 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOR: Finetuning for Object Level Open Vocabulary Image Retrieval
Dec 25, 2024



As working with large datasets becomes standard, the task of accurately retrieving images containing objects of interest by an open set textual query gains practical importance. The current leading approach utilizes a pre-trained CLIP model without any adaptation to the target domain, balancing accuracy and efficiency through additional post-processing. In this work, we propose FOR: Finetuning for Object-centric Open-vocabulary Image Retrieval, which allows finetuning on a target dataset using closed-set labels while keeping the visual-language association crucial for open vocabulary retrieval. FOR is based on two design elements: a specialized decoder variant of the CLIP head customized for the intended task, and its coupling within a multi-objective training framework. Together, these design choices result in a significant increase in accuracy, showcasing improvements of up to 8 mAP@50 points over SoTA across three datasets. Additionally, we demonstrate that FOR is also effective in a semi-supervised setting, achieving impressive results even when only a small portion of the dataset is labeled.
Object-Centric Open-Vocabulary Image-Retrieval with Aggregated Features
Sep 26, 2023



The task of open-vocabulary object-centric image retrieval involves the retrieval of images containing a specified object of interest, delineated by an open-set text query. As working on large image datasets becomes standard, solving this task efficiently has gained significant practical importance. Applications include targeted performance analysis of retrieved images using ad-hoc queries and hard example mining during training. Recent advancements in contrastive-based open vocabulary systems have yielded remarkable breakthroughs, facilitating large-scale open vocabulary image retrieval. However, these approaches use a single global embedding per image, thereby constraining the system's ability to retrieve images containing relatively small object instances. Alternatively, incorporating local embeddings from detection pipelines faces scalability challenges, making it unsuitable for retrieval from large databases. In this work, we present a simple yet effective approach to object-centric open-vocabulary image retrieval. Our approach aggregates dense embeddings extracted from CLIP into a compact representation, essentially combining the scalability of image retrieval pipelines with the object identification capabilities of dense detection methods. We show the effectiveness of our scheme to the task by achieving significantly better results than global feature approaches on three datasets, increasing accuracy by up to 15 mAP points. We further integrate our scheme into a large scale retrieval framework and demonstrate our method's advantages in terms of scalability and interpretability.
Multi-Task Learning by a Top-Down Control Network
Feb 23, 2020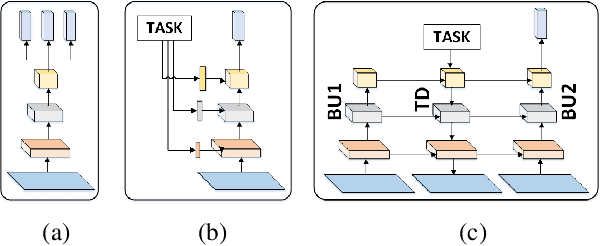
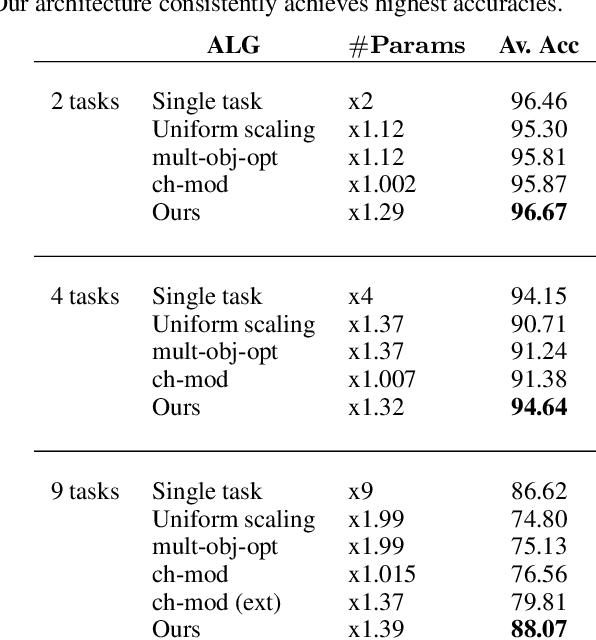


A general problem that received considerable recent attention is how to perform multiple tasks in the same network, maximizing both prediction accuracy and efficiency of training. Recent approaches address this problem by branching networks, or by a channel-wise modulation of the feature-maps with task specific vectors. We propose a novel architecture that uses a top-down network to modify the main network according to the task in a channel-wise, as well as spatial-wise, image-dependent computation scheme. We show the effectiveness of our scheme by achieving better results than alternative state-of-the-art approaches to multi-task learning. We also demonstrate our advantages in terms of task selectivity, scaling the number of tasks, learning from fewer examples and interpretability.
Efficient Coarse-to-Fine Non-Local Module for the Detection of Small Objects
Nov 29, 2018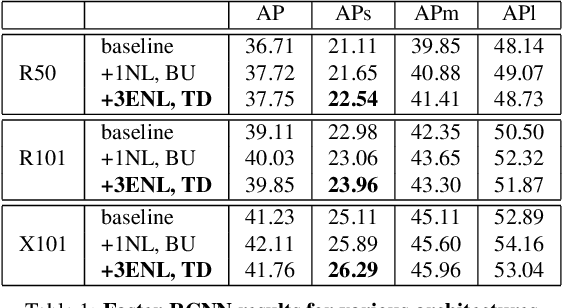

