 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat can human minimal videos tell us about dynamic recognition models?
Apr 19, 2021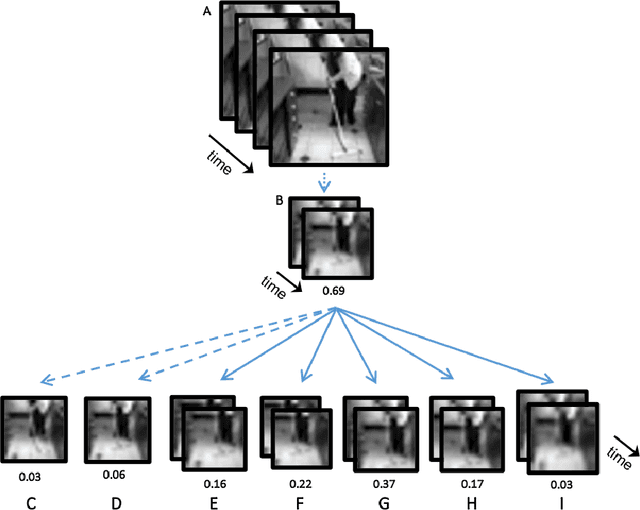

In human vision objects and their parts can be visually recognized from purely spatial or purely temporal information but the mechanisms integrating space and time are poorly understood. Here we show that human visual recognition of objects and actions can be achieved by efficiently combining spatial and motion cues in configurations where each source on its own is insufficient for recognition. This analysis is obtained by identifying minimal videos: these are short and tiny video clips in which objects, parts, and actions can be reliably recognized, but any reduction in either space or time makes them unrecognizable. State-of-the-art deep networks for dynamic visual recognition cannot replicate human behavior in these configurations. This gap between humans and machines points to critical mechanisms in human dynamic vision that are lacking in current models.
What takes the brain so long: Object recognition at the level of minimal images develops for up to seconds of presentation time
Jun 09, 2020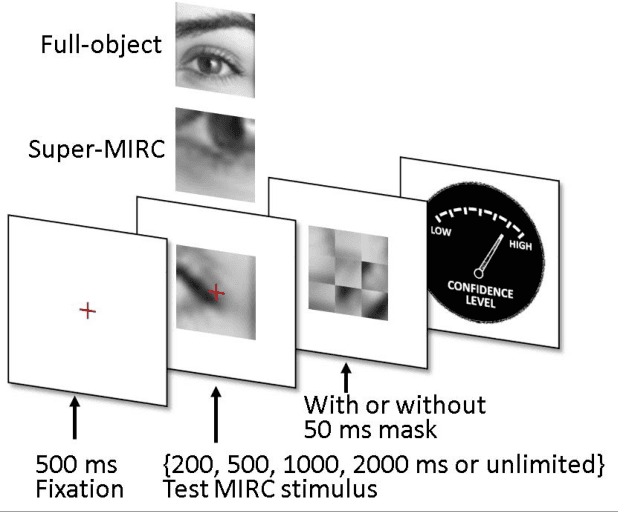
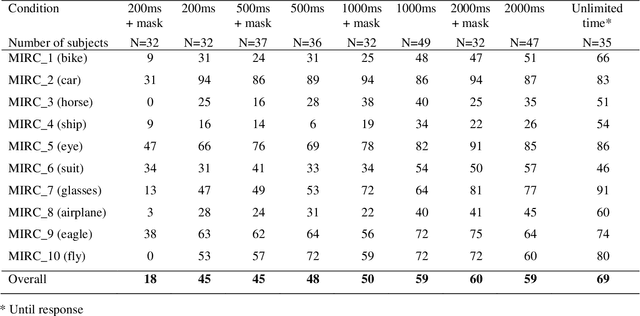
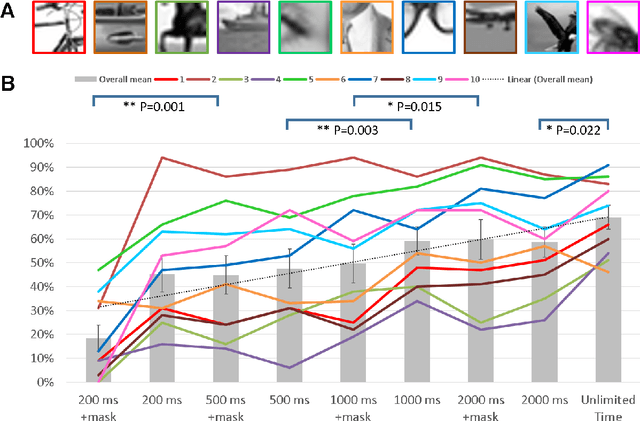
Rich empirical evidence has shown that visual object recognition in the brain is fast and effortless, with relevant brain signals reported to start as early as 80 ms. Here we study the time trajectory of the recognition process at the level of minimal recognizable images (termed MIRC). These are images that can be recognized reliably, but in which a minute change of the image (reduction by either size or resolution) has a drastic effect on recognition. Subjects were assigned to one of nine