 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometry of Robust Value Functions
Jan 30, 2022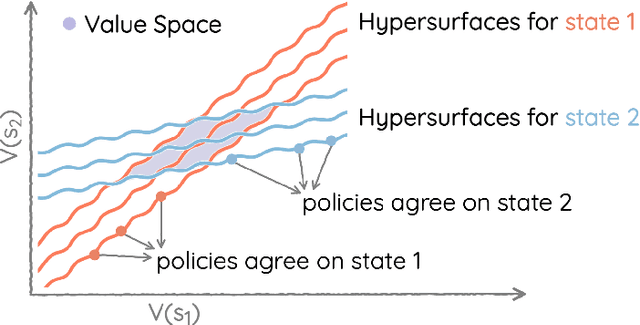
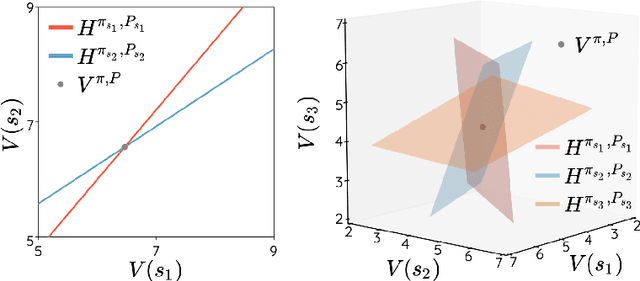
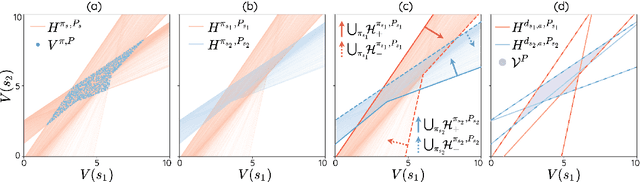
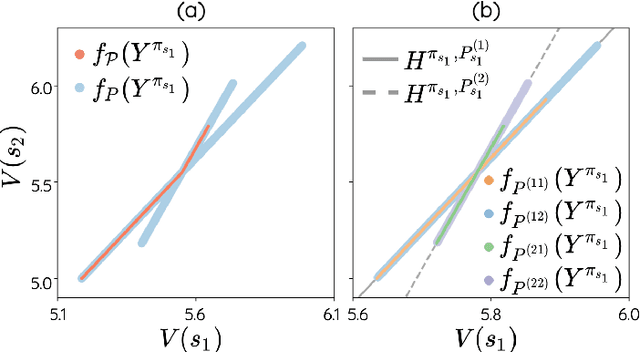
The space of value functions is a fundamental concept in reinforcement learning. Characterizing its geometric properties may provide insights for optimization and representation. Existing works mainly focus on the value space for Markov Decision Processes (MDPs). In this paper, we study the geometry of the robust value space for the more general Robust MDPs (RMDPs) setting, where transition uncertainties are considered. Specifically, since we find it hard to directly adapt prior approaches to RMDPs, we start with revisiting the non-robust case, and introduce a new perspective that enables us to characterize both the non-robust and robust value space in a similar fashion. The key of this perspective is to decompose the value space, in a state-wise manner, into unions of hypersurfaces. Through our analysis, we show that the robust value space is determined by a set of conic hypersurfaces, each of which contains the robust values of all policies that agree on one state. Furthermore, we find that taking only extreme points in the uncertainty set is sufficient to determine the robust value space. Finally, we discuss some other aspects about the robust value space, including its non-convexity and policy agreement on multiple states.
