 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Apprenticeship Learning
Feb 13, 2021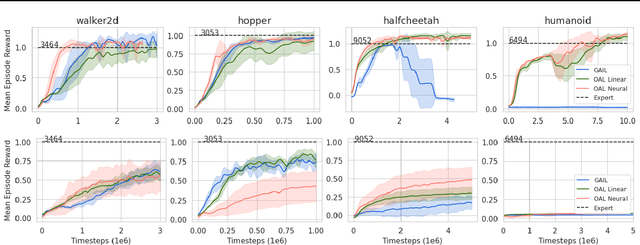
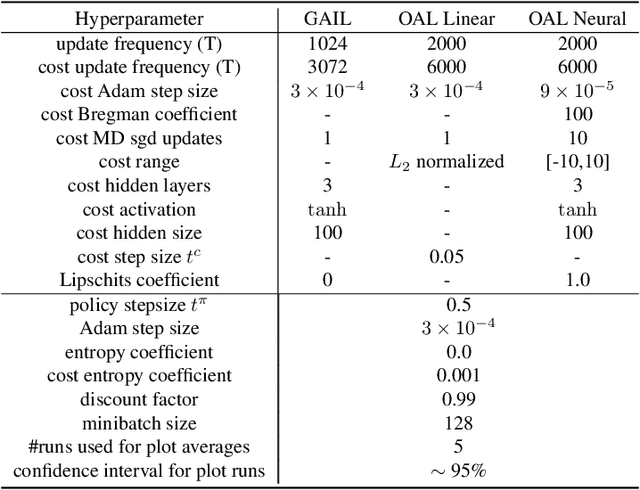
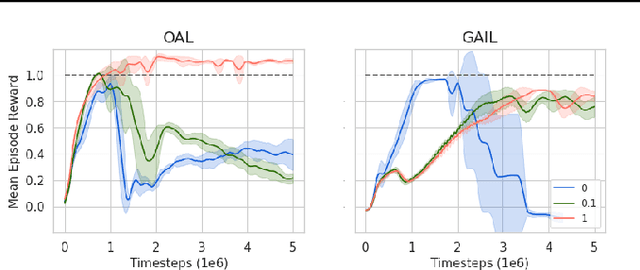
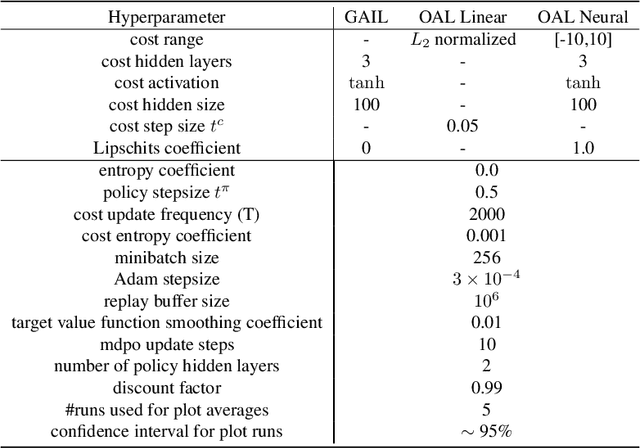
In Apprenticeship Learning (AL), we are given a Markov Decision Process (MDP) without access to the cost function. Instead, we observe trajectories sampled by an expert that acts according to some policy. The goal is to find a policy that matches the expert's performance on some predefined set of cost functions. We introduce an online variant of AL (Online Apprenticeship Learning; OAL), where the agent is expected to perform comparably to the expert while interacting with the environment. We show that the OAL problem can be effectively solved by combining two mirror descent based no-regret algorithms: one for policy optimization and another for learning the worst case cost. To this end, we derive a convergent algorithm with $O(\sqrt{K})$ regret, where $K$ is the number of interactions with the MDP, and an additional linear error term that depends on the amount of expert trajectories available. Importantly, our algorithm avoids the need to solve an MDP at each iteration, making it more practical compared to prior AL methods. Finally, we implement a deep variant of our algorithm which shares some similarities to GAIL \cite{ho2016generative}, but where the discriminator is replaced with the costs learned by the OAL problem. Our simulations demonstrate our theoretically grounded approach outperforms the baselines.
