 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReshoot-Anything: A Self-Supervised Model for In-the-Wild Video Reshooting
Apr 23, 2026Precise camera control for reshooting dynamic videos is bottlenecked by the severe scarcity of paired multi-view data for non-rigid scenes. We overcome this limitation with a highly scalable self-supervised framework capable of leveraging internet-scale monocular videos. Our core contribution is the generation of pseudo multi-view training triplets, consisting of a source video, a geometric anchor, and a target video. We achieve this by extracting distinct smooth random-walk crop trajectories from a single input video to serve as the source and target views. The anchor is synthetically generated by forward-warping the first frame of the source with a dense tracking field, which effectively simulates the distorted point-cloud inputs expected at inference. Because our independent cropping strategy introduces spatial misalignment and artificial occlusions, the model cannot simply copy information from the current source frame. Instead, it is forced to implicitly learn 4D spatiotemporal structures by actively routing and re-projecting missing high-fidelity textures across distinct times and viewpoints from the source video to reconstruct the target. At inference, our minimally adapted diffusion transformer utilizes a 4D point-cloud derived anchor to achieve state-of-the-art temporal consistency, robust camera control, and high-fidelity novel view synthesis on complex dynamic scenes.
A Generalized Motion Pattern and FCN based approach for retinal fluid detection and segmentation
Dec 04, 2017
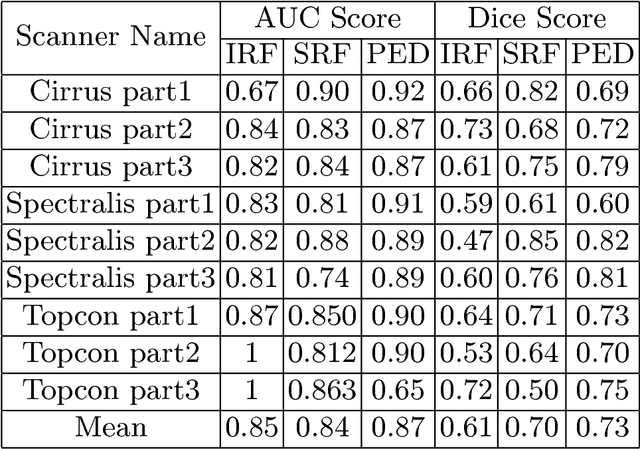
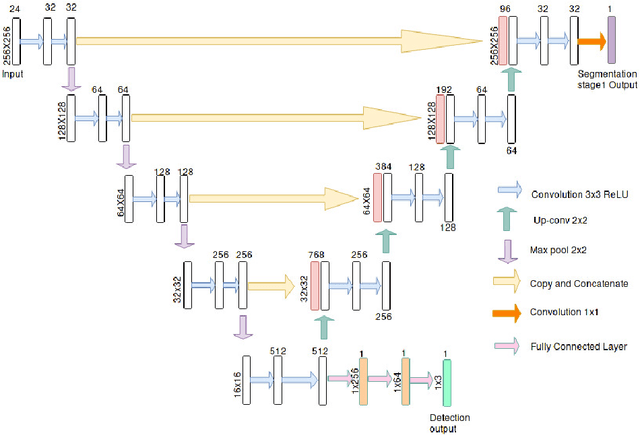
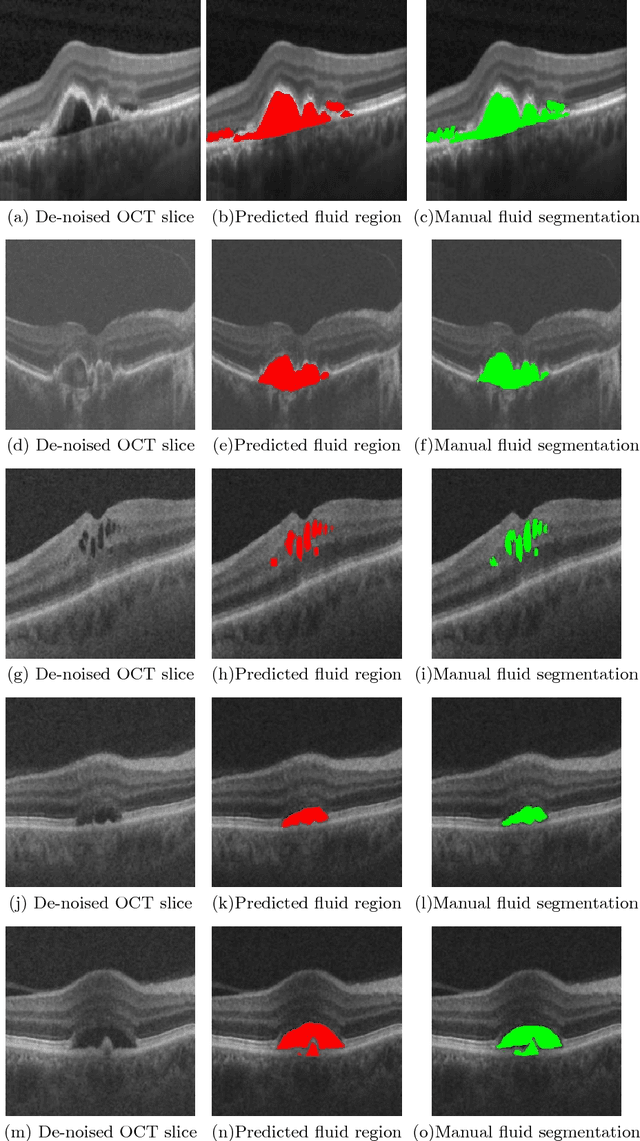
SD-OCT is a non-invasive cross-sectional imaging modality used for diagnosis of macular defects. Efficient detection and segmentation of the abnormalities seen as biomarkers in OCT can help in analyzing the progression of the disease and advising effective treatment for the associated disease. In this work, we propose a fully automated Generalized Motion Pattern(GMP) based segmentation method using a cascade of fully convolutional networks for detection and segmentation of retinal fluids from SD-OCT scans. General methods for segmentation depend on domain knowledge-based feature extraction, whereas we propose a method based on Generalized Motion Pattern (GMP) which is derived by inducing motion to an image to suppress the background.The proposed method is parallelizable and handles inter-scanner variability efficiently. Our method achieves a mean Dice score of 0.61,0.70 and 0.73 during segmentation and a mean AUC of 0.85,0.84 and 0.87 during detection for the 3 types of fluids IRF, SRF and PDE respectively.