Coordinated Attacks against Contextual Bandits: Fundamental Limits and Defense Mechanisms
Jan 30, 2022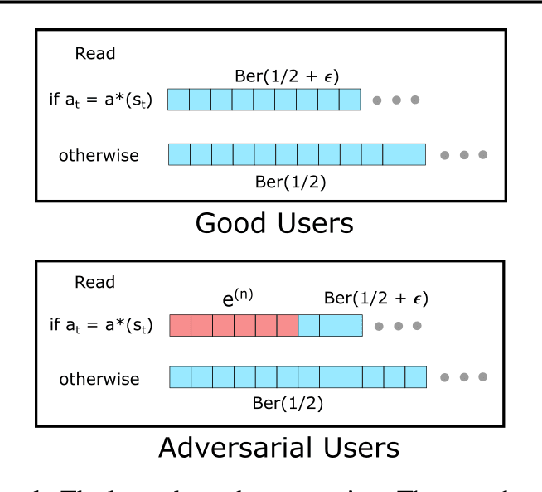
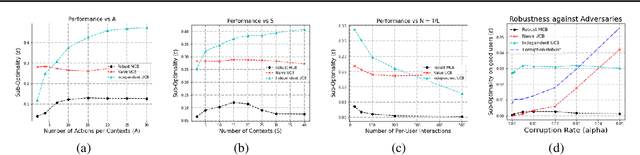
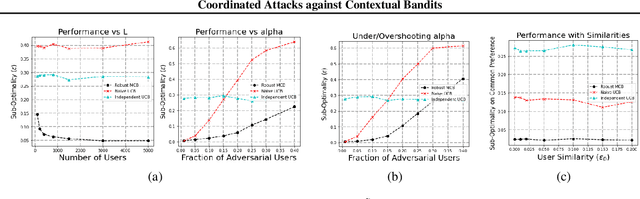
Motivated by online recommendation systems, we propose the problem of finding the optimal policy in multitask contextual bandits when a small fraction $\alpha < 1/2$ of tasks (users) are arbitrary and adversarial. The remaining fraction of good users share the same instance of contextual bandits with $S$ contexts and $A$ actions (items). Naturally, whether a user is good or adversarial is not known in advance. The goal is to robustly learn the policy that maximizes rewards for good users with as few user interactions as possible. Without adversarial users, established results in collaborative filtering show that $O(1/\epsilon^2)$ per-user interactions suffice to learn a good policy, precisely because information can be shared across users. This parallelization gain is fundamentally altered by the presence of adversarial users: unless there are super-polynomial number of users, we show a lower bound of $\tilde{\Omega}(\min(S,A) \cdot \alpha^2 / \epsilon^2)$ {\it per-user} interactions to learn an $\epsilon$-optimal policy for the good users. We then show we can achieve an $\tilde{O}(\min(S,A)\cdot \alpha/\epsilon^2)$ upper-bound, by employing efficient robust mean estimators for both uni-variate and high-dimensional random variables. We also show that this can be improved depending on the distributions of contexts.
Planning and Learning with Adaptive Lookahead
Jan 28, 2022



The classical Policy Iteration (PI) algorithm alternates between greedy one-step policy improvement and policy evaluation. Recent literature shows that multi-step lookahead policy improvement leads to a better convergence rate at the expense of increased complexity per iteration. However, prior to running the algorithm, one cannot tell what is the best fixed lookahead horizon. Moreover, per a given run, using a lookahead of horizon larger than one is often wasteful. In this work, we propose for the first time to dynamically adapt the multi-step lookahead horizon as a function of the state and of the value estimate. We devise two PI variants and analyze the trade-off between iteration count and computational complexity per iteration. The first variant takes the desired contraction factor as the objective and minimizes the per-iteration complexity. The second variant takes as input the computational complexity per iteration and minimizes the overall contraction factor. We then devise a corresponding DQN-based algorithm with an adaptive tree search horizon. We also include a novel enhancement for on-policy learning: per-depth value function estimator. Lastly, we demonstrate the efficacy of our adaptive lookahead method in a maze environment and in Atari.
