 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Genotypes with Neural Networks
Apr 14, 2016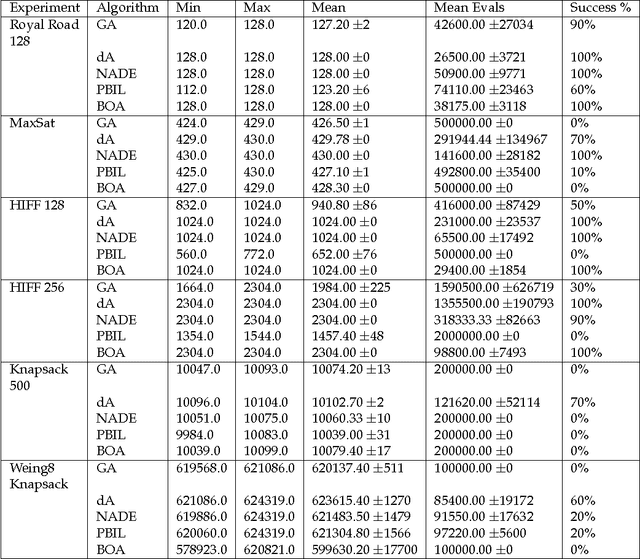
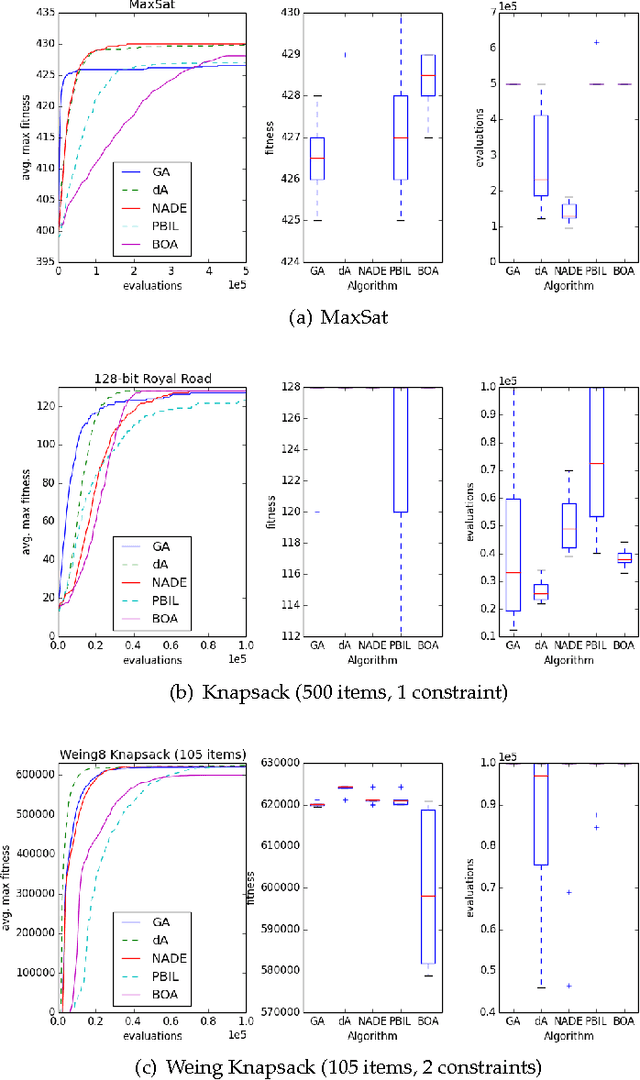
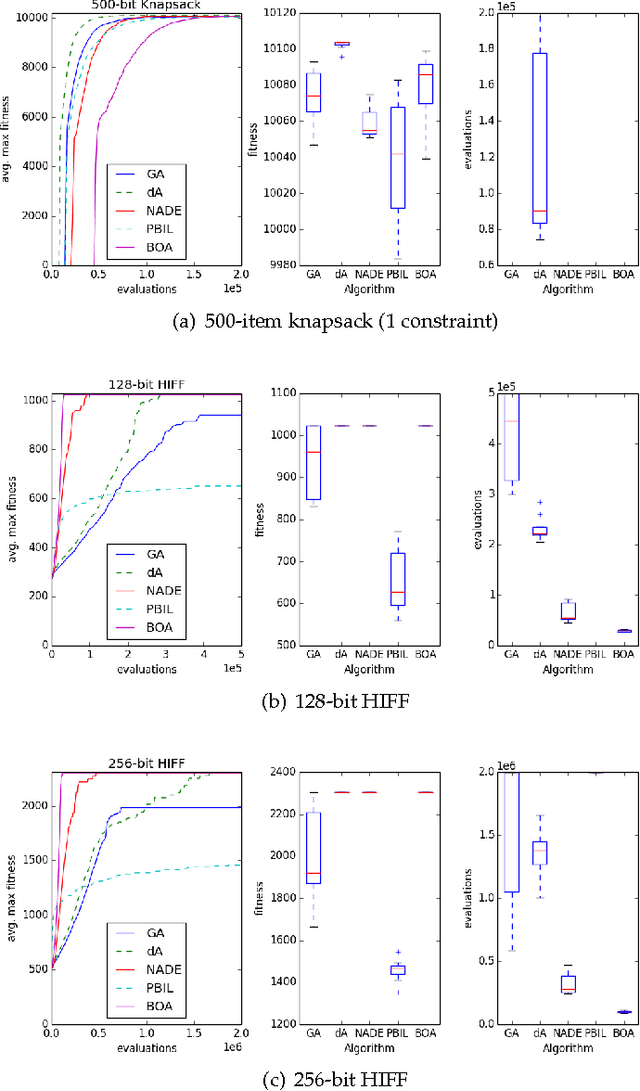
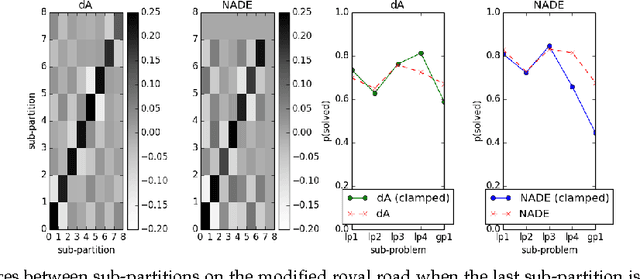
Neural networks and evolutionary computation have a rich intertwined history. They most commonly appear together when an evolutionary algorithm optimises the parameters and topology of a neural network for reinforcement learning problems, or when a neural network is applied as a surrogate fitness function to aid the evolutionary optimisation of expensive fitness functions. In this paper we take a different approach, asking the question of whether a neural network can be used to provide a mutation distribution for an evolutionary algorithm, and what advantages this approach may offer? Two modern neural network models are investigated, a Denoising Autoencoder modified to produce stochastic outputs and the Neural Autoregressive Distribution Estimator. Results show that the neural network approach to learning genotypes is able to solve many difficult discrete problems, such as MaxSat and HIFF, and regularly outperforms other evolutionary techniques.
An End-to-End Neural Network for Polyphonic Piano Music Transcription
Feb 11, 2016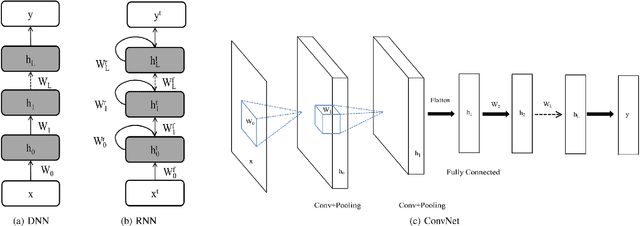
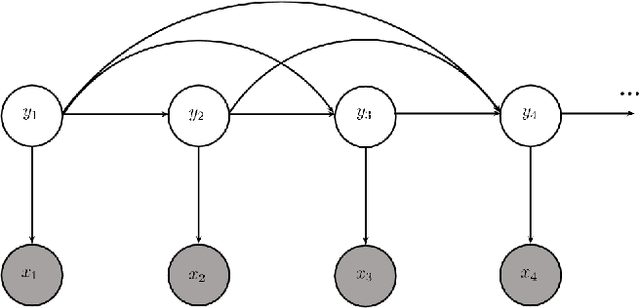

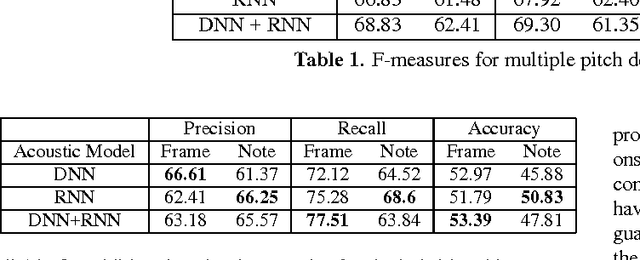
We present a supervised neural network model for polyphonic piano music transcription. The architecture of the proposed model is analogous to speech recognition systems and comprises an acoustic model and a music language model. The acoustic model is a neural network used for estimating the probabilities of pitches in a frame of audio. The language model is a recurrent neural network that models the correlations between pitch combinations over time. The proposed model is general and can be used to transcribe polyphonic music without imposing any constraints on the polyphony. The acoustic and language model predictions are combined using a probabilistic graphical model. Inference over the output variables is performed using the beam search algorithm. We perform two sets of experiments. We investigate various neural network architectures for the acoustic models and also investigate the effect of combining acoustic and music language model predictions using the proposed architecture. We compare performance of the neural network based acoustic models with two popular unsupervised acoustic models. Results show that convolutional neural network acoustic models yields the best performance across all evaluation metrics. We also observe improved performance with the application of the music language models. Finally, we present an efficient variant of beam search that improves performance and reduces run-times by an order of magnitude, making the model suitable for real-time applications.
