 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Self-Consistency Improve the Recall of Encyclopedic Knowledge?
Apr 21, 2026While self-consistency is known to improve performance on symbolic reasoning, its effect on the recall of encyclopedic knowledge is unclear due to a lack of targeted evaluation grounds. To address this, we establish such a knowledge recall split for the popular MMLU benchmark by applying a data-driven heuristic from prior work. We validate this split by showing that the performance patterns on the symbolic reasoning and knowledge recall subsets mirror those of GSM8K and MedMCQA, respectively. Using this solid ground, we find that self-consistency consistently improves performance across both symbolic reasoning and knowledge recall, even though its underlying CoT prompting is primarily effective for symbolic reasoning. As a result, we achieve an 89\% accuracy on MMLU, the best performance to date with the use of GPT-4o.
FaithCAMERA: Construction of a Faithful Dataset for Ad Text Generation
Oct 04, 2024



In ad text generation (ATG), desirable ad text is both faithful and informative. That is, it should be faithful to the input document, while at the same time containing important information that appeals to potential customers. The existing evaluation data, CAMERA (arXiv:2309.12030), is suitable for evaluating informativeness, as it consists of reference ad texts created by ad creators. However, these references often include information unfaithful to the input, which is a notable obstacle in promoting ATG research. In this study, we collaborate with in-house ad creators to refine the CAMERA references and develop an alternative ATG evaluation dataset called FaithCAMERA, in which the faithfulness of references is guaranteed. Using FaithCAMERA, we can evaluate how well existing methods for improving faithfulness can generate informative ad text while maintaining faithfulness. Our experiments show that removing training data that contains unfaithful entities improves the faithfulness and informativeness at the entity level, but decreases both at the sentence level. This result suggests that for future ATG research, it is essential not only to scale the training data but also to ensure their faithfulness. Our dataset will be publicly available.
A Single Linear Layer Yields Task-Adapted Low-Rank Matrices
Mar 22, 2024



Low-Rank Adaptation (LoRA) is a widely used Parameter-Efficient Fine-Tuning (PEFT) method that updates an initial weight matrix $W_0$ with a delta matrix $\Delta W$ consisted by two low-rank matrices $A$ and $B$. A previous study suggested that there is correlation between $W_0$ and $\Delta W$. In this study, we aim to delve deeper into relationships between $W_0$ and low-rank matrices $A$ and $B$ to further comprehend the behavior of LoRA. In particular, we analyze a conversion matrix that transform $W_0$ into low-rank matrices, which encapsulates information about the relationships. Our analysis reveals that the conversion matrices are similar across each layer. Inspired by these findings, we hypothesize that a single linear layer, which takes each layer's $W_0$ as input, can yield task-adapted low-rank matrices. To confirm this hypothesis, we devise a method named Conditionally Parameterized LoRA (CondLoRA) that updates initial weight matrices with low-rank matrices derived from a single linear layer. Our empirical results show that CondLoRA maintains a performance on par with LoRA, despite the fact that the trainable parameters of CondLoRA are fewer than those of LoRA. Therefore, we conclude that "a single linear layer yields task-adapted low-rank matrices."
Cross-lingual Transfer or Machine Translation? On Data Augmentation for Monolingual Semantic Textual Similarity
Mar 08, 2024



Learning better sentence embeddings leads to improved performance for natural language understanding tasks including semantic textual similarity (STS) and natural language inference (NLI). As prior studies leverage large-scale labeled NLI datasets for fine-tuning masked language models to yield sentence embeddings, task performance for languages other than English is often left behind. In this study, we directly compared two data augmentation techniques as potential solutions for monolingual STS: (a) cross-lingual transfer that exploits English resources alone as training data to yield non-English sentence embeddings as zero-shot inference, and (b) machine translation that coverts English data into pseudo non-English training data in advance. In our experiments on monolingual STS in Japanese and Korean, we find that the two data techniques yield performance on par. Rather, we find a superiority of the Wikipedia domain over the NLI domain for these languages, in contrast to prior studies that focused on NLI as training data. Combining our findings, we demonstrate that the cross-lingual transfer of Wikipedia data exhibits improved performance, and that native Wikipedia data can further improve performance for monolingual STS.
Natural Language Generation for Advertising: A Survey
Jun 22, 2023