RL for Latent MDPs: Regret Guarantees and a Lower Bound
Feb 09, 2021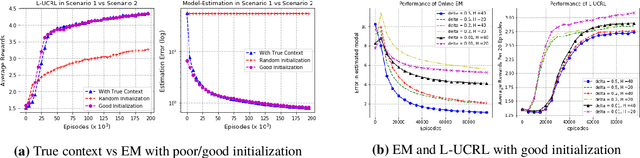
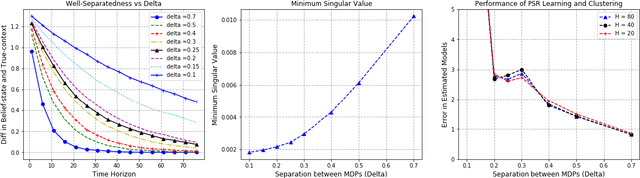
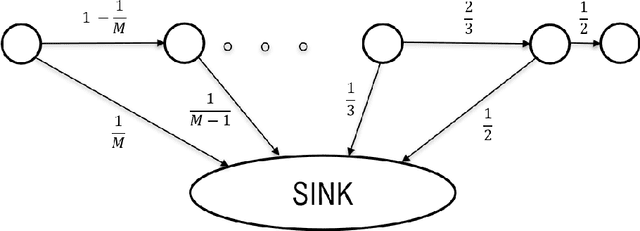
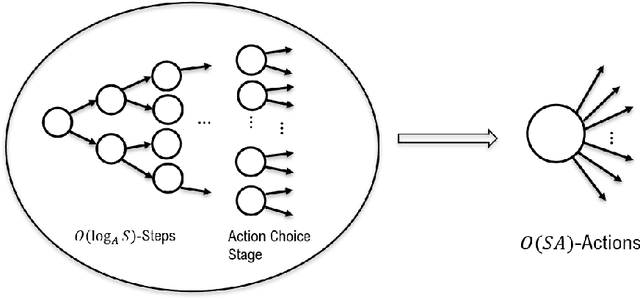
In this work, we consider the regret minimization problem for reinforcement learning in latent Markov Decision Processes (LMDP). In an LMDP, an MDP is randomly drawn from a set of $M$ possible MDPs at the beginning of the interaction, but the identity of the chosen MDP is not revealed to the agent. We first show that a general instance of LMDPs requires at least $\Omega((SA)^M)$ episodes to even approximate the optimal policy. Then, we consider sufficient assumptions under which learning good policies requires polynomial number of episodes. We show that the key link is a notion of separation between the MDP system dynamics. With sufficient separation, we provide an efficient algorithm with local guarantee, {\it i.e.,} providing a sublinear regret guarantee when we are given a good initialization. Finally, if we are given standard statistical sufficiency assumptions common in the Predictive State Representation (PSR) literature (e.g., Boots et al.) and a reachability assumption, we show that the need for initialization can be removed.