exposure conditions: 200, 500, 1000, 2000 ms with or without masking, as well as unlimited time. The subjects were not limited in time to respond after presentation. The results show that in the masked conditions, recognition rates develop gradually over an extended period, e.g. average of 18% for 200 ms exposure and 45% for 500 ms, increasing significantly with longer exposure even above 2 secs. When presented for unlimited time (until response), MIRC recognition rates were equivalent to the rates of full-object images presented for 50 ms followed by masking. What takes the brain so long to recognize such images? We discuss why processes involving eye-movements, perceptual decision-making and pattern completion are unlikely explanations. Alternatively, we hypothesize that MIRC recognition requires an extended top-down process complementing the feed-forward phase.
Multi-Task Learning by a Top-Down Control Network
Feb 23, 2020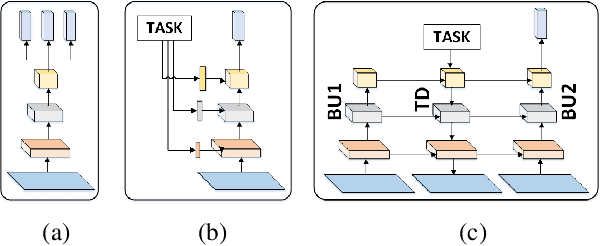
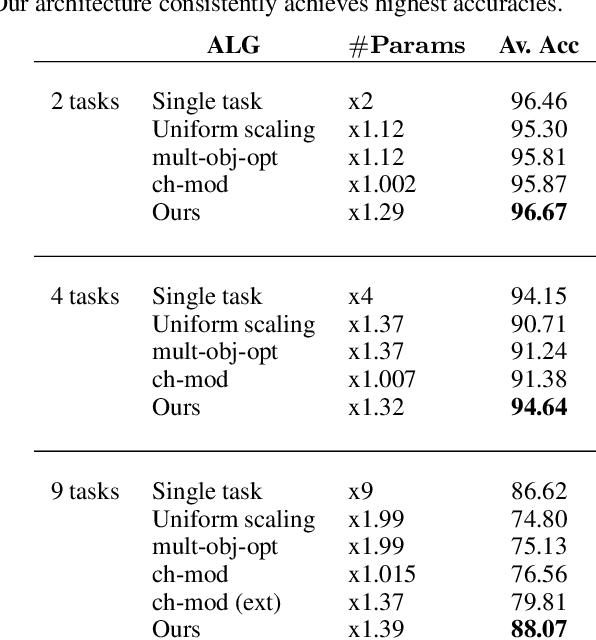


A general problem that received considerable recent attention is how to perform multiple tasks in the same network, maximizing both prediction accuracy and efficiency of training. Recent approaches address this problem by branching networks, or by a channel-wise modulation of the feature-maps with task specific vectors. We propose a novel architecture that uses a top-down network to modify the main network according to the task in a channel-wise, as well as spatial-wise, image-dependent computation scheme. We show the effectiveness of our scheme by achieving better results than alternative state-of-the-art approaches to multi-task learning. We also demonstrate our advantages in terms of task selectivity, scaling the number of tasks, learning from fewer examples and interpretability.
