 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Attack Graph Generation
Jun 15, 2022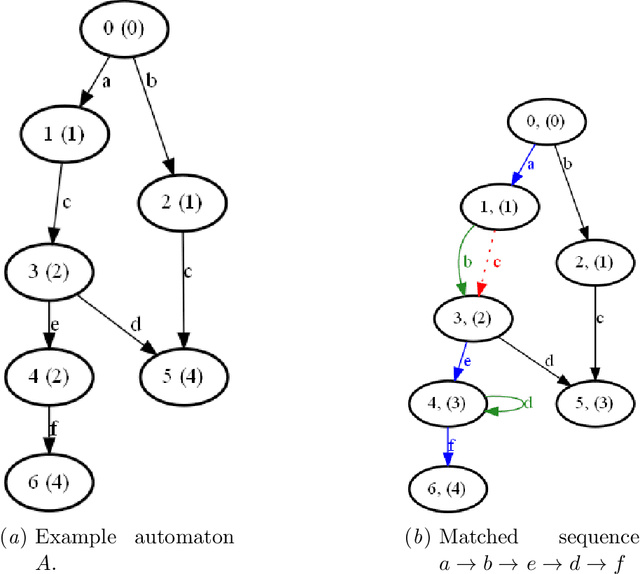
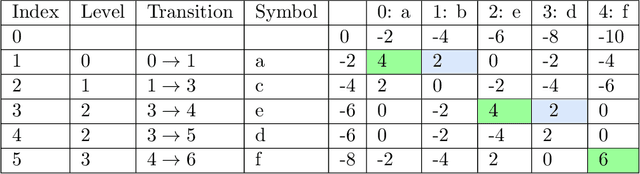
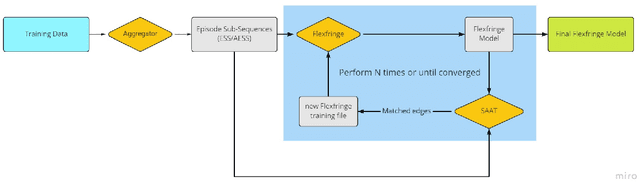
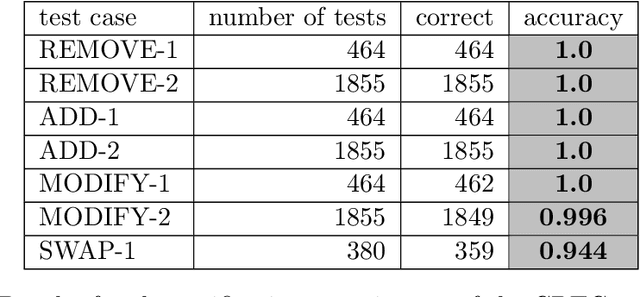
We present a method to learn automaton models that are more robust to input modifications. It iteratively aligns sequences to a learned model, modifies the sequences to their aligned versions, and re-learns the model. Automaton learning algorithms are typically very good at modeling the frequent behavior of a software system. Our solution can be used to also learn the behavior present in infrequent sequences, as these will be aligned to the frequent ones represented by the model. We apply our method to the SAGE tool for modeling attacker behavior from intrusion alerts. In experiments, we demonstrate that our algorithm learns models that can handle noise such as added and removed symbols from sequences. Furthermore, it learns more concise models that fit better to the training data.
