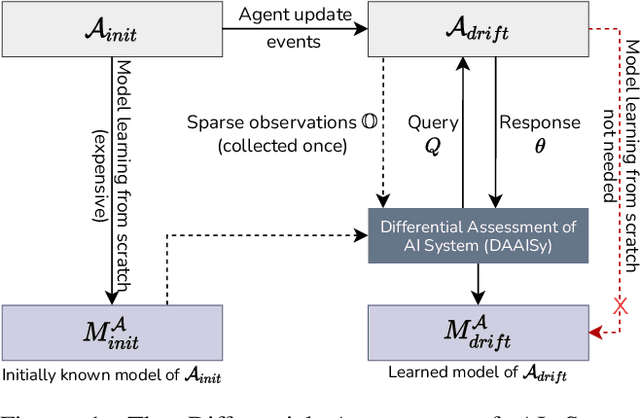


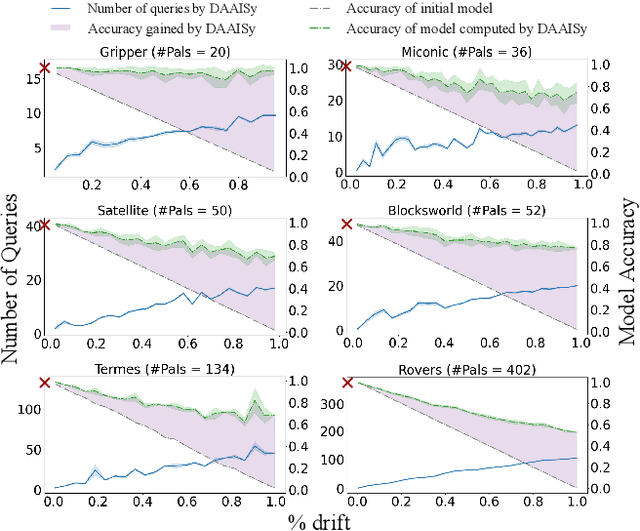
Much of the research on learning symbolic models of AI agents focuses on agents with stationary models. This assumption fails to hold in settings where the agent's capabilities may change as a result of learning, adaptation, or other post-deployment modifications. Efficient assessment of agents in such settings is critical for learning the true capabilities of an AI system and for ensuring its safe usage. In this work, we propose a novel approach to differentially assess black-box AI agents that have drifted from their previously known models. As a starting point, we consider the fully observable and deterministic setting. We leverage sparse observations of the drifted agent's current behavior and knowledge of its initial model to generate an active querying policy that selectively queries the agent and computes an updated model of its functionality. Empirical evaluation shows that our approach is much more efficient than re-learning the agent model from scratch. We also show that the cost of differential assessment using our method is proportional to the amount of drift in the agent's functionality.
Using Deep Learning to Bootstrap Abstractions for Hierarchical Robot Planning
Feb 11, 2022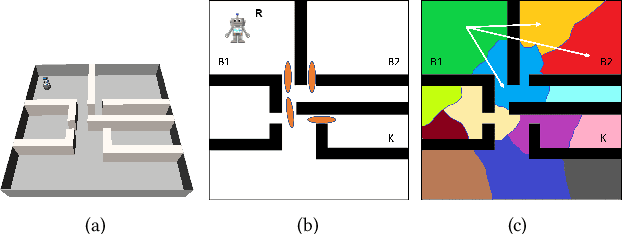
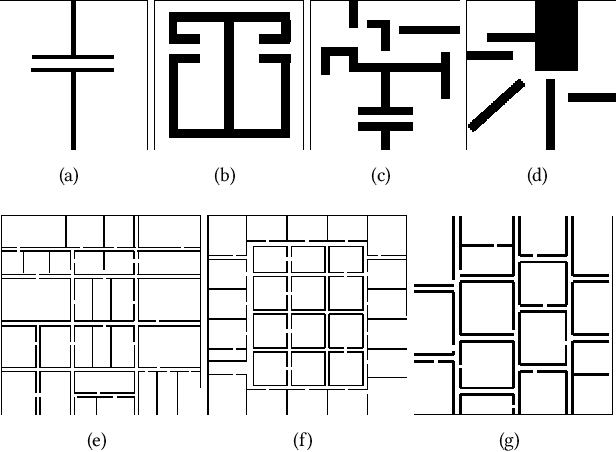
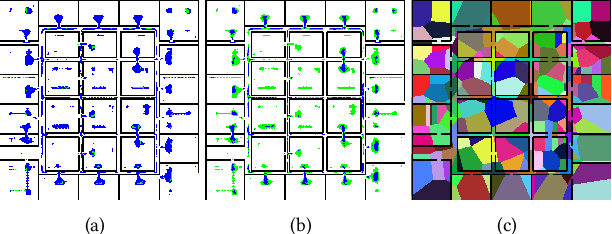
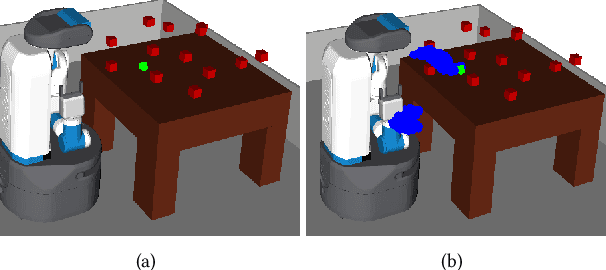
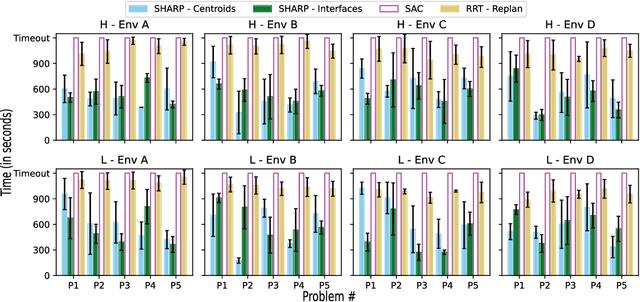
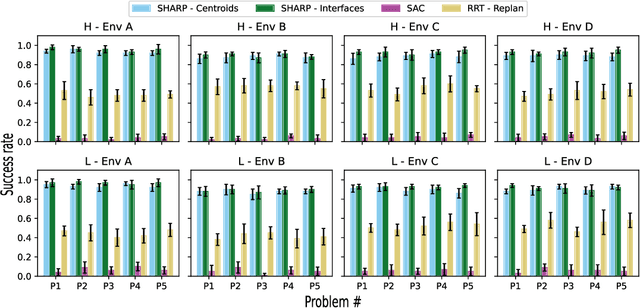