Efficient Coarse-to-Fine Non-Local Module for the Detection of Small Objects
Nov 29, 2018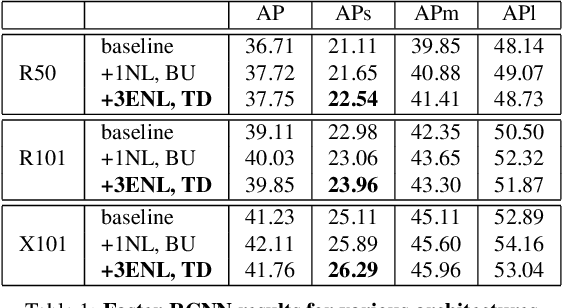

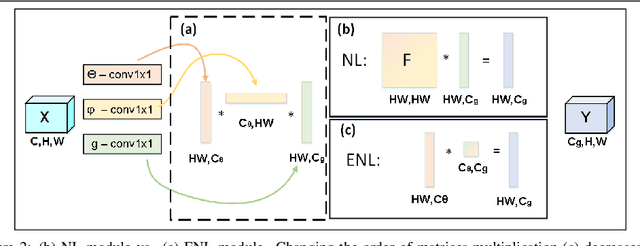
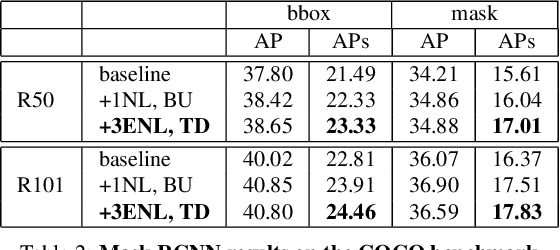
An image is not just a collection of objects, but rather a graph where each object is related to other objects through spatial and semantic relations. Using relational reasoning modules, allowing message passing between objects, can therefore improve object detection. Current schemes apply such dedicated modules either on a specific layer of the bottom-up stream, or between already-detected objects. We show that the relational process can be better modeled in a coarse to fine manner and present a novel framework, applying a non-local module sequentially to increasing resolution feature-maps along the top-down stream. In this way, the inner relational process can naturally pass information from larger objects to smaller related ones. Applying the modules to fine feature-maps also allows message passing between the small objects themselves, exploiting repetitions of instances from of the same class. In practice, due to the expensive memory utilization of the non-local module, it is unfeasible to apply the module as currently used to high-resolution feature-maps. We efficiently redesigned the non local module, improved it in terms of memory and number of operations, allowing it to be placed anywhere along the network. We also incorporated relative spatial