 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025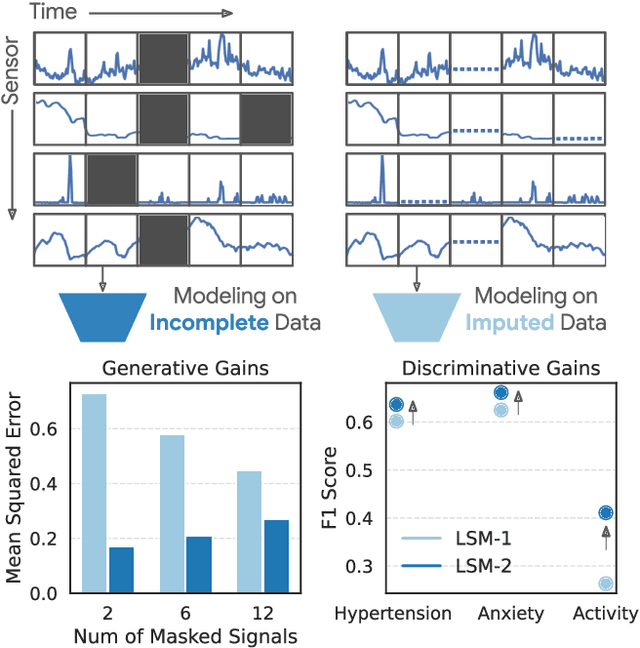
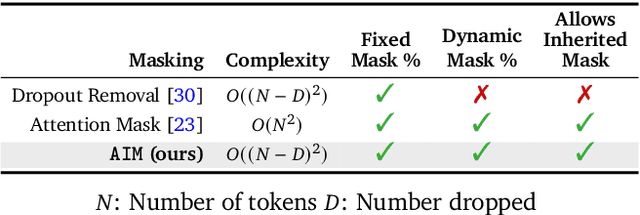
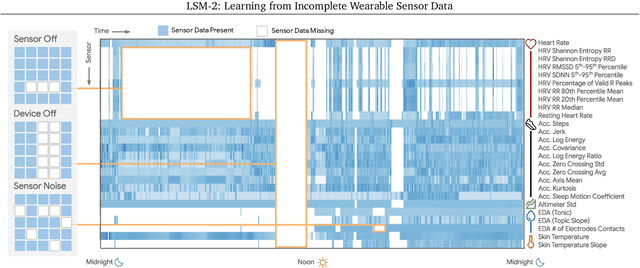
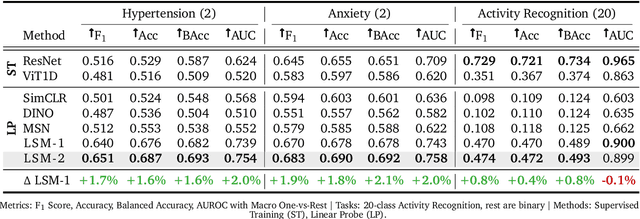
Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Towards disentangling the contributions of articulation and acoustics in multimodal phoneme recognition
May 29, 2025Although many previous studies have carried out multimodal learning with real-time MRI data that captures the audio-visual kinematics of the vocal tract during speech, these studies have been limited by their reliance on multi-speaker corpora. This prevents such models from learning a detailed relationship between acoustics and articulation due to considerable cross-speaker variability. In this study, we develop unimodal audio and video models as well as multimodal models for phoneme recognition using a long-form single-speaker MRI corpus, with the goal of disentangling and interpreting the contributions of each modality. Audio and multimodal models show similar performance on different phonetic manner classes but diverge on places of articulation. Interpretation of the models' latent space shows similar encoding of the phonetic space across audio and multimodal models, while the models' attention weights highlight differences in acoustic and articulatory timing for certain phonemes.
Developing a Top-tier Framework in Naturalistic Conditions Challenge for Categorized Emotion Prediction: From Speech Foundation Models and Learning Objective to Data Augmentation and Engineering Choices
May 28, 2025Speech emotion recognition (SER), particularly for naturally expressed emotions, remains a challenging computational task. Key challenges include the inherent subjectivity in emotion annotation and the imbalanced distribution of emotion labels in datasets. This paper introduces the \texttt{SAILER} system developed for participation in the INTERSPEECH 2025 Emotion Recognition Challenge (Task 1). The challenge dataset, which contains natural emotional speech from podcasts, serves as a valuable resource for studying imbalanced and subjective emotion annotations. Our system is designed to be simple, reproducible, and effective, highlighting critical choices in modeling, learning objectives, data augmentation, and engineering choices. Results show that even a single system (without ensembling) can outperform more than 95\% of the submissions, with a Macro-F1 score exceeding 0.4. Moreover, an ensemble of three systems further improves performance, achieving a competitively ranked score (top-3 performing team). Our model is at: https://github.com/tiantiaf0627/vox-profile-release.