This paper addresses the problem of learning abstractions that boost robot planning performance while providing strong guarantees of reliability. Although state-of-the-art hierarchical robot planning algorithms allow robots to efficiently compute long-horizon motion plans for achieving user desired tasks, these methods typically rely upon environment-dependent state and action abstractions that need to be hand-designed by experts. We present a new approach for bootstrapping the entire hierarchical planning process. This allows us to compute abstract states and actions for new environments automatically using the critical regions predicted by a deep neural network with an auto-generated robot-specific architecture. We show that the learned abstractions can be used with a novel multi-source bi-directional hierarchical robot planning algorithm that is sound and probabilistically complete. An extensive empirical evaluation on twenty different settings using holonomic and non-holonomic robots shows that (a) our learned abstractions provide the information necessary for efficient multi-source hierarchical planning; and that (b) this approach of learning, abstractions, and planning outperforms state-of-the-art baselines by nearly a factor of ten in terms of planning time on test environments not seen during training.
Beyond Mono to Binaural: Generating Binaural Audio from Mono Audio with Depth and Cross Modal Attention
Nov 15, 2021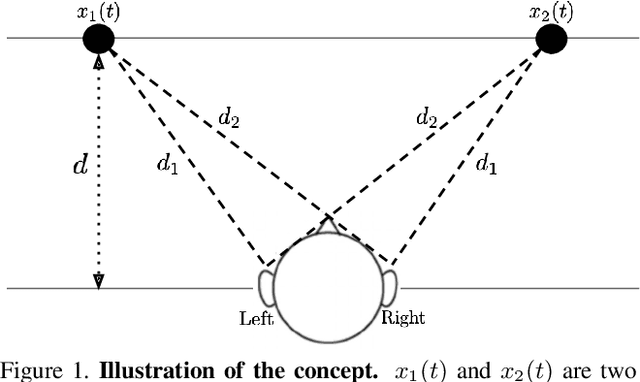
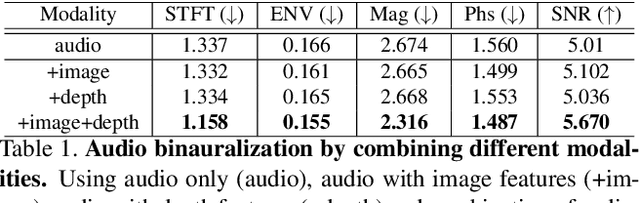
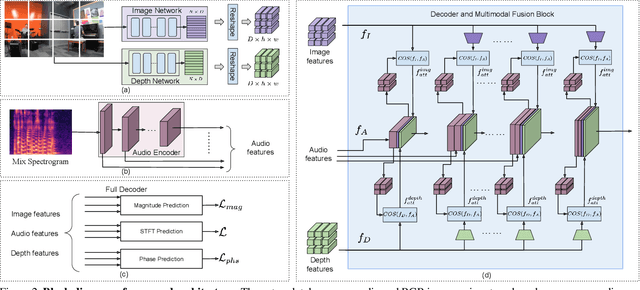
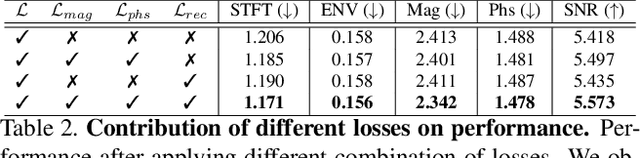
Binaural audio gives the listener an immersive experience and can enhance augmented and virtual reality. However, recording binaural audio requires specialized setup with a dummy human head having microphones in left and right ears. Such a recording setup is difficult to build and setup, therefore mono audio has become the preferred choice in common devices. To