information into the module, in a manner that can be incorporated into our efficient implementation. We show the effectiveness of our scheme by improving the results of detecting small objects on COCO by 1.5 AP over Faster RCNN and by 1 AP over using non-local module on the bottom-up stream.
VQA with no questions-answers training
Nov 20, 2018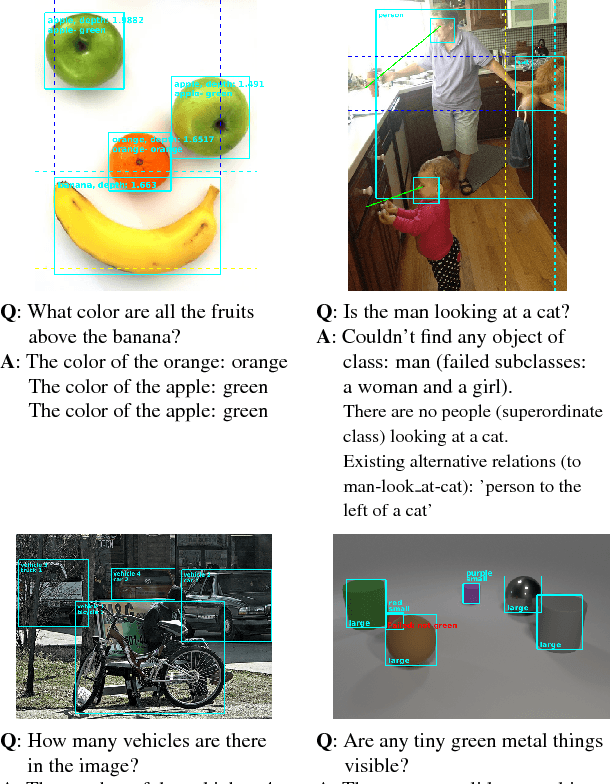
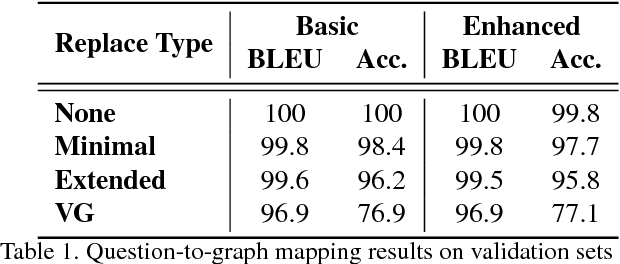
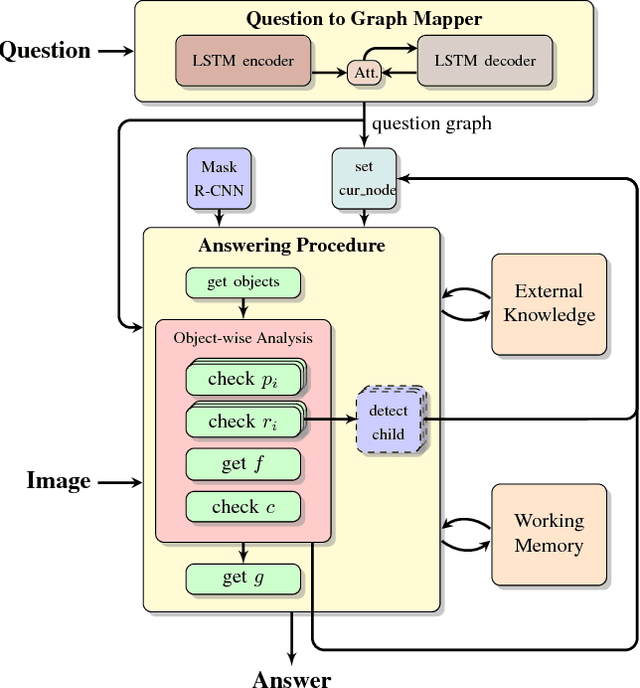
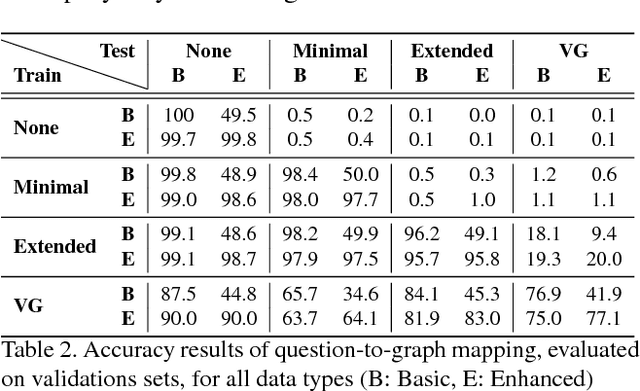
Methods for teaching machines to answer visual questions have made significant progress in the last few years, but although demonstrating impressive results on particular datasets, these methods lack some important human capabilities, including integrating new visual classes and concepts in a modular manner, providing explanations for the answer and handling new domains without new examples. In this paper we present a system that achieves state-of-the-art results on the CLEVR dataset without any questions-answers training, utilizes real visual estimators and explains the answer. The system includes a question representation stage followed by an answering procedure, which invokes an extendable set of visual estimators. It can explain the answer, including its failures, and provide alternatives to negative answers. The scheme builds upon a framework proposed recently, with extensions allowing the system to deal with novel domains without relying on training examples.