FlexFringe: Modeling Software Behavior by Learning Probabilistic Automata
Mar 28, 2022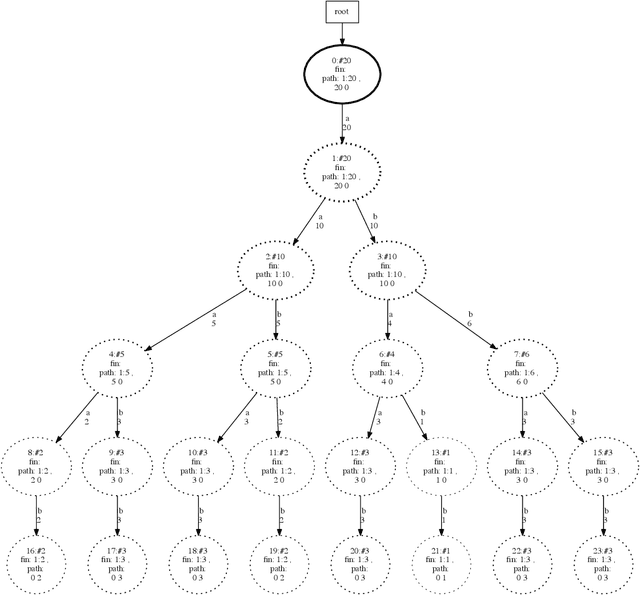
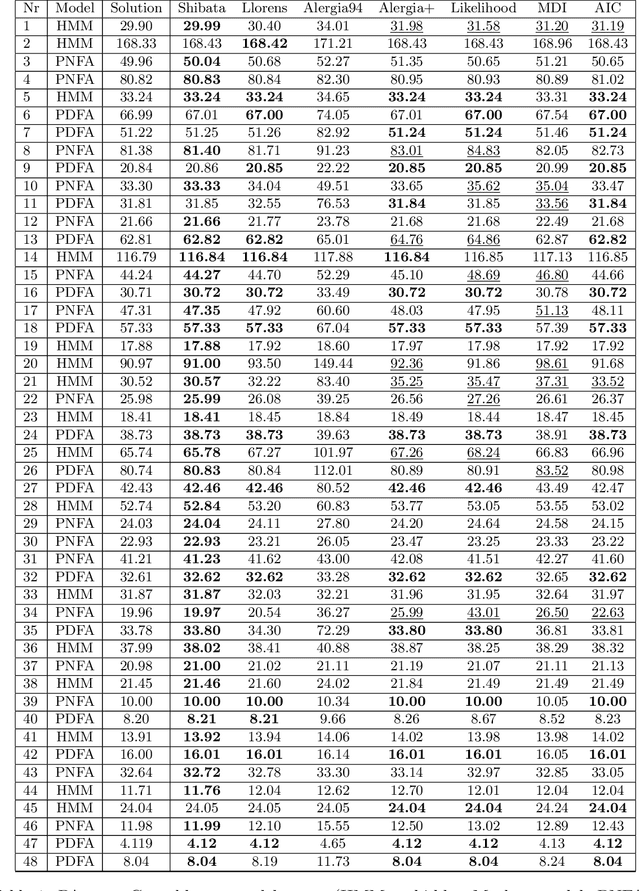
We present the efficient implementations of probabilistic deterministic finite automaton learning methods available in FlexFringe. These implement well-known strategies for state-merging including several modifications to improve their performance in practice. We show experimentally that these algorithms obtain competitive results and significant improvements over a default implementation. We also demonstrate how to use FlexFringe to learn interpretable models from software logs and use these for anomaly detection. Although less interpretable, we show that learning smaller more convoluted models improves the performance of FlexFringe on anomaly detection, outperforming an existing solution based on neural nets.
The First AI4TSP Competition: Learning to Solve Stochastic Routing Problems
Jan 25, 2022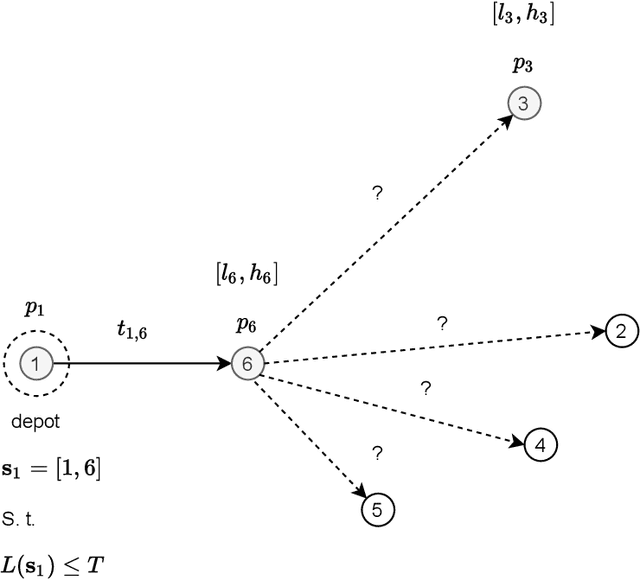
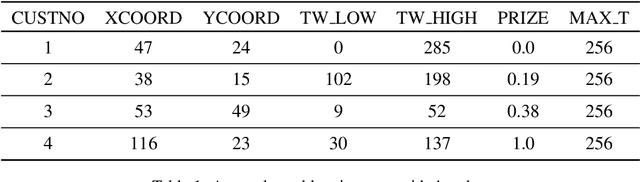
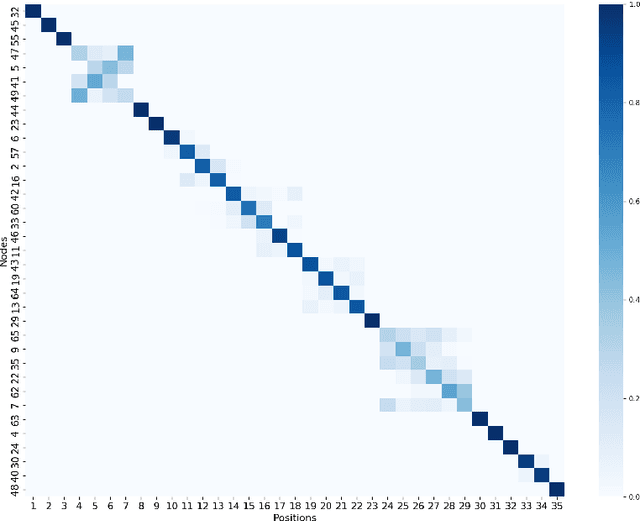
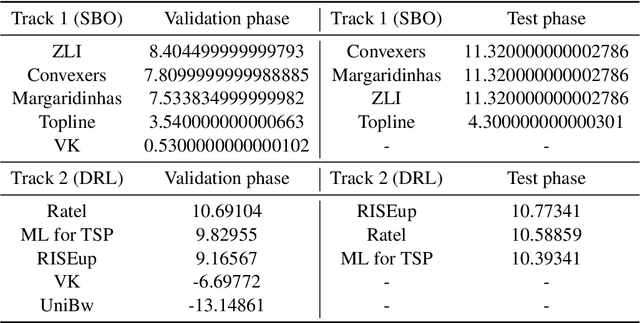
This paper reports on the first international competition on AI for the traveling salesman problem (TSP) at the International Joint Conference on Artificial Intelligence 2021 (IJCAI-21). The TSP is one of the classical combinatorial optimization problems, with many variants inspired by real-world applications. This first competition asked the participants to develop algorithms to solve a time-dependent orienteering problem with stochastic weights and time windows (TD-OPSWTW). It focused on two types of learning approaches: surrogate-based optimization and deep