 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarycentric alignment for instance-level comparison of neural representations
Feb 09, 2026Comparing representations across neural networks is challenging because representations admit symmetries, such as arbitrary reordering of units or rotations of activation space, that obscure underlying equivalence between models. We introduce a barycentric alignment framework that quotients out these nuisance symmetries to construct a universal embedding space across many models. Unlike existing similarity measures, which summarize relationships over entire stimulus sets, this framework enables similarity to be defined at the level of individual stimuli, revealing inputs that elicit convergent versus divergent representations across models. Using this instance-level notion of similarity, we identify systematic input properties that predict representational convergence versus divergence across vision and language model families. We also construct universal embedding spaces for brain representations across individuals and cortical regions, enabling instance-level comparison of representational agreement across stages of the human visual hierarchy. Finally, we apply the same barycentric alignment framework to purely unimodal vision and language models and find that post-hoc alignment into a shared space yields image text similarity scores that closely track human cross-modal judgments and approach the performance of contrastively trained vision-language models. This strikingly suggests that independently learned representations already share sufficient geometric structure for human-aligned cross-modal comparison. Together, these results show that resolving representational similarity at the level of individual stimuli reveals phenomena that cannot be detected by set-level comparison metrics.
Measuring the Measures: Discriminative Capacity of Representational Similarity Metrics Across Model Families
Sep 04, 2025Representational similarity metrics are fundamental tools in neuroscience and AI, yet we lack systematic comparisons of their discriminative power across model families. We introduce a quantitative framework to evaluate representational similarity measures based on their ability to separate model families-across architectures (CNNs, Vision Transformers, Swin Transformers, ConvNeXt) and training regimes (supervised vs. self-supervised). Using three complementary separability measures-dprime from signal detection theory, silhouette coefficients and ROC-AUC, we systematically assess the discriminative capacity of commonly used metrics including RSA, linear predictivity, Procrustes, and soft matching. We show that separability systematically increases as metrics impose more stringent alignment constraints. Among mapping-based approaches, soft-matching achieves the highest separability, followed by Procrustes alignment and linear predictivity. Non-fitting methods such as RSA also yield strong separability across families. These results provide the first systematic comparison of similarity metrics through a separability lens, clarifying their relative sensitivity and guiding metric choice for large-scale model and brain comparisons.
Modeling the Human Visual System: Comparative Insights from Response-Optimized and Task-Optimized Vision Models, Language Models, and different Readout Mechanisms
Oct 17, 2024



Over the past decade, predictive modeling of neural responses in the primate visual system has advanced significantly, largely driven by various DNN approaches. These include models optimized directly for visual recognition, cross-modal alignment through contrastive objectives, neural response prediction from scratch, and large language model embeddings.Likewise, different readout mechanisms, ranging from fully linear to spatial-feature factorized methods have been explored for mapping network activations to neural responses. Despite the diversity of these approaches, it remains unclear which method performs best across different visual regions. In this study, we systematically compare these approaches for modeling the human visual system and investigate alternative strategies to improve response predictions. Our findings reveal that for early to mid-level visual areas, response-optimized models with visual inputs offer superior prediction accuracy, while for higher visual regions, embeddings from LLMs based on detailed contextual descriptions of images and task-optimized models pretrained on large vision datasets provide the best fit. Through comparative analysis of these modeling approaches, we identified three distinct regions in the visual cortex: one sensitive primarily to perceptual features of the input that are not captured by linguistic descriptions, another attuned to fine-grained visual details representing semantic information, and a third responsive to abstract, global meanings aligned with linguistic content. We also highlight the critical role of readout mechanisms, proposing a novel scheme that modulates receptive fields and feature maps based on semantic content, resulting in an accuracy boost of 3-23% over existing SOTAs for all models and brain regions. Together, these findings offer key insights into building more precise models of the visual system.