obtain the same impact as binaural audio, recent efforts have been directed towards lifting mono audio to binaural audio conditioned on the visual input from the scene. Such approaches have not used an important cue for the task: the distance of different sound producing objects from the microphones. In this work, we argue that depth map of the scene can act as a proxy for inducing distance information of different objects in the scene, for the task of audio binauralization. We propose a novel encoder-decoder architecture with a hierarchical attention mechanism to encode image, depth and audio feature jointly. We design the network on top of state-of-the-art transformer networks for image and depth representation. We show empirically that the proposed method outperforms state-of-the-art methods comfortably for two challenging public datasets FAIR-Play and MUSIC-Stereo. We also demonstrate with qualitative results that the method is able to focus on the right information required for the task. The project details are available at \url{https://krantiparida.github.io/projects/bmonobinaural.html}
JEDAI Explains Decision-Making AI
Oct 31, 2021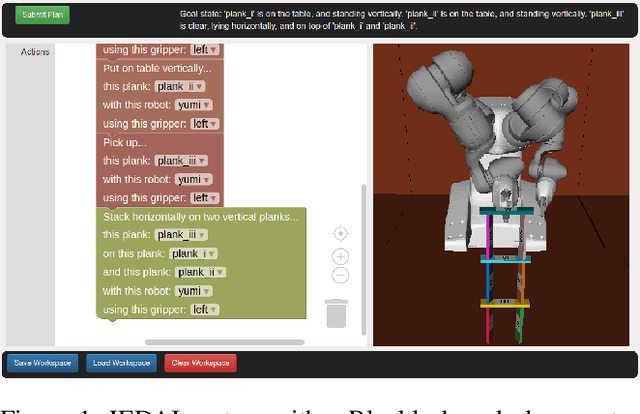
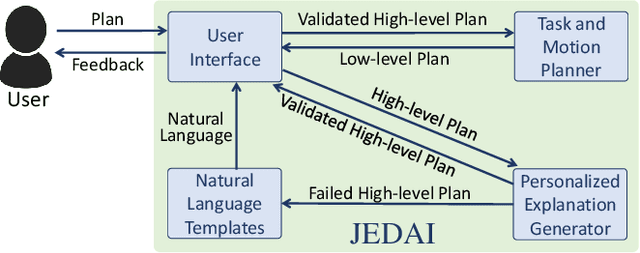
This paper presents JEDAI, an AI system designed for outreach and educational efforts aimed at non-AI experts. JEDAI features a novel synthesis of research ideas from integrated task and motion planning and explainable AI. JEDAI helps users create high-level, intuitive plans while ensuring that they will be executable by the robot. It also provides users customized explanations about errors and helps improve their understanding of AI planning as well as the limits and capabilities of the underlying robot system.