Dimension Free Generalization Bounds for Non Linear Metric Learning
Feb 07, 2021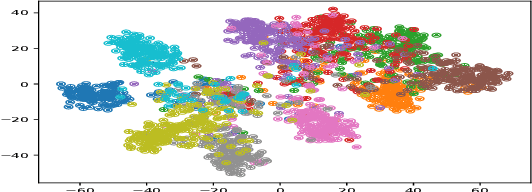
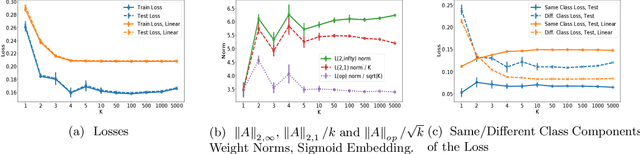
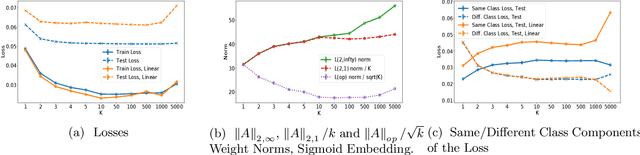
In this work we study generalization guarantees for the metric learning problem, where the metric is induced by a neural network type embedding of the data. Specifically, we provide uniform generalization bounds for two regimes -- the sparse regime, and a non-sparse regime which we term \emph{bounded amplification}. The sparse regime bounds correspond to situations where $\ell_1$-type norms of the parameters are small. Similarly to the situation in classification, solutions satisfying such bounds can be obtained by an appropriate regularization of the problem. On the other hand, unregularized SGD optimization of a metric learning loss typically does not produce sparse solutions. We show that despite this lack of sparsity, by relying on a different, new property of the solutions, it is still possible to provide dimension free generalization guarantees. Consequently, these bounds can explain generalization in non sparse real experimental situations. We illustrate the studied phenomena on the MNIST and 20newsgroups datasets.
Online Limited Memory Neural-Linear Bandits with Likelihood Matching
Feb 07, 2021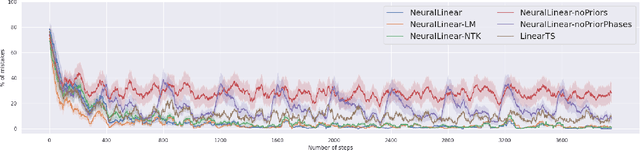
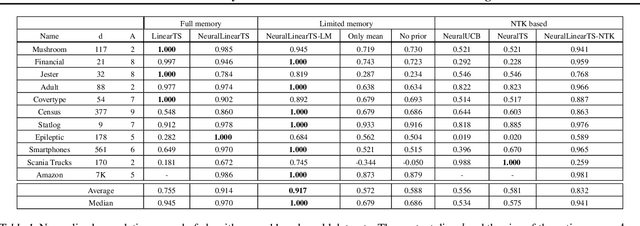
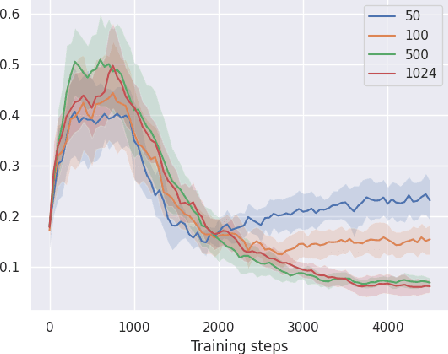
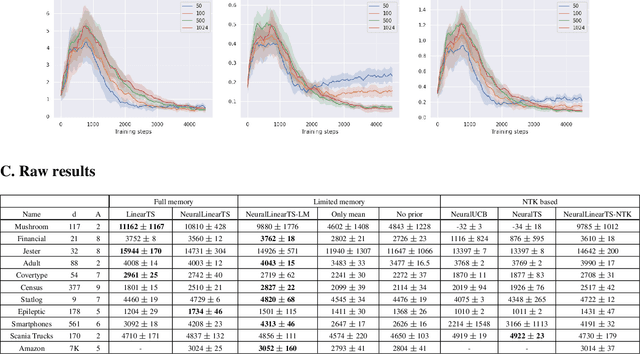
We study neural-linear bandits for solving problems where both exploration and representation learning play an important role. Neural-linear bandits leverage the representation power of Deep Neural Networks (DNNs) and combine it with efficient exploration mechanisms designed for linear contextual bandits on top of the last hidden layer. A recent analysis of DNNs in the "infinite-width" regime suggests that when these models are trained with gradient descent the optimal solution is close to the initialization point and the DNN can be viewed as a kernel machine. As a result, it is possible to exploit linear exploration algorithms on top of a DNN via the kernel construction. The problem is that in practice the kernel changes during the learning process and the agent's performance degrades. This can be resolved by recomputing new uncertainty estimations with stored data. Nevertheless, when the buffer's size is limited, a phenomenon called catastrophic forgetting emerges. Instead, we propose a likelihood matching algorithm that is resilient to catastrophic forgetting and is completely online. We perform simulations on a variety of datasets and observe that our algorithm achieves comparable performance to the unlimited memory approach while exhibits resilience to catastrophic forgetting.