BASED: Bundle-Adjusting Surgical Endoscopic Dynamic Video Reconstruction using Neural Radiance Fields
Sep 27, 2023



Reconstruction of deformable scenes from endoscopic videos is important for many applications such as intraoperative navigation, surgical visual perception, and robotic surgery. It is a foundational requirement for realizing autonomous robotic interventions for minimally invasive surgery. However, previous approaches in this domain have been limited by their modular nature and are confined to specific camera and scene settings. Our work adopts the Neural Radiance Fields (NeRF) approach to learning 3D implicit representations of scenes that are both dynamic and deformable over time, and furthermore with unknown camera poses. We demonstrate this approach on endoscopic surgical scenes from robotic surgery. This work removes the constraints of known camera poses and overcomes the drawbacks of the state-of-the-art unstructured dynamic scene reconstruction technique, which relies on the static part of the scene for accurate reconstruction. Through several experimental datasets, we demonstrate the versatility of our proposed model to adapt to diverse camera and scene settings, and show its promise for both current and future robotic surgical systems.
BAA-NGP: Bundle-Adjusting Accelerated Neural Graphics Primitives
Jun 09, 2023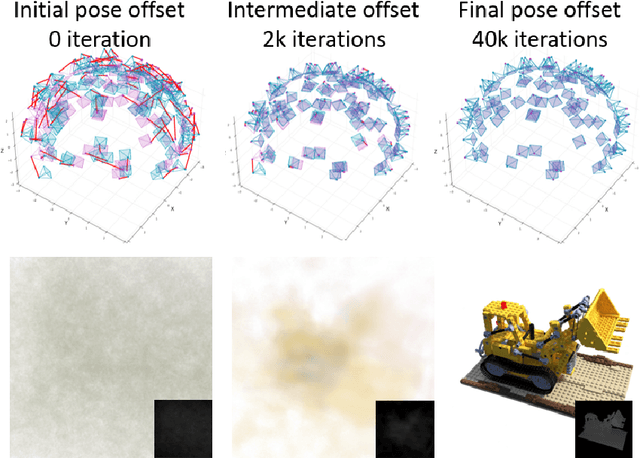
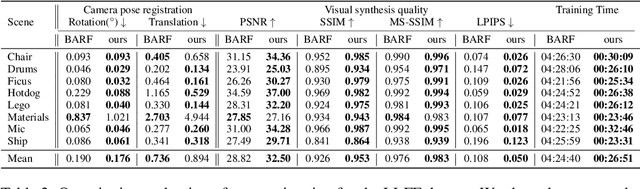
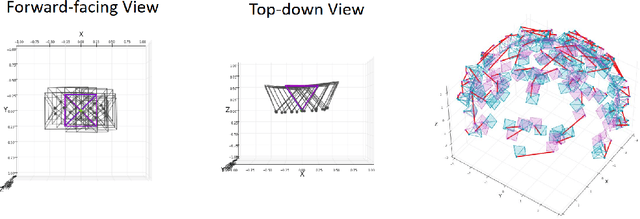
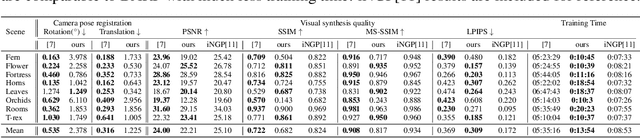
Implicit neural representation has emerged as a powerful method for reconstructing 3D scenes from 2D images. Given a set of camera poses and associated images, the models can be trained to synthesize novel, unseen views. In order to expand the use cases for implicit neural representations, we need to incorporate camera pose estimation capabilities as part of the representation learning, as this is necessary for reconstructing scenes from real-world video sequences where cameras are generally not being tracked. Existing approaches like COLMAP and, most recently, bundle-adjusting neural radiance field methods often suffer from lengthy processing times. These delays ranging from hours to days, arise from laborious feature matching, hardware limitations, dense point sampling, and long training times required by a multi-layer perceptron structure with a large number of parameters. To address these challenges, we propose a framework called bundle-adjusting accelerated neural graphics primitives (BAA-NGP). Our approach leverages accelerated sampling and hash encoding to expedite both pose refinement/estimation and 3D scene reconstruction. Experimental results demonstrate that our method achieves a more than 10 to 20 $\times$ speed improvement in novel view synthesis compared to other bundle-adjusting neural radiance field methods without sacrificing the quality of pose estimation.