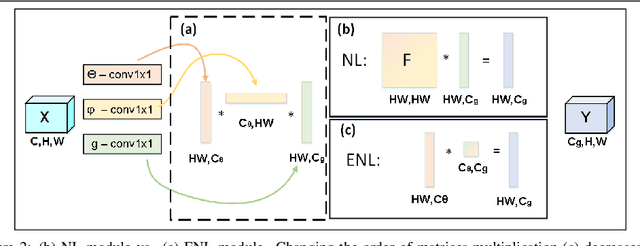
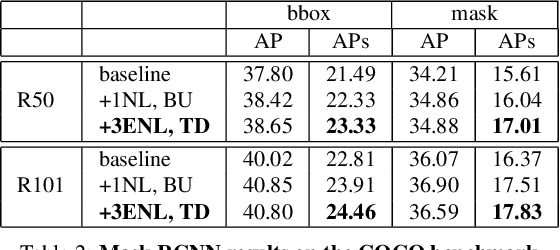
An image is not just a collection of objects, but rather a graph where each object is related to other objects through spatial and semantic relations. Using relational reasoning modules, allowing message passing between objects, can therefore improve object detection. Current schemes apply such dedicated modules either on a specific layer of the bottom-up stream, or between already-detected objects. We show that the relational process can be better modeled in a coarse to fine manner and present a novel framework, applying a non-local module sequentially to increasing resolution feature-maps along the top-down stream. In this way, the inner relational process can naturally pass information from larger objects to smaller related ones. Applying the modules to fine feature-maps also allows message passing between the small objects themselves, exploiting repetitions of instances from of the same class. In practice, due to the expensive memory utilization of the non-local module, it is unfeasible to apply the module as currently used to high-resolution feature-maps. We efficiently redesigned the non local module, improved it in terms of memory and number of operations, allowing it to be placed anywhere along the network. We also incorporated relative spatial information into the module, in a manner that can be incorporated into our efficient implementation. We show the effectiveness of our scheme by improving the results of detecting small objects on COCO by 1.5 AP over Faster RCNN and by 1 AP over using non-local module on the bottom-up stream.
Deep Multi-Spectral Registration Using Invariant Descriptor Learning
May 23, 2018
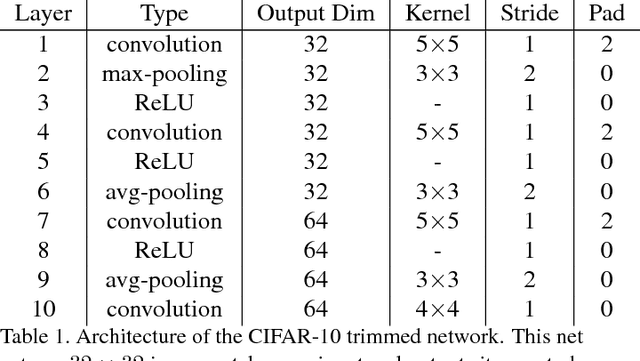
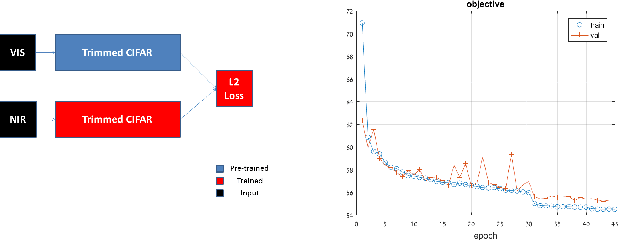

In this paper, we introduce a novel deep-learning method to align cross-spectral images. Our approach relies on a learned descriptor which is invariant to different spectra. Multi-modal images of the same scene capture different signals and therefore their registration is challenging and it is not solved by classic approaches. To that end, we developed a feature-based approach that solves the visible (VIS) to Near-Infra-Red (NIR) registration problem. Our algorithm detects corners by Harris and matches them by a patch-metric learned on top of CIFAR-10 network descriptor. As our experiments demonstrate we achieve a high-quality alignment of cross-spectral images with a sub-pixel accuracy. Comparing to other existing methods, our approach is more accurate in the task of VIS to NIR registration.