On Covariate Shift of Latent Confounders in Imitation and Reinforcement Learning
Oct 13, 2021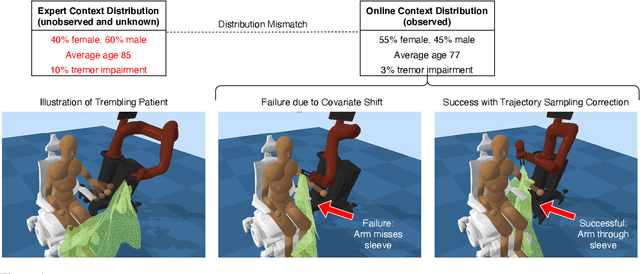
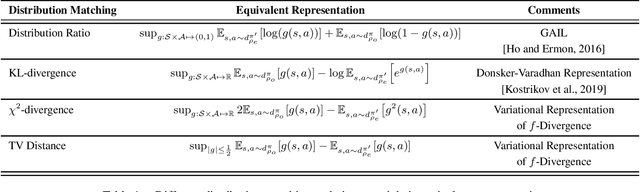

We consider the problem of using expert data with unobserved confounders for imitation and reinforcement learning. We begin by defining the problem of learning from confounded expert data in a contextual MDP setup. We analyze the limitations of learning from such data with and without external reward, and propose an adjustment of standard imitation learning algorithms to fit this setup. We then discuss the problem of distribution shift between the expert data and the online environment when the data is only partially observable. We prove possibility and impossibility results for imitation learning under arbitrary distribution shift of the missing covariates. When additional external reward is provided, we propose a sampling procedure that addresses the unknown shift and prove convergence to an optimal solution. Finally, we validate our claims empirically on challenging assistive healthcare and recommender system simulation tasks.
Twice regularized MDPs and the equivalence between robustness and regularization
Oct 12, 2021
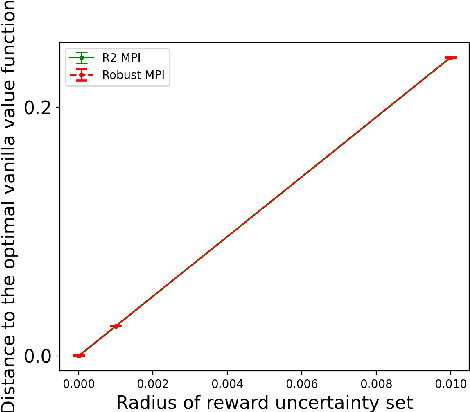
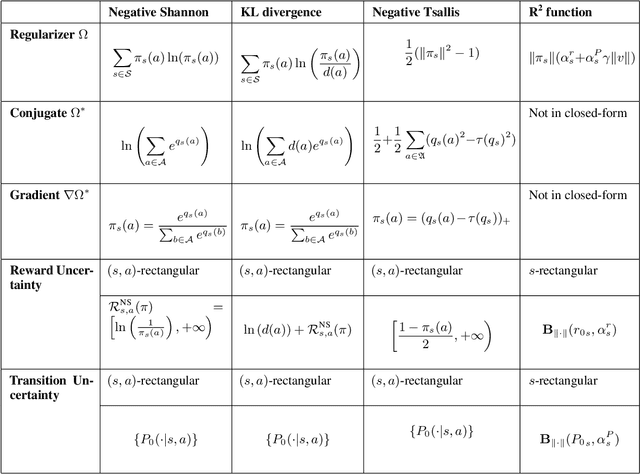
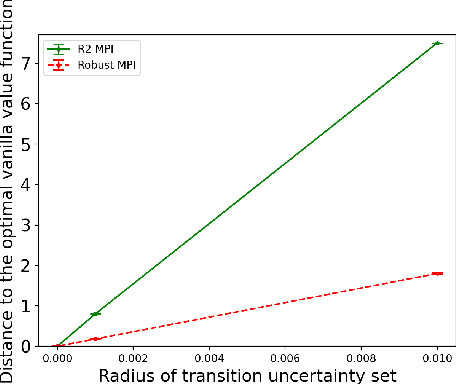
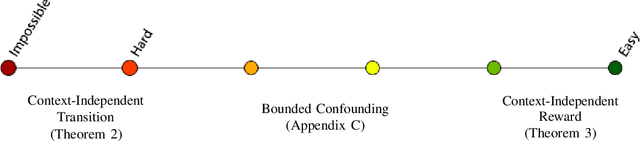
Robust Markov decision processes (MDPs) aim to handle changing or partially known system dynamics. To solve them, one typically resorts to robust optimization methods. However, this significantly increases computational complexity and limits scalability in both learning and planning. On the other hand, regularized MDPs show more stability in policy learning without impairing time complexity. Yet, they generally do not encompass uncertainty in the model dynamics. In this work, we aim to learn robust MDPs using regularization. We first show that regularized MDPs are a particular instance of robust MDPs with uncertain reward. We thus establish that policy iteration on reward-robust MDPs can have the same time complexity as on regularized MDPs. We further extend this relationship to MDPs with uncertain transitions: this leads to a regularization term with an additional dependence on the value function. We finally generalize regularized MDPs to twice regularized MDPs (R${}^2$ MDPs), i.e., MDPs with $\textit{both}$ value and policy regularization. The corresponding Bellman operators enable developing policy iteration schemes with convergence and robustness guarantees. It also reduces planning and learning in robust MDPs to regularized MDPs.