reinforcement learning. In this paper, we describe the problem, the setup of the competition, the winning methods, and give an overview of the results. The winning methods described in this work have advanced the state-of-the-art in using AI for stochastic routing problems. Overall, by organizing this competition we have introduced routing problems as an interesting problem setting for AI researchers. The simulator of the problem has been made open-source and can be used by other researchers as a benchmark for new AI methods.
Robust Optimal Classification Trees Against Adversarial Examples
Sep 08, 2021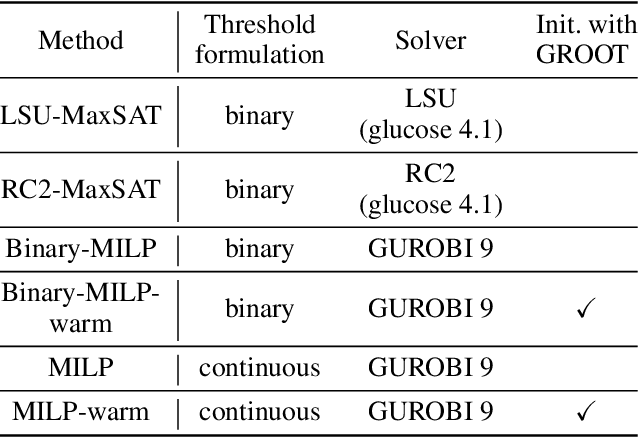
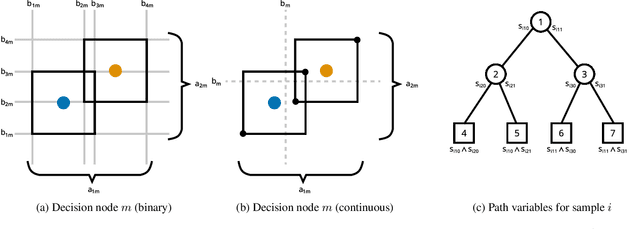

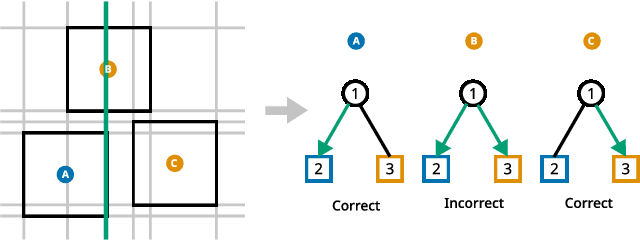
Decision trees are a popular choice of explainable model, but just like neural networks, they suffer from adversarial examples. Existing algorithms for fitting decision trees robust against adversarial examples are greedy heuristics and lack approximation guarantees. In this paper we propose ROCT, a collection of methods to train decision trees that are optimally robust against user-specified attack models. We show that the min-max optimization problem that arises in adversarial learning can be solved using a single minimization formulation for decision trees with 0-1 loss. We propose such formulations in Mixed-Integer Linear Programming and Maximum Satisfiability, which widely available solvers can optimize. We also present a method that determines the upper bound on adversarial accuracy for any model using bipartite matching. Our experimental results demonstrate that the existing heuristics achieve close to optimal scores while ROCT achieves state-of-the-art scores.