Confidence-Budget Matching for Sequential Budgeted Learning
Feb 05, 2021A core element in decision-making under uncertainty is the feedback on the quality of the performed actions. However, in many applications, such feedback is restricted. For example, in recommendation systems, repeatedly asking the user to provide feedback on the quality of recommendations will annoy them. In this work, we formalize decision-making problems with querying budget, where there is a (possibly time-dependent) hard limit on the number of reward queries allowed. Specifically, we consider multi-armed bandits, linear bandits, and reinforcement learning problems. We start by analyzing the performance of `greedy' algorithms that query a reward whenever they can. We show that in fully stochastic settings, doing so performs surprisingly well, but in the presence of any adversity, this might lead to linear regret. To overcome this issue, we propose the Confidence-Budget Matching (CBM) principle that queries rewards when the confidence intervals are wider than the inverse square root of the available budget. We analyze the performance of CBM based algorithms in different settings and show that they perform well in the presence of adversity in the contexts, initial states, and budgets.
Acting in Delayed Environments with Non-Stationary Markov Policies
Jan 28, 2021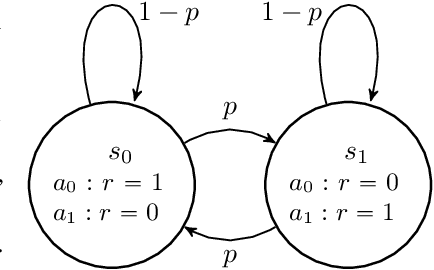

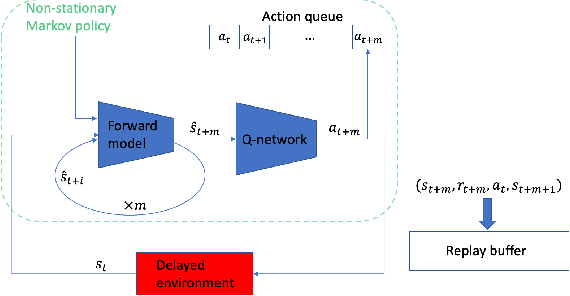
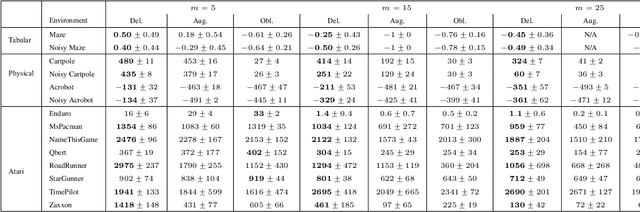
The standard Markov Decision Process (MDP) formulation hinges on the assumption that an action is executed immediately after it was chosen. However, assuming it is often unrealistic and can lead to catastrophic failures in applications such as robotic manipulation, cloud computing, and finance. We introduce a framework for learning and planning in MDPs where the decision-maker commits actions that are executed with a delay of $m$ steps. The brute-force state augmentation baseline where the state is concatenated to the last $m$ committed actions suffers from an exponential complexity in $m$, as we show for policy iteration. We then prove that with execution delay, Markov policies in the original state-space are sufficient for attaining maximal reward, but need to be non-stationary. As for stationary Markov policies, we show they are sub-optimal in general. Consequently, we devise a non-stationary Q-learning style model-based algorithm that solves delayed execution tasks without resorting to state-augmentation. Experiments on tabular, physical, and Atari domains reveal that it converges quickly to high performance even for substantial delays, while standard approaches that either ignore the delay or rely on state-augmentation struggle or fail due to divergence. The code is available at https://github.com/galdl/rl_delay_basic.git.