Dare not to Ask: Problem-Dependent Guarantees for Budgeted Bandits
Oct 12, 2021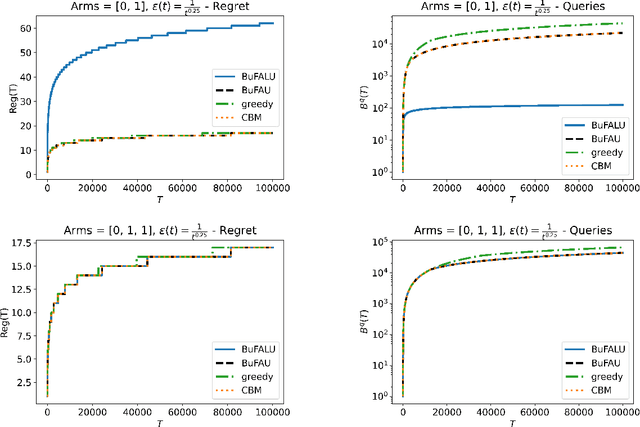
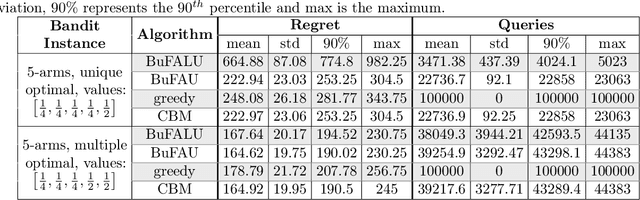
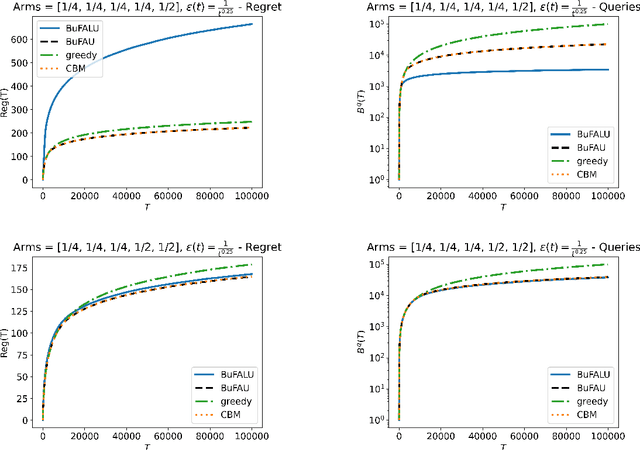
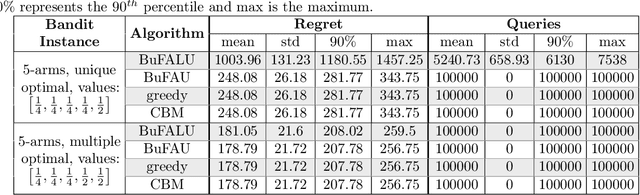
We consider a stochastic multi-armed bandit setting where feedback is limited by a (possibly time-dependent) budget, and reward must be actively inquired for it to be observed. Previous works on this setting assumed a strict feedback budget and focused on not violating this constraint while providing problem-independent regret guarantees. In this work, we provide problem-dependent guarantees on both the regret and the asked feedback. In particular, we derive problem-dependent lower bounds on the required feedback and show that there is a fundamental difference between problems with a unique and multiple optimal arms. Furthermore, we present a new algorithm called BuFALU for which we derive problem-dependent regret and cumulative feedback bounds. Notably, we show that BuFALU naturally adapts to the number of optimal arms.