SAGE: Intrusion Alert-driven Attack Graph Extractor
Jul 06, 2021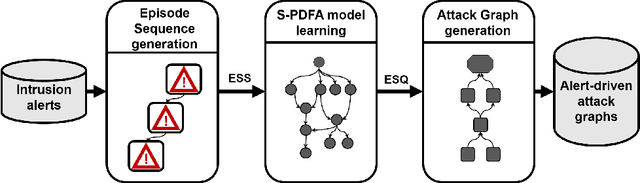
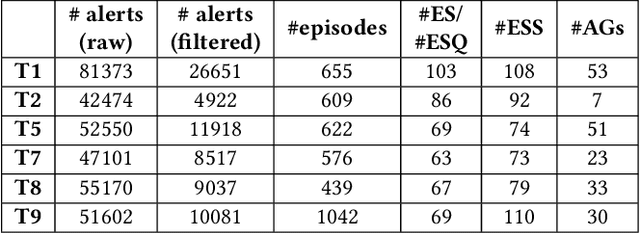
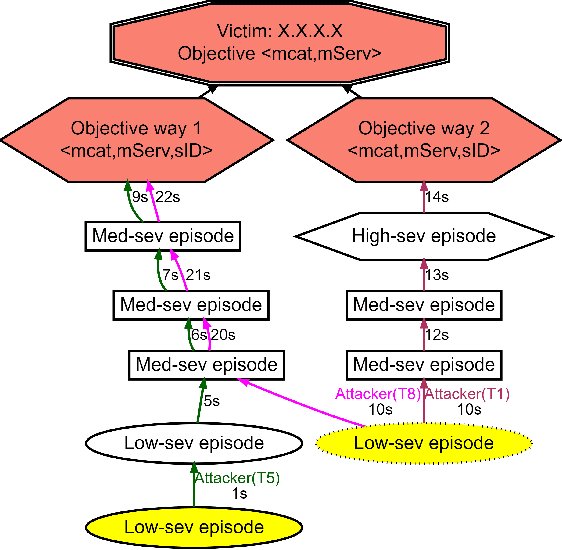
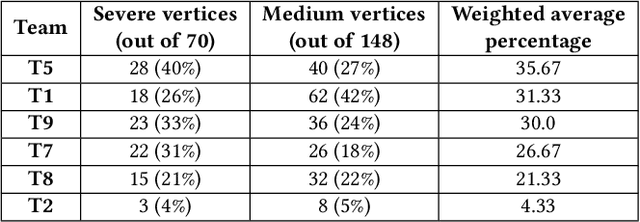
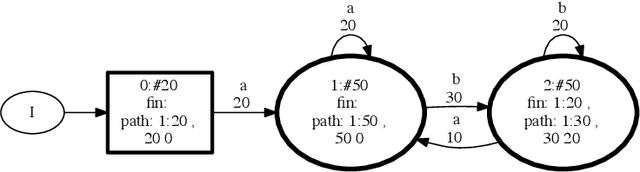
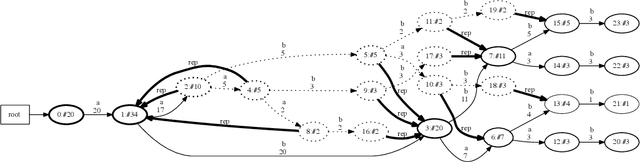
Attack graphs (AG) are used to assess pathways availed by cyber adversaries to penetrate a network. State-of-the-art approaches for AG generation focus mostly on deriving dependencies between system vulnerabilities based on network scans and expert knowledge. In real-world operations however, it is costly and ineffective to rely on constant vulnerability scanning and expert-crafted AGs. We propose to automatically learn AGs based on actions observed through intrusion alerts, without prior expert knowledge. Specifically, we develop an unsupervised sequence learning system, SAGE, that leverages the temporal and probabilistic dependence between alerts in a suffix-based probabilistic deterministic finite automaton (S-PDFA) -- a model that accentuates infrequent severe alerts and summarizes paths leading to them. AGs are then derived from the S-PDFA. Tested with intrusion alerts collected through Collegiate Penetration Testing Competition, SAGE produces AGs that reflect the strategies used by participating teams. The resulting AGs are succinct, interpretable, and enable analysts to derive actionable insights, e.g., attackers tend to follow shorter paths after they have discovered a longer one.