Understand, Compose and Respond - Answering Visual Questions by a Composition of Abstract Procedures
Oct 25, 2018
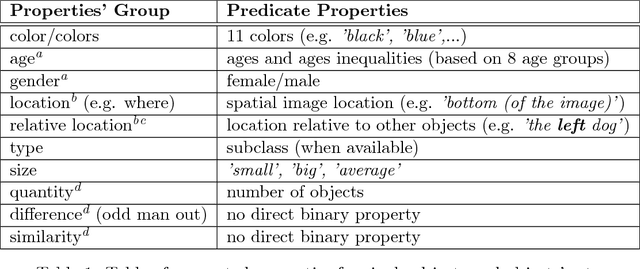
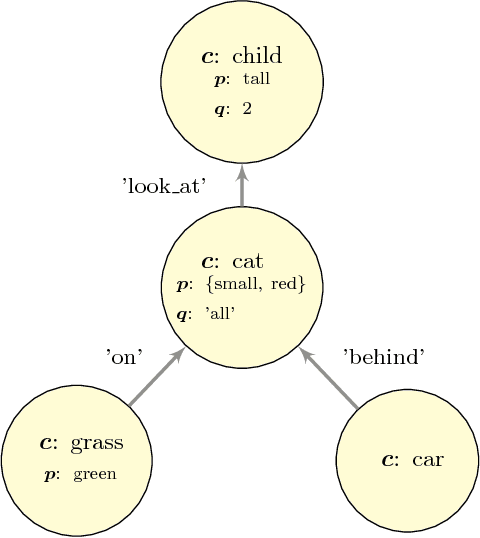
An image related question defines a specific visual task that is required in order to produce an appropriate answer. The answer may depend on a minor detail in the image and require complex reasoning and use of prior knowledge. When humans perform this task, they are able to do it in a flexible and robust manner, integrating modularly any novel visual capability with diverse options for various elaborations of the task. In contrast, current approaches to solve this problem by a machine are based on casting the problem as an end-to-end learning problem, which lacks such abilities. We present a different approach, inspired by the aforementioned human capabilities. The approach is based on the compositional structure of the question. The underlying idea is that a question has an abstract representation based on its structure, which is compositional in nature. The question can consequently be answered by a composition of procedures corresponding to its substructures. The basic elements of the representation are logical patterns, which are put together to represent the question. These patterns include a parametric representation for object classes, properties and relations. Each basic pattern is mapped into a basic procedure that includes meaningful visual tasks, and the patterns are composed to produce the overall answering procedure. The UnCoRd (Understand Compose and Respond) system, based on this approach, integrates existing detection and classification schemes for a set of object classes, properties and relations. These schemes are incorporated in a modular manner, providing elaborated answers and corrections for negative answers. In addition, an external knowledge base is queried for required common-knowledge. We performed a qualitative analysis of the system, which demonstrates its representation capabilities and provide suggestions for future developments.
Large Field and High Resolution: Detecting Needle in Haystack
Apr 10, 2018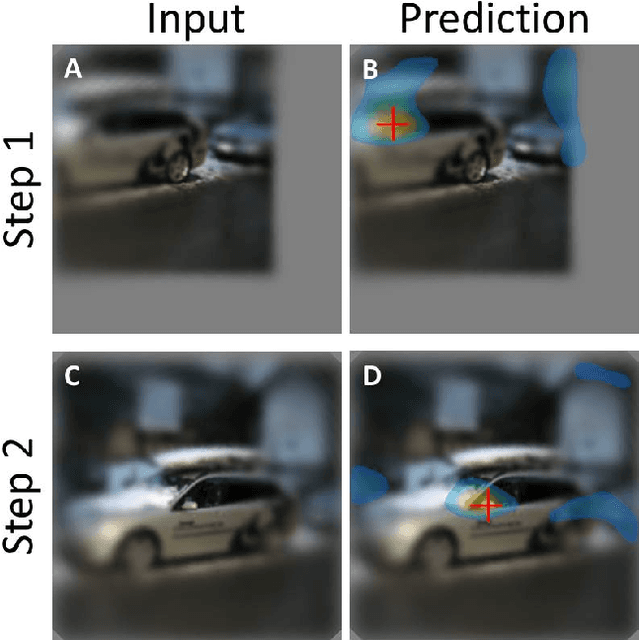

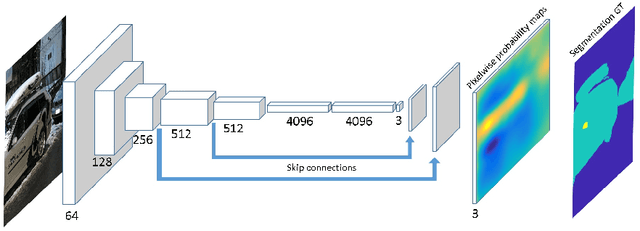
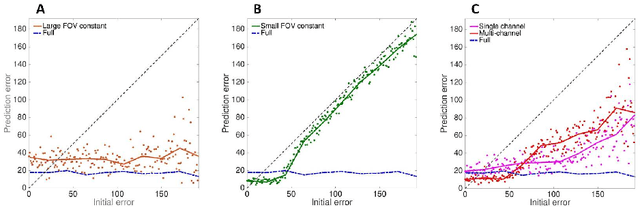
The growing use of convolutional neural networks (CNN) for a broad range of visual tasks, including tasks involving fine details, raises the problem of applying such networks to a large field of view, since the amount of computations increases significantly with the number of pixels. To deal effectively with this difficulty, we develop and compare methods of using CNNs for the task of small target localization in natural images, given a limited "budget" of samples to form an image. Inspired in part by human vision, we develop and compare variable sampling schemes, with peak resolution at the center and decreasing resolution with eccentricity, applied iteratively by re-centering the image at the previous predicted target location. The results indicate that variable resolution models significantly outperform constant resolution models. Surprisingly, variable resolution models and in particular multi-channel models, outperform the optimal, "budget-free" full-resolution model, using only 5\% of the samples.