Joint Communication and Motion Planning for Cobots
Sep 28, 2021
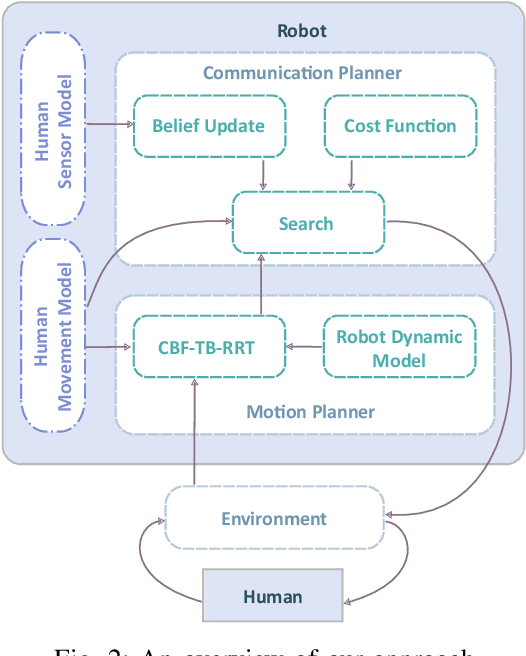
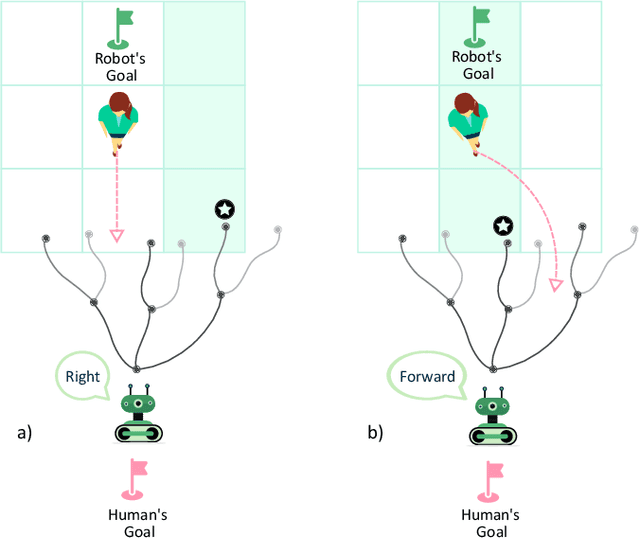
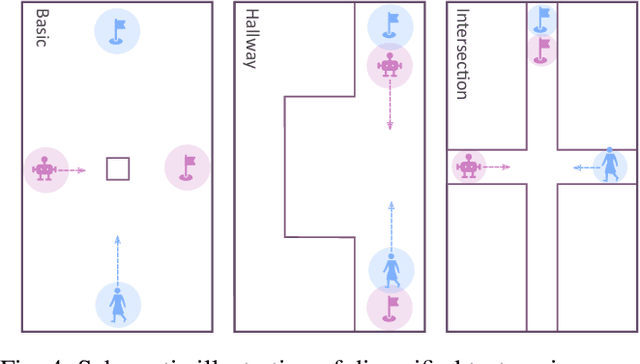
The increasing deployment of robots in co-working scenarios with humans has revealed complex safety and efficiency challenges in the computation robot behavior. Movement among humans is one of the most fundamental -- and yet critical -- problems in this frontier. While several approaches have addressed this problem from a purely navigational point of view, the absence of a unified paradigm for communicating with humans limits their ability to prevent deadlocks and compute feasible solutions. This paper presents a joint communication and motion planning framework that selects from an arbitrary input set of robot's communication signals while computing robot motion plans. It models a human co-worker's imperfect perception of these communications using a noisy sensor model and facilitates the specification of a variety of social/workplace compliance priorities with a flexible cost function. Theoretical results and simulator-based empirical evaluations show that our approach efficiently computes motion plans and communication strategies that reduce conflicts between agents and resolve potential deadlocks.
Anytime Stochastic Task and Motion Policies
Aug 28, 2021
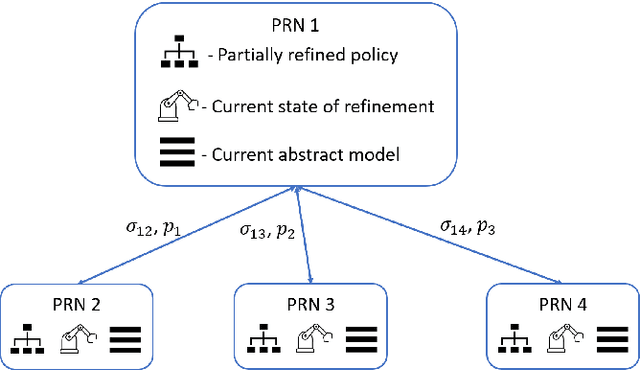

In order to solve complex, long-horizon tasks, intelligent robots need to carry out high-level, abstract planning and reasoning in conjunction with motion planning. However, abstract models are typically lossy and plans or policies computed using them can be inexecutable. These problems are exacerbated in stochastic situations where the robot needs to reason about and plan for multiple contingencies. We present a new approach for integrated task and motion planning in stochastic settings. In contrast to prior work in this direction, we show that our approach can effectively compute integrated task and motion policies whose branching structures encode agent behaviors that handle multiple execution-time contingencies. We prove that our algorithm is probabilistically complete and can compute feasible solution policies in an anytime fashion so that the probability of encountering an unresolved contingency decreases over time. Empirical results on a set of challenging problems show the utility and scope of our method.