EXPObench: Benchmarking Surrogate-based Optimisation Algorithms on Expensive Black-box Functions
Jun 08, 2021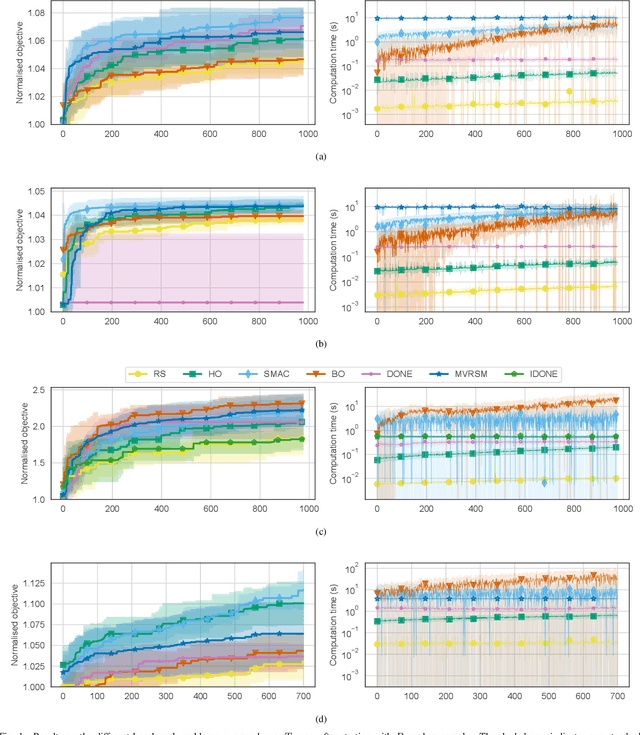
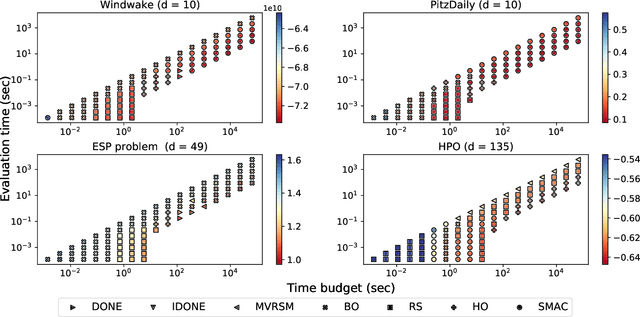
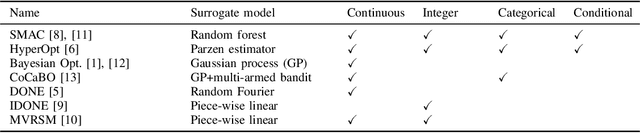
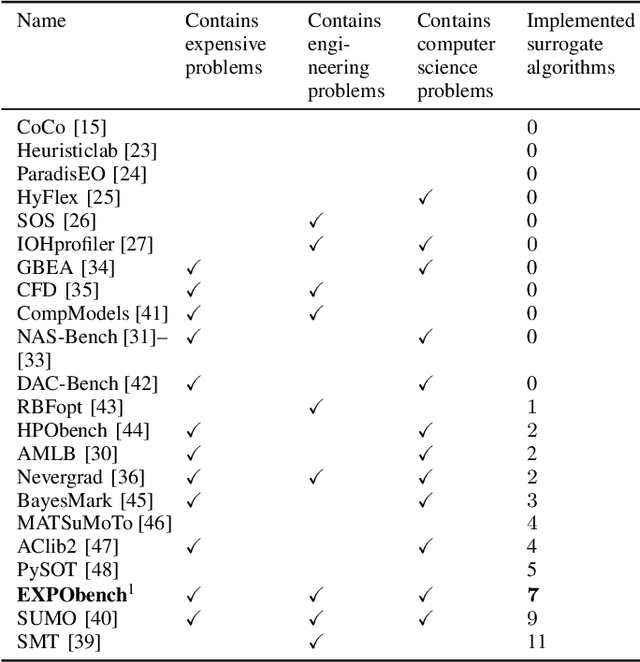
Surrogate algorithms such as Bayesian optimisation are especially designed for black-box optimisation problems with expensive objectives, such as hyperparameter tuning or simulation-based optimisation. In the literature, these algorithms are usually evaluated with synthetic benchmarks which are well established but have no expensive objective, and only on one or two real-life applications which vary wildly between papers. There is a clear lack of standardisation when it comes to benchmarking surrogate algorithms on real-life, expensive, black-box objective functions. This makes it very difficult to draw conclusions on the effect of algorithmic contributions. A new benchmark library, EXPObench, provides first steps towards such a standardisation. The library is used to provide an extensive comparison of six different surrogate algorithms on four expensive optimisation problems from different real-life applications. This has led to new insights regarding the relative importance of exploration, the evaluation time of the objective, and the used model. A further contribution is that we make the algorithms and benchmark problem instances publicly available, contributing to more uniform analysis of surrogate algorithms. Most importantly, we include the performance of the six algorithms on all evaluated problem instances. This results in a unique new dataset that lowers the bar for researching new methods as the number of expensive evaluations required for comparison is significantly reduced.