Natural language generation methods have emerged as effective tools to help advertisers increase the number of online advertisements they produce. This survey entails a review of the research trends on this topic over the past decade, from template-based to extractive and abstractive approaches using neural networks. Additionally, key challenges and directions revealed through the survey, including metric optimization, faithfulness, diversity, multimodality, and the development of benchmark datasets, are discussed.
Aspect-based Analysis of Advertising Appeals for Search Engine Advertising
Apr 25, 2022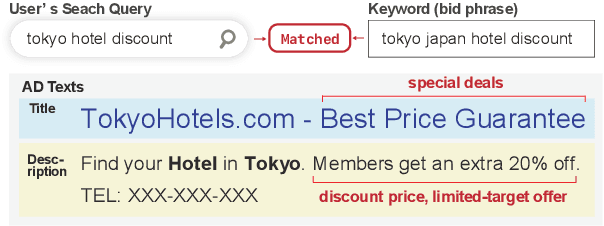
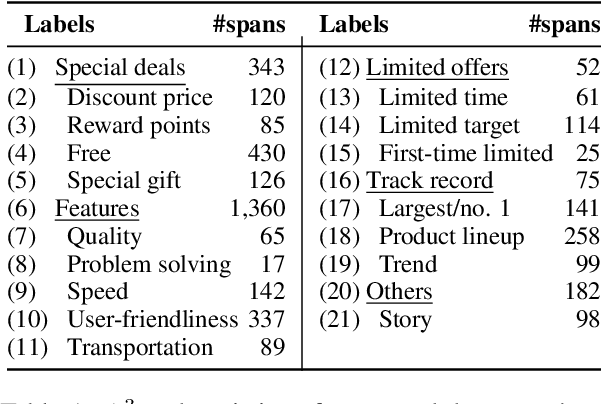
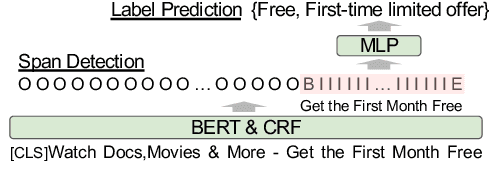
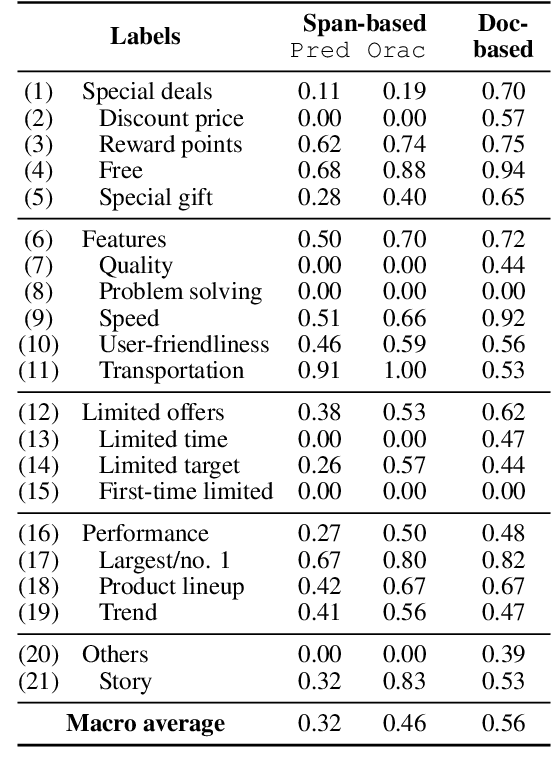
Writing an ad text that attracts people and persuades them to click or act is essential for the success of search engine advertising. Therefore, ad creators must consider various aspects of advertising appeals (A$^3$) such as the price, product features, and quality. However, products and services exhibit unique effective A$^3$ for different industries. In this work, we focus on exploring the effective A$^3$ for different industries with the aim of assisting the ad creation process. To this end, we created a dataset of advertising appeals and used an existing model that detects various aspects for ad texts. Our experiments demonstrated that different industries have their own effective A$^3$ and that the identification of the A$^3$ contributes to the estimation of advertising performance.