 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverberation-Robust Localization of Speakers Using Distinct Speech Onsets and Multi-channel Cross-Correlations
Apr 02, 2026Many speaker localization methods can be found in the literature. However, speaker localization under strong reverberation still remains a major challenge in the real-world applications. This paper proposes two algorithms for localizing speakers using microphone array recordings of reverberated sounds. To separate concurrent speakers, the first algorithm decomposes microphone signals spectrotemporally into subbands via an auditory filterbank. To suppress reverberation, we propose a novel speech onset detection approach derived from the speech signal and impulse response models, and further propose to formulate the multi-channel cross-correlation coefficient (MCCC) of encoded speech onsets in each subband. The subband results are combined to estimate the directions-of-arrival (DOAs) of speakers. The second algorithm extends the generalized cross-correlation - phase transform (GCC-PHAT) method by using redundant information of multiple microphones to address the reverberation problem. The proposed methods have been evaluated under adverse conditions using not only simulated signals (reverberation time $T_{60}$ of up to $1$s) but also recordings in a real reverberant room ($T_{60} \approx 0.65$s). Comparing with some state-of-the-art localization methods, experimental results confirm that the proposed methods can reliably locate static and moving speakers, in presence of reverberation.
Robust Pitch Estimation and Tracking for Speakers Based on Subband Encoding and the Generalized Labeled Multi-Bernoulli Filter
Apr 02, 2026This paper proposes a new pitch estimator and a novel pitch tracker for speakers. We first decompose the sound signal into subbands using an auditory filterbank, assuming time-frequency sparsity of human speech. Instead of directly selecting the number of subbands according to experience, we propose a novel frequency coverage metric to derive the number of subbands and the center frequencies of the filterbank. The subband signals are then encoded inspired by the computational auditory scene analysis (CASA) approach, and the normalized autocorrelations are calculated for pitch estimation. To suppress spurious errors and track the speaker identity, the temporal continuity constraint is exploited and a Generalized Labeled Multi-Bernoulli (GLMB) filter is adapted for pitch tracking, where we use a novel pitch state transition model based on the Ornstein-Uhlenbeck process, and the measurement driven birth model for adaptive new births of pitch targets. Experimental evaluations with various additive noises demonstrate that the proposed methods have achieved better accuracy compared with several state-of-the-art pitch estimation methods in most studied scenarios. Tests using real recordings in a reverberant room also show that the proposed method is robust against reverberation.
Decoupling Speaker-Independent Emotions for Voice Conversion Via Source-Filter Networks
Oct 04, 2021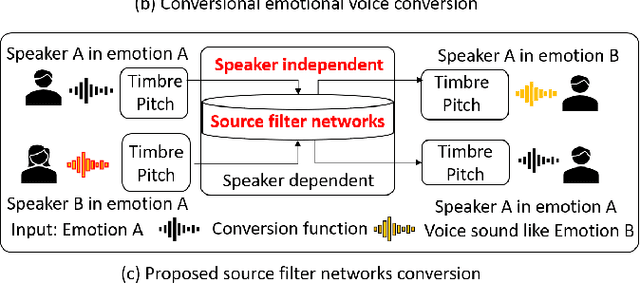
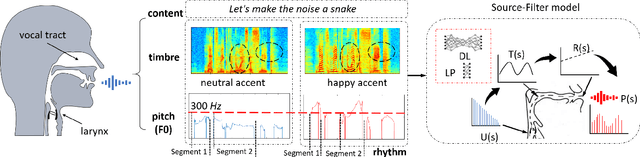
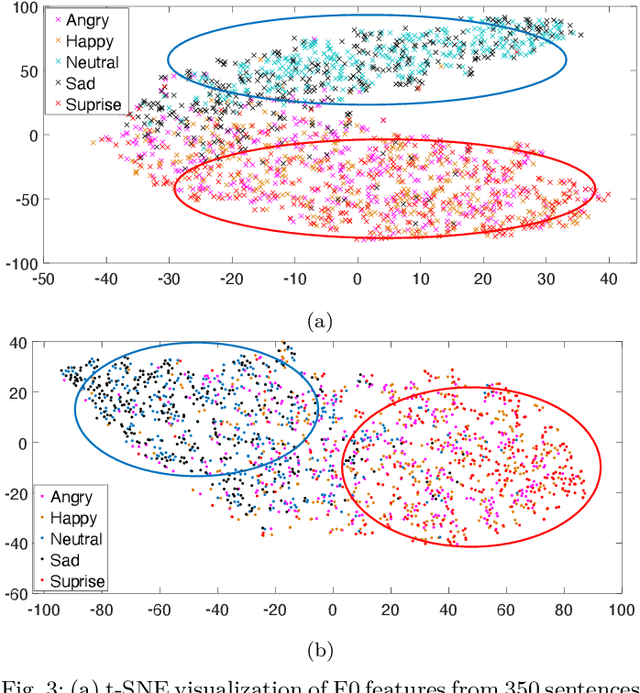
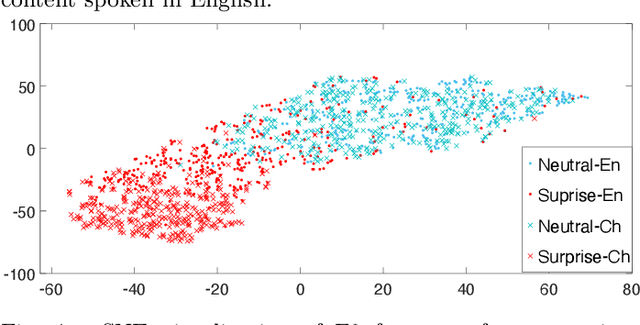
Emotional voice conversion (VC) aims to convert a neutral voice to an emotional (e.g. happy) one while retaining the linguistic information and speaker identity. We note that the decoupling of emotional features from other speech information (such as speaker, content, etc.) is the key to achieving remarkable performance. Some recent attempts about speech representation decoupling on the neutral speech can not work well on the emotional speech, due to the more complex acoustic properties involved in the latter. To address this problem, here we propose a novel Source-Filter-based Emotional VC model (SFEVC) to achieve proper filtering of speaker-independent emotion features from both the timbre and pitch features. Our SFEVC model consists of multi-channel encoders, emotion separate encoders, and one decoder. Note that all encoder modules adopt a designed information bottlenecks auto-encoder. Additionally, to further improve the conversion quality for various emotions, a novel two-stage training strategy based on the 2D Valence-Arousal (VA) space was proposed. Experimental results show that the proposed SFEVC along with a two-stage training strategy outperforms all baselines and achieves the state-of-the-art performance in speaker-independent emotional VC with nonparallel data.