Efficient Training of Robust Decision Trees Against Adversarial Examples
Dec 18, 2020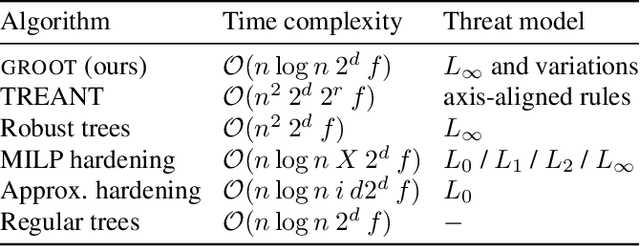
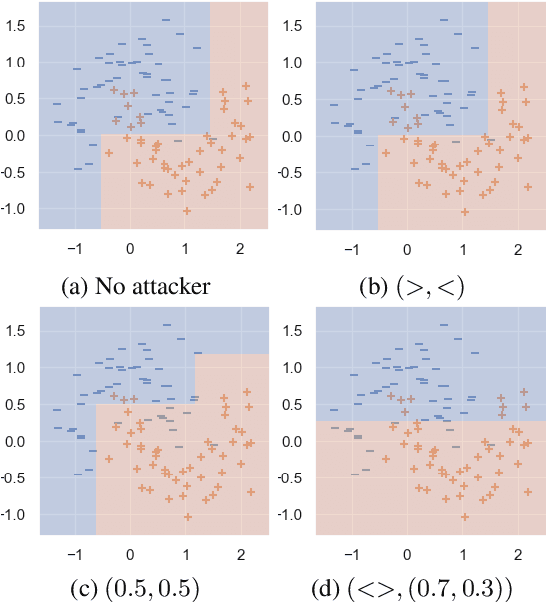
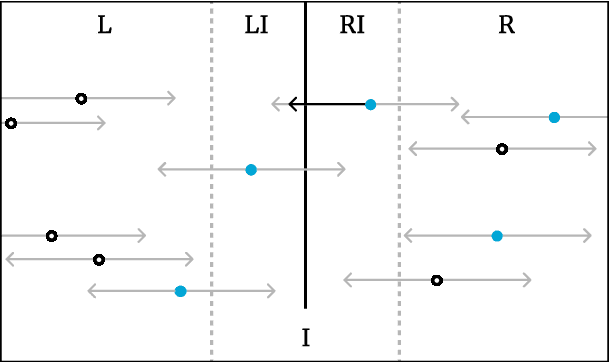
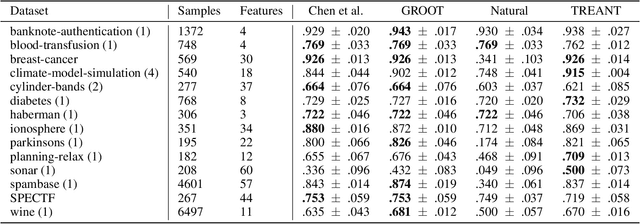
In the present day we use machine learning for sensitive tasks that require models to be both understandable and robust. Although traditional models such as decision trees are understandable, they suffer from adversarial attacks. When a decision tree is used to differentiate between a user's benign and malicious behavior, an adversarial attack allows the user to effectively evade the model by perturbing the inputs the model receives. We can use algorithms that take adversarial attacks into account to fit trees that are more robust. In this work we propose an algorithm, GROOT, that is two orders of magnitude faster than the state-of-the-art-work while scoring competitively on accuracy against adversaries. GROOT accepts an intuitive and permissible threat model. Where previous threat models were limited to distance norms, we allow each feature to be perturbed with a user-specified parameter: either a maximum distance or constraints on the direction of perturbation. Previous works assumed that both benign and malicious users attempt model evasion but we allow the user to select which classes perform adversarial attacks. Additionally, we introduce a hyperparameter rho that allows GROOT to trade off performance in the regular and adversarial settings.