Reinforcement Learning in Reward-Mixing MDPs
Oct 07, 2021Learning a near optimal policy in a partially observable system remains an elusive challenge in contemporary reinforcement learning. In this work, we consider episodic reinforcement learning in a reward-mixing Markov decision process (MDP). There, a reward function is drawn from one of multiple possible reward models at the beginning of every episode, but the identity of the chosen reward model is not revealed to the agent. Hence, the latent state space, for which the dynamics are Markovian, is not given to the agent. We study the problem of learning a near optimal policy for two reward-mixing MDPs. Unlike existing approaches that rely on strong assumptions on the dynamics, we make no assumptions and study the problem in full generality. Indeed, with no further assumptions, even for two switching reward-models, the problem requires several new ideas beyond existing algorithmic and analysis techniques for efficient exploration. We provide the first polynomial-time algorithm that finds an $\epsilon$-optimal policy after exploring $\tilde{O}(poly(H,\epsilon^{-1}) \cdot S^2 A^2)$ episodes, where $H$ is time-horizon and $S, A$ are the number of states and actions respectively. This is the first efficient algorithm that does not require any assumptions in partially observed environments where the observation space is smaller than the latent state space.
Continuous-Time Fitted Value Iteration for Robust Policies
Oct 05, 2021
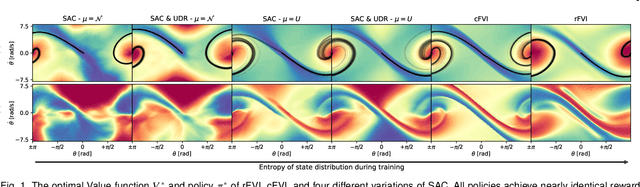


Solving the Hamilton-Jacobi-Bellman equation is important in many domains including control, robotics and economics. Especially for continuous control, solving this differential equation and its extension the Hamilton-Jacobi-Isaacs equation, is important as it yields the optimal policy that achieves the maximum reward on a give task. In the case of the Hamilton-Jacobi-Isaacs equation, which includes an adversary controlling the environment and minimizing the reward, the obtained policy is also robust to perturbations of the dynamics. In this paper we propose continuous fitted value iteration (cFVI) and robust fitted value iteration (rFVI). These algorithms leverage the non-linear control-affine dynamics and separable state and action reward of many continuous control problems to derive the optimal policy and optimal adversary in closed form. This analytic expression simplifies the differential equations and enables us to solve for the optimal value function using value iteration for continuous actions and states as well as the adversarial case. Notably, the resulting algorithms do not require discretization of states or actions. We apply the resulting algorithms to the