Discovery and usage of joint attention in images
Apr 10, 2018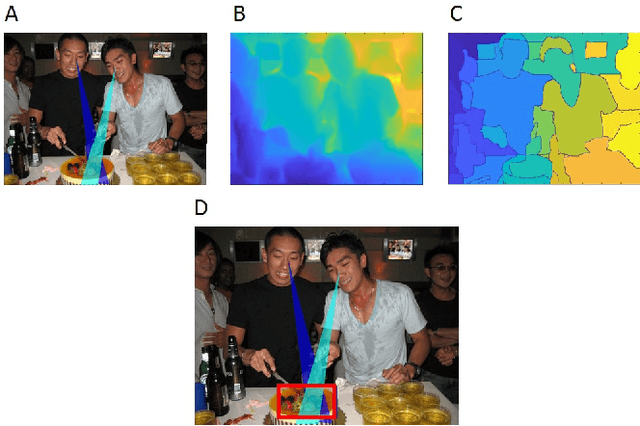


Joint visual attention is characterized by two or more individuals looking at a common target at the same time. The ability to identify joint attention in scenes, the people involved, and their common target, is fundamental to the understanding of social interactions, including others' intentions and goals. In this work we deal with the extraction of joint attention events, and the use of such events for image descriptions. The work makes two novel contributions. First, our extraction algorithm is the first which identifies joint visual attention in single static images. It computes 3D gaze direction, identifies the gaze target by combining gaze direction with a 3D depth map computed for the image, and identifies the common gaze target. Second, we use a human study to demonstrate the sensitivity of humans to joint attention, suggesting that the detection of such a configuration in an image can be useful for understanding the image, including the goals of the agents and their joint activity, and therefore can contribute to image captioning and related tasks.
Action Classification via Concepts and Attributes
Mar 07, 2018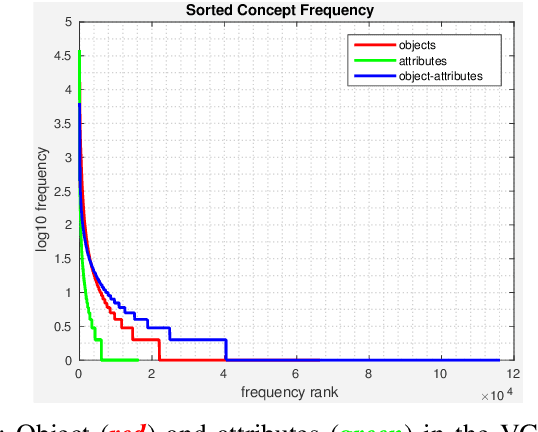
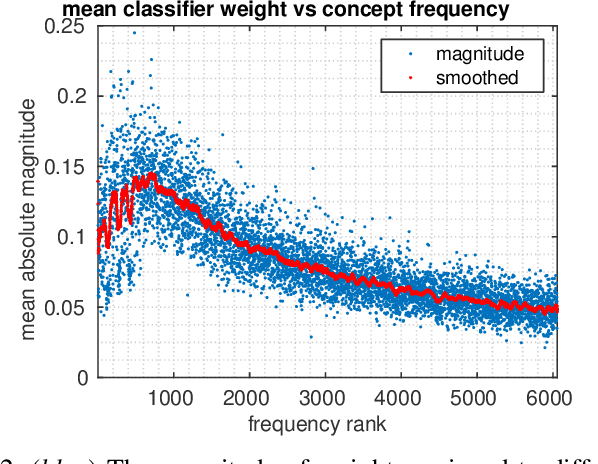
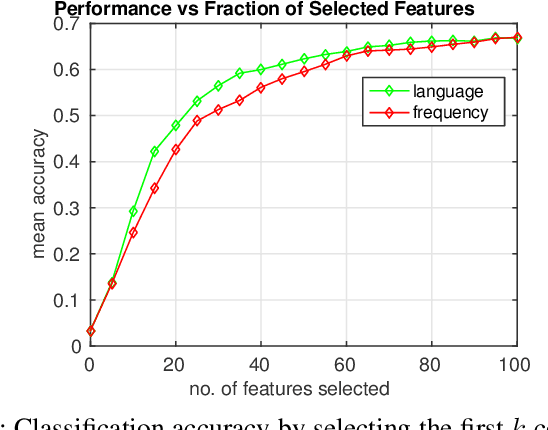
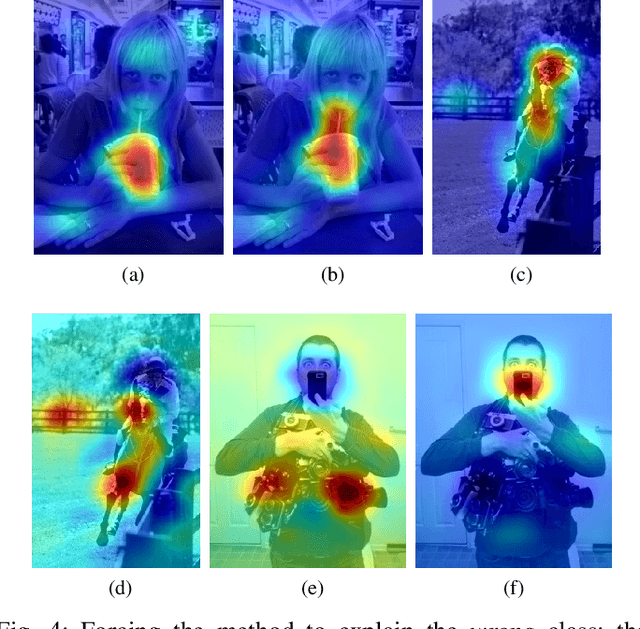
Classes in natural images tend to follow long tail distributions. This is problematic when there are insufficient training examples for rare classes. This effect is emphasized in compound classes, involving the conjunction of several concepts, such as those appearing in action-recognition datasets. In this paper, we propose to address this issue by learning how to utilize common visual concepts which are readily available. We detect the presence of prominent concepts in images and use them to infer the target labels instead of using