Large Language Models Do Multi-Label Classification Differently
May 23, 2025Multi-label classification is prevalent in real-world settings, but the behavior of Large Language Models (LLMs) in this setting is understudied. We investigate how autoregressive LLMs perform multi-label classification, with a focus on subjective tasks, by analyzing the output distributions of the models in each generation step. We find that their predictive behavior reflects the multiple steps in the underlying language modeling required to generate all relevant labels as they tend to suppress all but one label at each step. We further observe that as model scale increases, their token distributions exhibit lower entropy, yet the internal ranking of the labels improves. Finetuning methods such as supervised finetuning and reinforcement learning amplify this phenomenon. To further study this issue, we introduce the task of distribution alignment for multi-label settings: aligning LLM-derived label distributions with empirical distributions estimated from annotator responses in subjective tasks. We propose both zero-shot and supervised methods which improve both alignment and predictive performance over existing approaches.
Humans Hallucinate Too: Language Models Identify and Correct Subjective Annotation Errors With Label-in-a-Haystack Prompts
May 22, 2025Modeling complex subjective tasks in Natural Language Processing, such as recognizing emotion and morality, is considerably challenging due to significant variation in human annotations. This variation often reflects reasonable differences in semantic interpretations rather than mere noise, necessitating methods to distinguish between legitimate subjectivity and error. We address this challenge by exploring label verification in these contexts using Large Language Models (LLMs). First, we propose a simple In-Context Learning binary filtering baseline that estimates the reasonableness of a document-label pair. We then introduce the Label-in-a-Haystack setting: the query and its label(s) are included in the demonstrations shown to LLMs, which are prompted to predict the label(s) again, while receiving task-specific instructions (e.g., emotion recognition) rather than label copying. We show how the failure to copy the label(s) to the output of the LLM are task-relevant and informative. Building on this, we propose the Label-in-a-Haystack Rectification (LiaHR) framework for subjective label correction: when the model outputs diverge from the reference gold labels, we assign the generated labels to the example instead of discarding it. This approach can be integrated into annotation pipelines to enhance signal-to-noise ratios. Comprehensive analyses, human evaluations, and ecological validity studies verify the utility of LiaHR for label correction. Code is available at https://github.com/gchochla/LiaHR.
Large Language Models based ASR Error Correction for Child Conversations
May 22, 2025



Automatic Speech Recognition (ASR) has recently shown remarkable progress, but accurately transcribing children's speech remains a significant challenge. Recent developments in Large Language Models (LLMs) have shown promise in improving ASR transcriptions. However, their applications in child speech including conversational scenarios are underexplored. In this study, we explore the use of LLMs in correcting ASR errors for conversational child speech. We demonstrate the promises and challenges of LLMs through experiments on two children's conversational speech datasets with both zero-shot and fine-tuned ASR outputs. We find that while LLMs are helpful in correcting zero-shot ASR outputs and fine-tuned CTC-based ASR outputs, it remains challenging for LLMs to improve ASR performance when incorporating contextual information or when using fine-tuned autoregressive ASR (e.g., Whisper) outputs.
Articulatory Feature Prediction from Surface EMG during Speech Production
May 20, 2025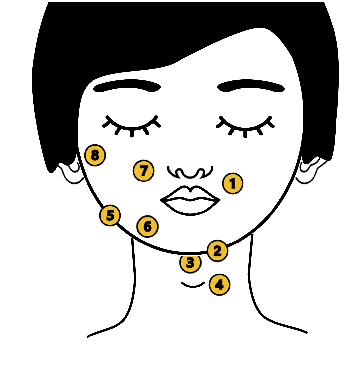

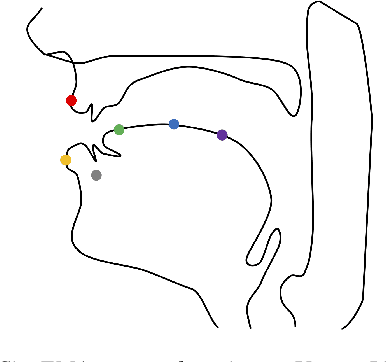
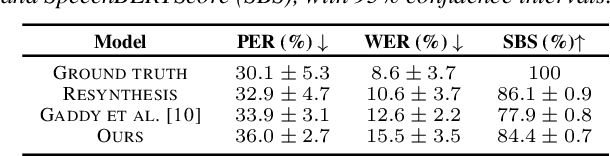
We present a model for predicting articulatory features from surface electromyography (EMG) signals during speech production. The proposed model integrates convolutional layers and a Transformer block, followed by separate predictors for articulatory features. Our approach achieves a high prediction correlation of approximately 0.9 for most articulatory features. Furthermore, we demonstrate that these predicted articulatory features can be decoded into intelligible speech waveforms. To our knowledge, this is the first method to decode speech waveforms from surface EMG via articulatory features, offering a novel approach to EMG-based speech synthesis. Additionally, we analyze the relationship between EMG electrode placement and articulatory feature predictability, providing knowledge-driven insights for optimizing EMG electrode configurations. The source code and decoded speech samples are publicly available.