The Architectural Implications of Distributed Reinforcement Learning on CPU-GPU Systems
Dec 08, 2020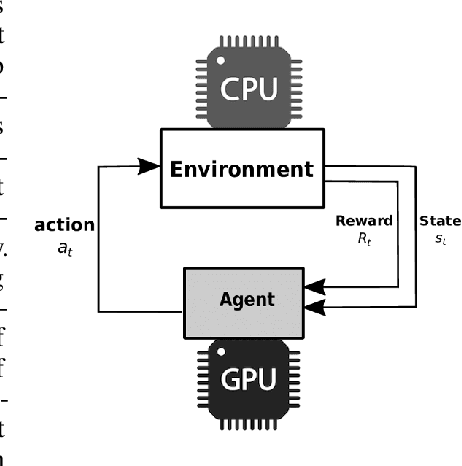
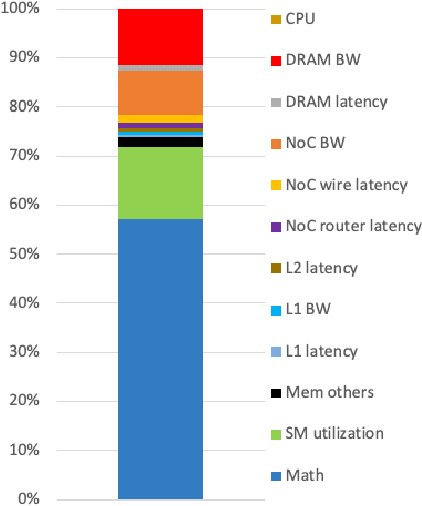
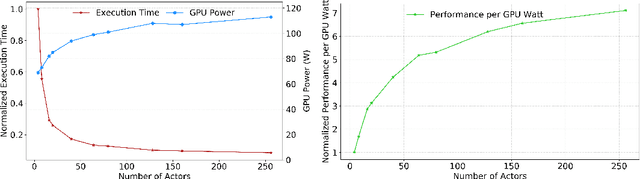
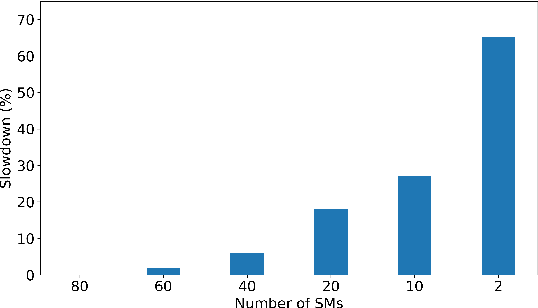
With deep reinforcement learning (RL) methods achieving results that exceed human capabilities in games, robotics, and simulated environments, continued scaling of RL training is crucial to its deployment in solving complex real-world problems. However, improving the performance scalability and power efficiency of RL training through understanding the architectural implications of CPU-GPU systems remains an open problem. In this work we investigate and improve the performance and power efficiency of distributed RL training on CPU-GPU systems by approaching the problem not solely from the GPU microarchitecture perspective but following a holistic system-level analysis approach. We quantify the overall hardware utilization on a state-of-the-art distributed RL training framework and empirically identify the bottlenecks caused by GPU microarchitectural, algorithmic, and system-level design choices. We show that the GPU microarchitecture itself is well-balanced for state-of-the-art RL frameworks, but further investigation reveals that the number of actors running the environment interactions and the amount of hardware resources available to them are the primary performance and power efficiency limiters. To this end, we introduce a new system design metric, CPU/GPU ratio, and show how to find the optimal balance between CPU and GPU resources when designing scalable and efficient CPU-GPU systems for RL training.