Furuta pendulum and cartpole. We show that both algorithms obtain the optimal policy. The robustness Sim2Real experiments on the physical systems show that the policies successfully achieve the task in the real-world. When changing the masses of the pendulum, we observe that robust value iteration is more robust compared to deep reinforcement learning algorithm and the non-robust version of the algorithm. Videos of the experiments are shown at https://sites.google.com/view/rfvi
Sim and Real: Better Together
Oct 05, 2021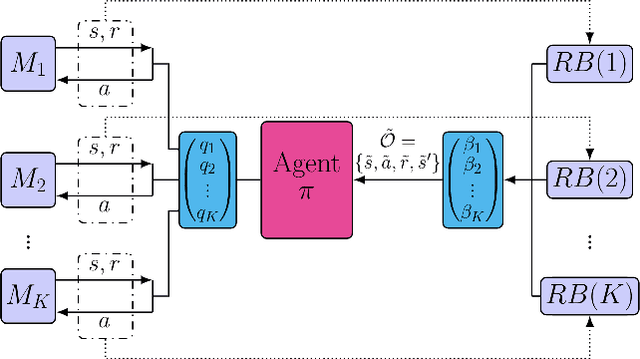
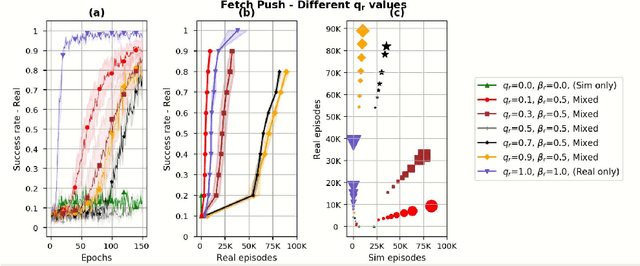
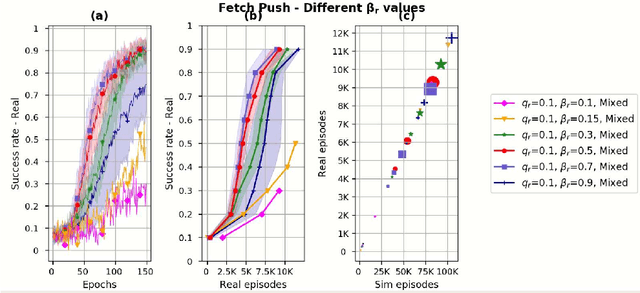
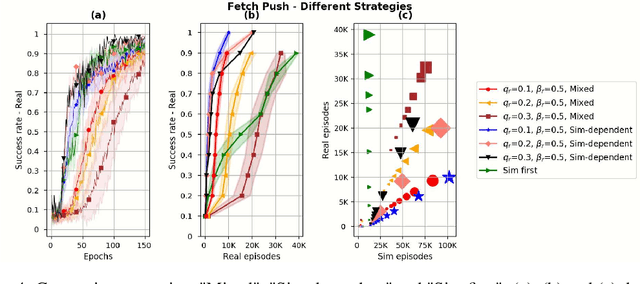
Simulation is used extensively in autonomous systems, particularly in robotic manipulation. By far, the most common approach is to train a controller in simulation, and then use it as an initial starting point for the real system. We demonstrate how to learn simultaneously from both simulation and interaction with the real environment. We propose an algorithm for balancing the large number of samples from the high throughput but less accurate simulation and the low-throughput, high-fidelity and costly samples from the real environment. We achieve that by maintaining a replay buffer for each environment the agent interacts with. We analyze such multi-environment interaction theoretically, and provide convergence properties, through a novel theoretical replay buffer analysis. We demonstrate the efficacy of our method on a sim-to-real environment.
Locality Matters: A Scalable Value Decomposition Approach for Cooperative Multi-Agent Reinforcement Learning
Sep 22, 2021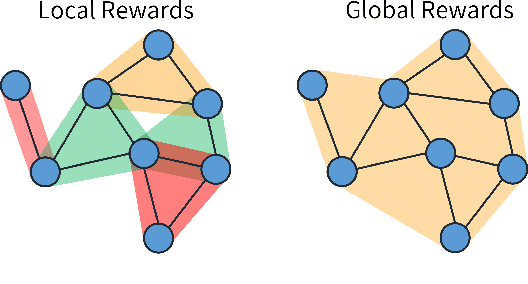

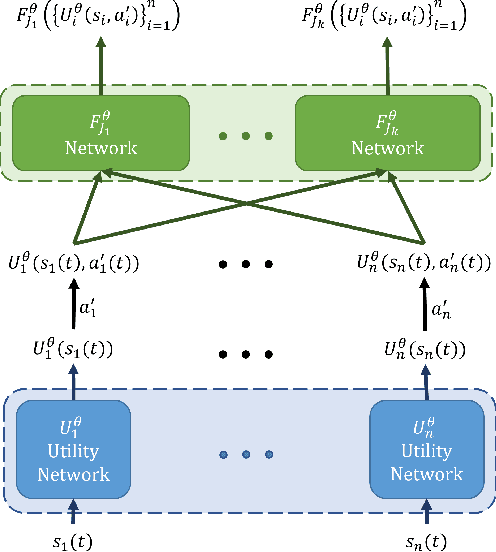

Cooperative multi-agent reinforcement learning (MARL) faces significant scalability issues due to state and action spaces that are exponentially large in the number of agents. As environments grow in size, effective credit assignment becomes increasingly harder and often results in infeasible learning times. Still, in many real-world settings, there exist simplified underlying dynamics that can be leveraged for more scalable solutions. In this work, we exploit such locality structures effectively whilst maintaining global cooperation. We propose a novel, value-based multi-agent algorithm called LOMAQ, which incorporates local rewards in the Centralized Training Decentralized Execution paradigm. Additionally, we provide a direct reward decomposition method for finding these local rewards when only a global signal is provided. We test our method empirically, showing it scales well compared to other methods, significantly improving performance and convergence speed.