Vox-Profile: A Speech Foundation Model Benchmark for Characterizing Diverse Speaker and Speech Traits
May 20, 2025We introduce Vox-Profile, a comprehensive benchmark to characterize rich speaker and speech traits using speech foundation models. Unlike existing works that focus on a single dimension of speaker traits, Vox-Profile provides holistic and multi-dimensional profiles that reflect both static speaker traits (e.g., age, sex, accent) and dynamic speech properties (e.g., emotion, speech flow). This benchmark is grounded in speech science and linguistics, developed with domain experts to accurately index speaker and speech characteristics. We report benchmark experiments using over 15 publicly available speech datasets and several widely used speech foundation models that target various static and dynamic speaker and speech properties. In addition to benchmark experiments, we showcase several downstream applications supported by Vox-Profile. First, we show that Vox-Profile can augment existing speech recognition datasets to analyze ASR performance variability. Vox-Profile is also used as a tool to evaluate the performance of speech generation systems. Finally, we assess the quality of our automated profiles through comparison with human evaluation and show convergent validity. Vox-Profile is publicly available at: https://github.com/tiantiaf0627/vox-profile-release.
Who Said What WSW 2.0? Enhanced Automated Analysis of Preschool Classroom Speech
May 15, 2025



This paper introduces an automated framework WSW2.0 for analyzing vocal interactions in preschool classrooms, enhancing both accuracy and scalability through the integration of wav2vec2-based speaker classification and Whisper (large-v2 and large-v3) speech transcription. A total of 235 minutes of audio recordings (160 minutes from 12 children and 75 minutes from 5 teachers), were used to compare system outputs to expert human annotations. WSW2.0 achieves a weighted F1 score of .845, accuracy of .846, and an error-corrected kappa of .672 for speaker classification (child vs. teacher). Transcription quality is moderate to high with word error rates of .119 for teachers and .238 for children. WSW2.0 exhibits relatively high absolute agreement intraclass correlations (ICC) with expert transcriptions for a range of classroom language features. These include teacher and child mean utterance length, lexical diversity, question asking, and responses to questions and other utterances, which show absolute agreement intraclass correlations between .64 and .98. To establish scalability, we apply the framework to an extensive dataset spanning two years and over 1,592 hours of classroom audio recordings, demonstrating the framework's robustness for broad real-world applications. These findings highlight the potential of deep learning and natural language processing techniques to revolutionize educational research by providing accurate measures of key features of preschool classroom speech, ultimately guiding more effective intervention strategies and supporting early childhood language development.
Deep Learning Characterizes Depression and Suicidal Ideation from Eye Movements
Apr 29, 2025Identifying physiological and behavioral markers for mental health conditions is a longstanding challenge in psychiatry. Depression and suicidal ideation, in particular, lack objective biomarkers, with screening and diagnosis primarily relying on self-reports and clinical interviews. Here, we investigate eye tracking as a potential marker modality for screening purposes. Eye movements are directly modulated by neuronal networks and have been associated with attentional and mood-related patterns; however, their predictive value for depression and suicidality remains unclear. We recorded eye-tracking sequences from 126 young adults as they read and responded to affective sentences, and subsequently developed a deep learning framework to predict their clinical status. The proposed model included separate branches for trials of positive and negative sentiment, and used 2D time-series representations to account for both intra-trial and inter-trial variations. We were able to identify depression and suicidal ideation with an area under the receiver operating curve (AUC) of 0.793 (95% CI: 0.765-0.819) against healthy controls, and suicidality specifically with 0.826 AUC (95% CI: 0.797-0.852). The model also exhibited moderate, yet significant, accuracy in differentiating depressed from suicidal participants, with 0.609 AUC (95% CI 0.571-0.646). Discriminative patterns emerge more strongly when assessing the data relative to response generation than relative to the onset time of the final word of the sentences. The most pronounced effects were observed for negative-sentiment sentences, that are congruent to depressed and suicidal participants. Our findings highlight eye tracking as an objective tool for mental health assessment and underscore the modulatory impact of emotional stimuli on cognitive processes affecting oculomotor control.