How to Stop Epidemics: Controlling Graph Dynamics with Reinforcement Learning and Graph Neural Networks
Oct 26, 2020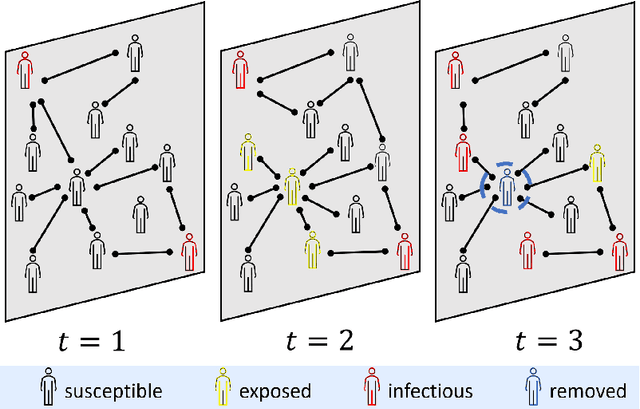
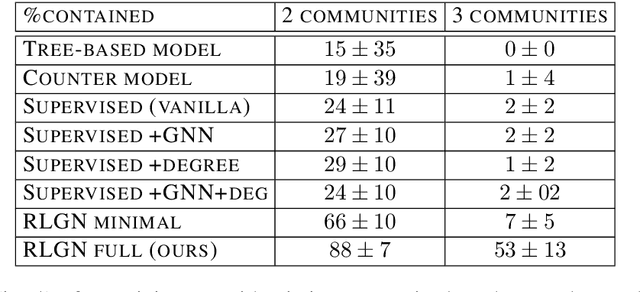
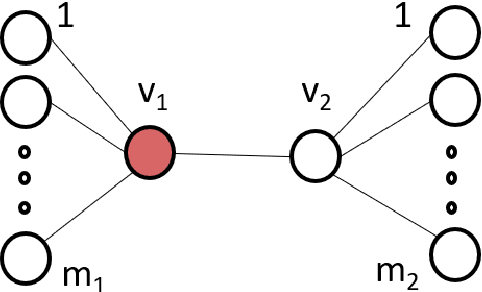
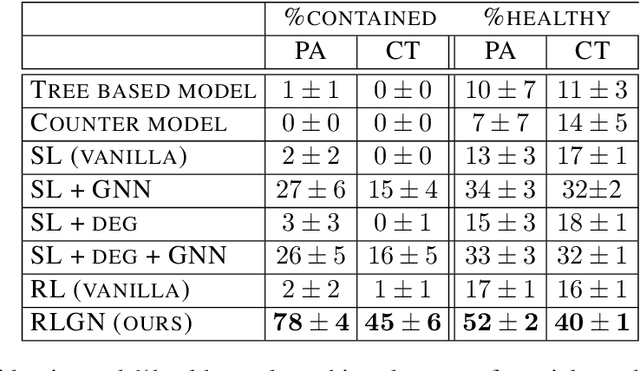
We consider the problem of monitoring and controlling a partially-observed dynamic process that spreads over a graph. This problem naturally arises in contexts such as scheduling virus tests or quarantining individuals to curb a spreading epidemic; detecting fake news spreading on online networks by manually inspecting posted articles; and targeted marketing where the objective is to encourage the spread of a product. Curbing the spread and constraining the fraction of infected population becomes challenging when only a fraction of the population can be tested or quarantined. To address this challenge, we formulate this setup as a sequential decision problem over a graph. In face of an exponential state space, combinatorial action space and partial observability, we design RLGN, a novel tractable Reinforcement Learning (RL) scheme to prioritize which nodes should be tested, using Graph Neural Networks (GNNs) to rank the graph nodes. We evaluate this approach in three types of social-networks: community-structured, preferential attachment, and based on statistics from real cellular tracking. RLGN consistently outperforms all baselines in our experiments. It suggests that prioritizing tests using RL on temporal graphs can increase the number of healthy people by $25\%$ and contain the epidemic $30\%$ more often than supervised approaches and $2.5\times$ more often than non-learned baselines using the same resources.
