 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Self-Supervised Speech Models Exhibit the Critical Period Effects in Language Acquisition?
Aug 28, 2025This paper investigates whether the Critical Period (CP) effects in human language acquisition are observed in self-supervised speech models (S3Ms). CP effects refer to greater difficulty in acquiring a second language (L2) with delayed L2 exposure onset, and greater retention of their first language (L1) with delayed L1 exposure offset. While previous work has studied these effects using textual language models, their presence in speech models remains underexplored despite the central role of spoken language in human language acquisition. We train S3Ms with varying L2 training onsets and L1 training offsets on child-directed speech and evaluate their phone discrimination performance. We find that S3Ms do not exhibit clear evidence of either CP effects in terms of phonological acquisition. Notably, models with delayed L2 exposure onset tend to perform better on L2 and delayed L1 exposure offset leads to L1 forgetting.
Exploring the Effect of Segmentation and Vocabulary Size on Speech Tokenization for Speech Language Models
May 23, 2025The purpose of speech tokenization is to transform a speech signal into a sequence of discrete representations, serving as the foundation for speech language models (SLMs). While speech tokenization has many options, their effect on the performance of SLMs remains unclear. This paper investigates two key aspects of speech tokenization: the segmentation width and the cluster size of discrete units. First, we segment speech signals into fixed/variable widths and pooled representations. We then train K-means models in multiple cluster sizes. Through the evaluation on zero-shot spoken language understanding benchmarks, we find the positive effect of moderately coarse segmentation and bigger cluster size. Notably, among the best-performing models, the most efficient one achieves a 50% reduction in training data and a 70% decrease in training runtime. Our analysis highlights the importance of combining multiple tokens to enhance fine-grained spoken language understanding.
Syntactic Learnability of Echo State Neural Language Models at Scale
Mar 03, 2025What is a neural model with minimum architectural complexity that exhibits reasonable language learning capability? To explore such a simple but sufficient neural language model, we revisit a basic reservoir computing (RC) model, Echo State Network (ESN), a restricted class of simple Recurrent Neural Networks. Our experiments showed that ESN with a large hidden state is comparable or superior to Transformer in grammaticality judgment tasks when trained with about 100M words, suggesting that architectures as complex as that of Transformer may not always be necessary for syntactic learning.
Textless Dependency Parsing by Labeled Sequence Prediction
Jul 14, 2024



Traditional spoken language processing involves cascading an automatic speech recognition (ASR) system into text processing models. In contrast, "textless" methods process speech representations without ASR systems, enabling the direct use of acoustic speech features. Although their effectiveness is shown in capturing acoustic features, it is unclear in capturing lexical knowledge. This paper proposes a textless method for dependency parsing, examining its effectiveness and limitations. Our proposed method predicts a dependency tree from a speech signal without transcribing, representing the tree as a labeled sequence. scading method outperforms the textless method in overall parsing accuracy, the latter excels in instances with important acoustic features. Our findings highlight the importance of fusing word-level representations and sentence-level prosody for enhanced parsing performance. The code and models are made publicly available: https://github.com/mynlp/SpeechParser.
Multilingual Syntax-aware Language Modeling through Dependency Tree Conversion
Apr 19, 2022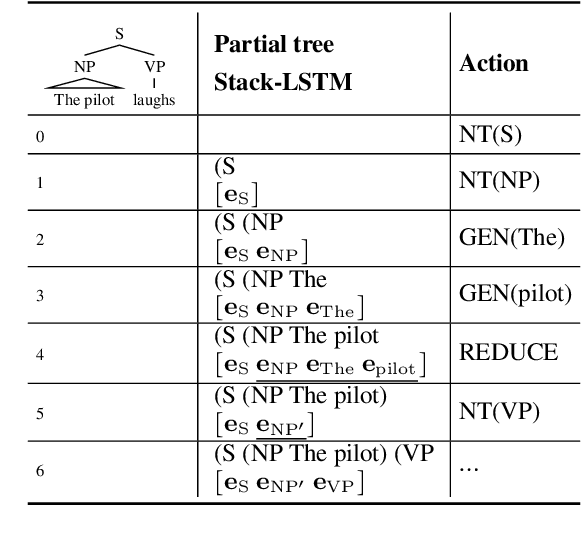
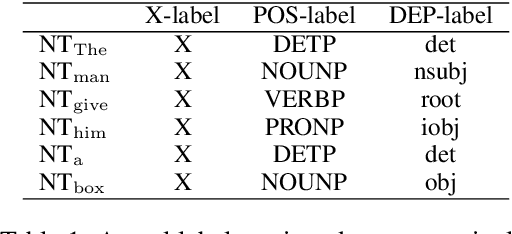
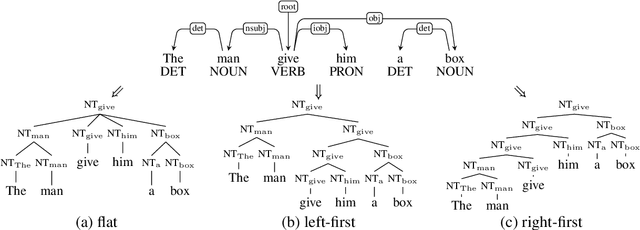
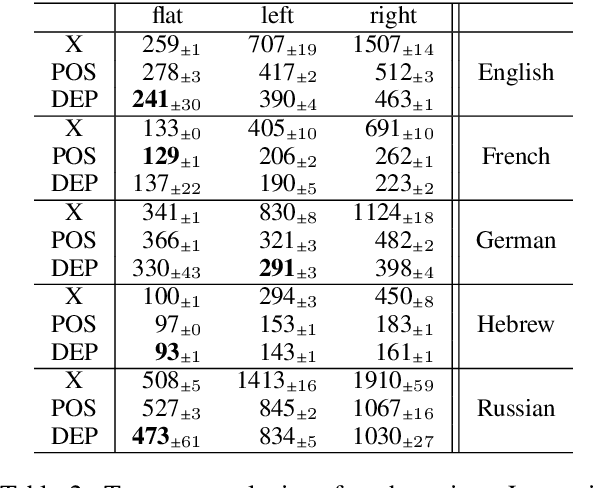
Incorporating stronger syntactic biases into neural language models (LMs) is a long-standing goal, but research in this area often focuses on modeling English text, where constituent treebanks are readily available. Extending constituent tree-based LMs to the multilingual setting, where dependency treebanks are more common, is possible via dependency-to-constituency conversion methods. However, this raises the question of which tree formats are best for learning the model, and for which languages. We investigate this question by training recurrent neural network grammars (RNNGs) using various conversion methods, and evaluating them empirically in a multilingual setting. We examine the effect on LM performance across nine conversion methods and five languages through seven types of syntactic tests. On average, the performance of our best model represents a 19 \% increase in accuracy over the worst choice across all languages. Our best model shows the advantage over sequential/overparameterized LMs, suggesting the positive effect of syntax injection in a multilingual setting. Our experiments highlight the importance of choosing the right tree formalism, and provide insights into making an informed decision.