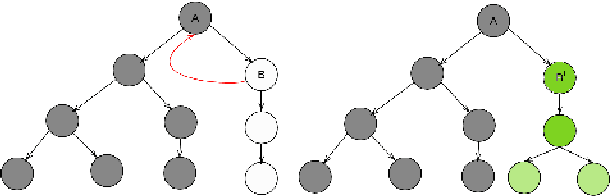
Learning Causal Models of Autonomous Agents using Interventions
Aug 21, 2021
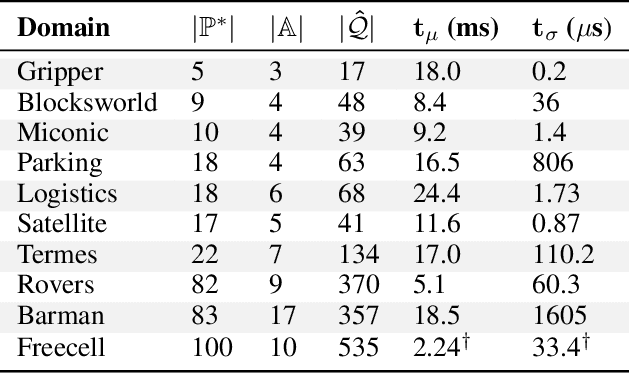
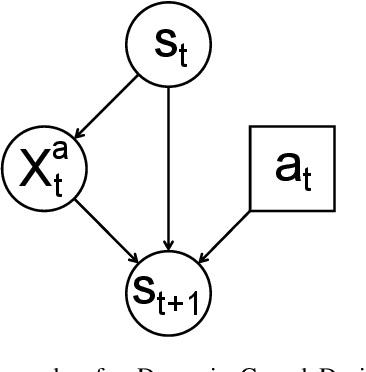
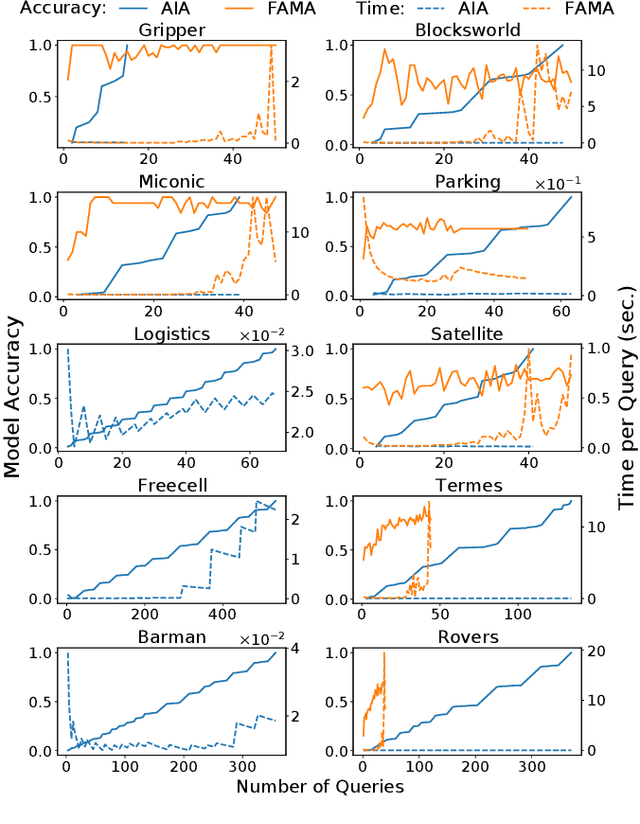
One of the several obstacles in the widespread use of AI systems is the lack of requirements of interpretability that can enable a layperson to ensure the safe and reliable behavior of such systems. We extend the analysis of an agent assessment module that lets an AI system execute high-level instruction sequences in simulators and answer the user queries about its execution of sequences of actions. We show that such a primitive query-response capability is sufficient to efficiently derive a user-interpretable causal model of the system in stationary, fully observable, and deterministic settings. We also introduce dynamic causal decision networks (DCDNs) that capture the causal structure of STRIPS-like domains. A comparative analysis of different classes of queries is also presented in terms of the computational requirements needed to answer them and the efforts required to evaluate their responses to learn the correct model.