Continuous surrogate-based optimization algorithms are well-suited for expensive discrete problems
Nov 06, 2020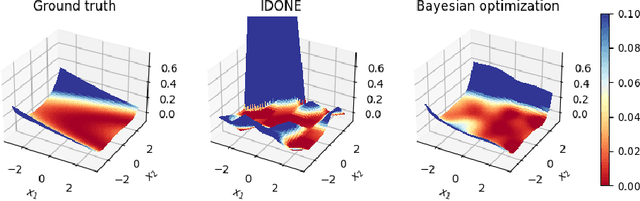
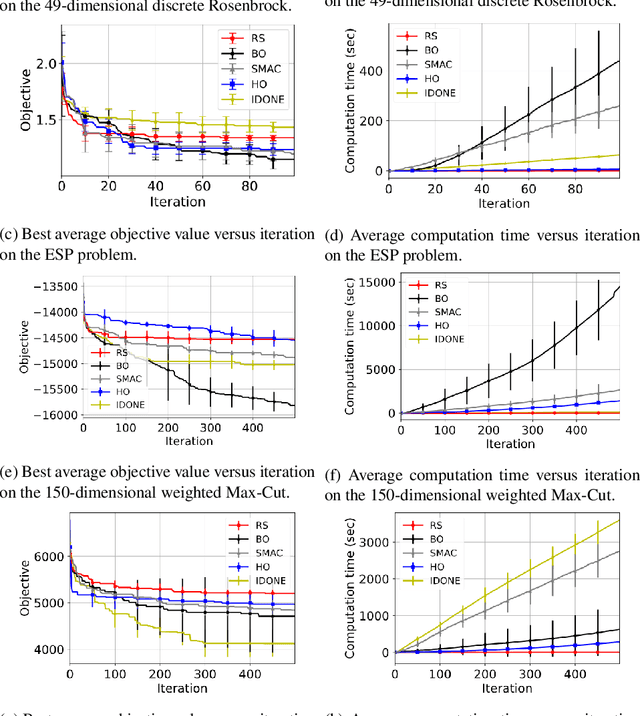
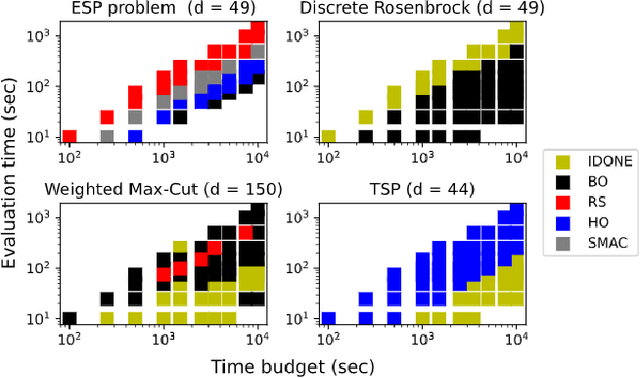
One method to solve expensive black-box optimization problems is to use a surrogate model that approximates the objective based on previous observed evaluations. The surrogate, which is cheaper to evaluate, is optimized instead to find an approximate solution to the original problem. In the case of discrete problems, recent research has revolved around surrogate models that are specifically constructed to deal with discrete structures. A main motivation is that literature considers continuous methods, such as Bayesian optimization with Gaussian processes as the surrogate, to be sub-optimal (especially in higher dimensions) because they ignore the discrete structure by e.g. rounding off real-valued solutions to integers. However, we claim that this is not true. In fact, we present empirical evidence showing that the use of continuous surrogate models displays competitive performance on a set of high-dimensional discrete benchmark problems, including a real-life application, against state-of-the-art discrete surrogate-based methods. Our experiments on different discrete structures and time constraints also give more insight into which algorithms work well on which type of problem.