Drift Detection in Episodic Data: Detect When Your Agent Starts Faltering
Oct 22, 2020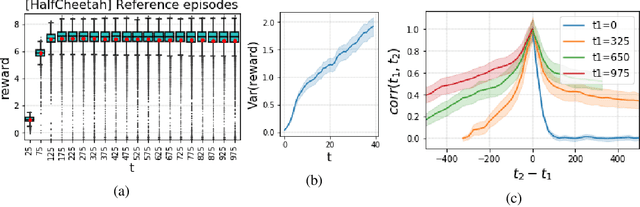

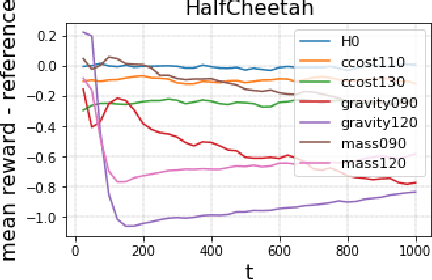
Detection of deterioration of agent performance in dynamic environments is challenging due to the non-i.i.d nature of the observed performance. We consider an episodic framework, where the objective is to detect when an agent begins to falter. We devise a hypothesis testing procedure for non-i.i.d rewards, which is optimal under certain conditions. To apply the procedure sequentially in an online manner, we also suggest a novel Bootstrap mechanism for False Alarm Rate control (BFAR). We demonstrate our procedure in problems where the rewards are not independent, nor identically-distributed, nor normally-distributed. The statistical power of the new testing procedure is shown to outperform alternative tests - often by orders of magnitude - for a variety of environment modifications (which cause deterioration in agent performance). Our detection method is entirely external to the agent, and in particular does not require model-based learning. Furthermore, it can be applied to detect changes or drifts in any episodic signal.
Lenient Regret for Multi-Armed Bandits
Sep 13, 2020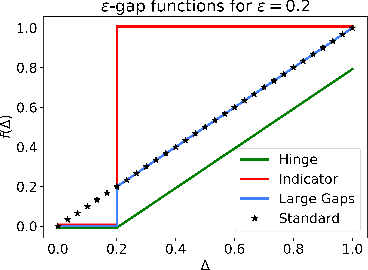
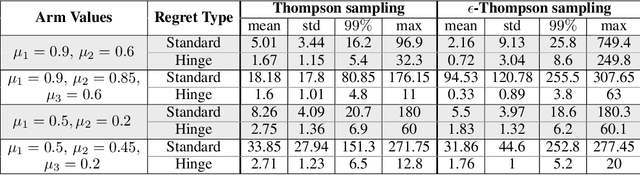
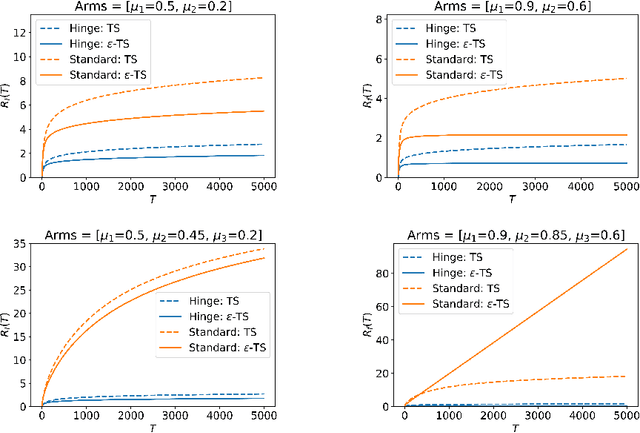
We consider the Multi-Armed Bandit (MAB) problem, where an agent sequentially chooses actions and observes rewards for the actions it took. While the majority of algorithms try to minimize the regret, i.e., the cumulative difference between the reward of the best action and the agent's action, this criterion might lead to undesirable results. For example, in large problems, or when the interaction with the environment is brief, finding an optimal arm is infeasible, and regret-minimizing algorithms tend to over-explore. To overcome this issue, algorithms for such settings should instead focus on playing near-optimal arms. To this end, we suggest a new, more lenient, regret criterion that ignores suboptimality gaps smaller than some $\epsilon$. We then present a variant of the Thompson Sampling (TS) algorithm, called $\epsilon$-TS, and prove its asymptotic optimality in terms of the lenient regret. Importantly, we show that when the mean of the optimal arm is high enough, the lenient regret of $\epsilon$-TS is bounded by a constant. Finally, we show that $\epsilon$-TS can be applied to improve the performance when the agent knows a lower bound of the suboptimality gaps.