visual features directly, combining tools from vision and natural-language processing. We validate our method on the recently introduced HICO dataset reaching a mAP of 31.54\% and on the Stanford-40 Actions dataset, where the proposed method outperforms that obtained by direct visual features, obtaining an accuracy 83.12\%. Moreover, the method provides for each class a semantically meaningful list of keywords and relevant image regions relating it to its constituent concepts.
Cakewalk Sampling
Feb 25, 2018



Combinatorial optimization is a common theme in computer science which underlies a considerable variety of problems. In contrast to the continuous setting, combinatorial problems require special solution strategies, and it's hard to come by generic schemes like gradient methods for continuous domains. We follow a standard construction of a parametric sampling distribution that transforms the problem to the continuous domain, allowing us to optimize the expectation of a given objective using estimates of the gradient. In spite of the apparent generality, such constructions are known to suffer from highly variable gradient estimates, and thus require careful tuning that is done in a problem specific manner. We show that a simple trick of converting the objective values to their cumulative probabilities fixes the distribution of the objective, allowing us to derive an online optimization algorithm that can be applied in a generic fashion. As an experimental benchmark we use the task of finding cliques in undirected graphs, and we show that our method, even when blindly applied, consistently outperforms related methods. Notably, on the DIMACS clique benchmark, our method approaches the performance of the best clique finding algorithms without access to the graph structure, and only through objective function evaluations, thus providing significant evidence to the generality and effectivity of our method.