Black-box Mixed-Variable Optimisation using a Surrogate Model that Satisfies Integer Constraints
Jun 08, 2020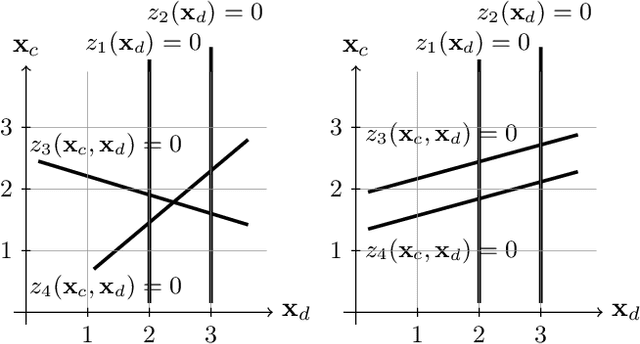

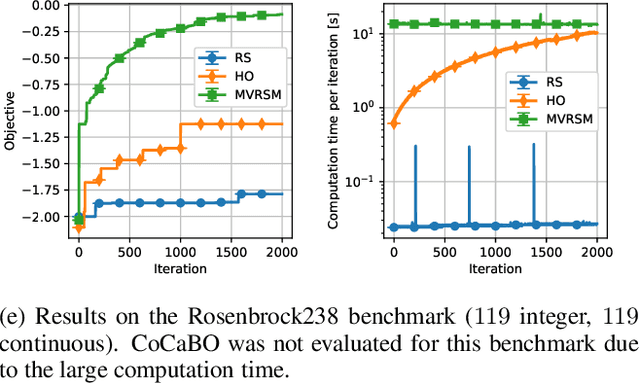
A challenging problem in both engineering and computer science is that of minimising a function for which we have no mathematical formulation available, that is expensive to evaluate, and that contains continuous and integer variables, for example in automatic algorithm configuration. Surrogate modelling techniques are very suitable for this type of problem, but most existing techniques are designed with only continuous or only discrete variables in mind. Mixed-Variable ReLU-based Surrogate Modelling (MVRSM) is a surrogate modelling algorithm that uses a linear combination of rectified linear units, defined in such a way that (local) optima satisfy the integer constraints. This method is both more accurate and more efficient than the state of the art on several benchmarks with up to 238 continuous and integer variables.
Black-box Combinatorial Optimization using Models with Integer-valued Minima
Nov 20, 2019
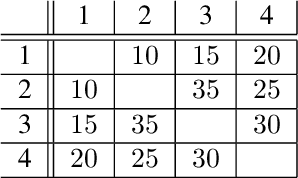
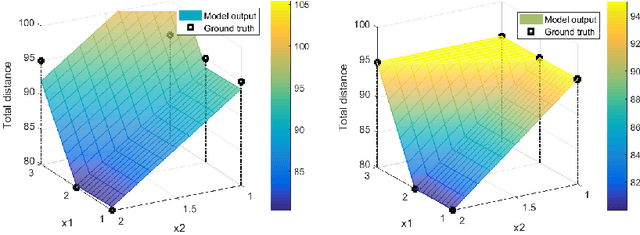
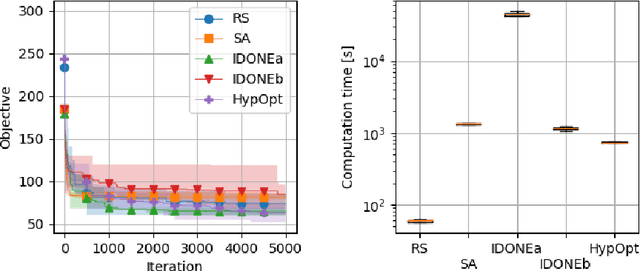
When a black-box optimization objective can only be evaluated with costly or noisy measurements, most standard optimization algorithms are unsuited to find the optimal solution. Specialized algorithms that deal with exactly this situation make use of surrogate models. These models are usually continuous and smooth, which is beneficial for continuous optimization problems, but not necessarily for combinatorial problems. However, by choosing the basis functions of the surrogate model in a certain way, we show that it can be guaranteed that the optimal solution of the surrogate model is integer. This approach outperforms random search, simulated annealing and one Bayesian optimization algorithm on the problem of finding robust routes for a noise-perturbed traveling salesman benchmark problem, with similar performance as another Bayesian optimization algorithm, and outperforms all compared algorithms on a convex binary optimization problem with a large number of variables.