A Hybrid Recurrent Neural Network For Music Transcription
Nov 06, 2014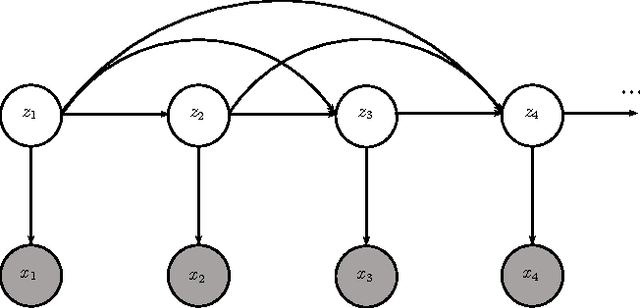

We investigate the problem of incorporating higher-level symbolic score-like information into Automatic Music Transcription (AMT) systems to improve their performance. We use recurrent neural networks (RNNs) and their variants as music language models (MLMs) and present a generative architecture for combining these models with predictions from a frame level acoustic classifier. We also compare different neural network architectures for acoustic modeling. The proposed model computes a distribution over possible output sequences given the acoustic input signal and we present an algorithm for performing a global search for good candidate transcriptions. The performance of the proposed model is evaluated on piano music from the MAPS dataset and we observe that the proposed model consistently outperforms existing transcription methods.
A Denoising Autoencoder that Guides Stochastic Search
Apr 06, 2014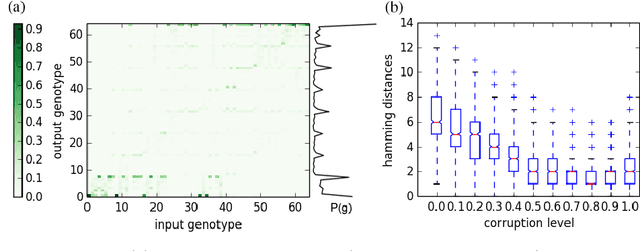
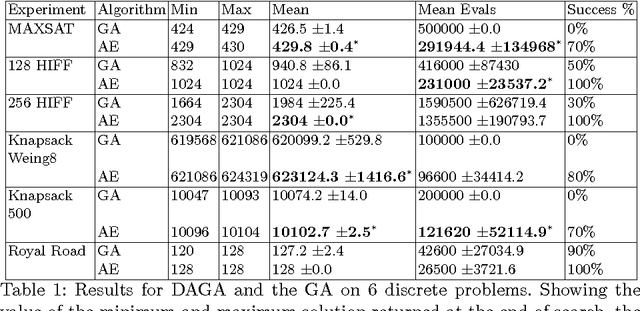
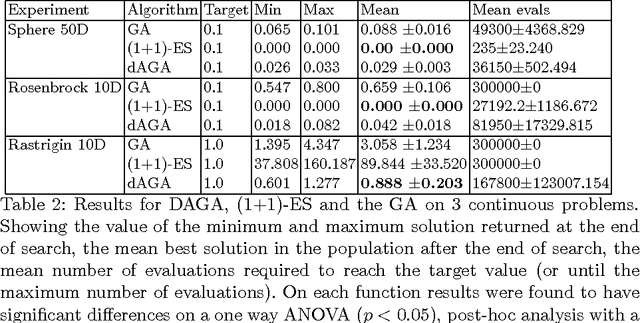

An algorithm is described that adaptively learns a non-linear mutation distribution. It works by training a denoising autoencoder (DA) online at each generation of a genetic algorithm to reconstruct a slowly decaying memory of the best genotypes so far. A compressed hidden layer forces the autoencoder to learn hidden features in the training set that can be used to accelerate search on novel problems with similar structure. Its output neurons define a probability distribution that we sample from to produce offspring solutions. The algorithm outperforms a canonical genetic algorithm on several combinatorial optimisation problems, e.g. multidimensional 0/1 knapsack problem, MAXSAT, HIFF, and on parameter optimisation problems, e.g. Rastrigin and Rosenbrock functions.