 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Reinforcement Learning: A Survey
Sep 14, 2016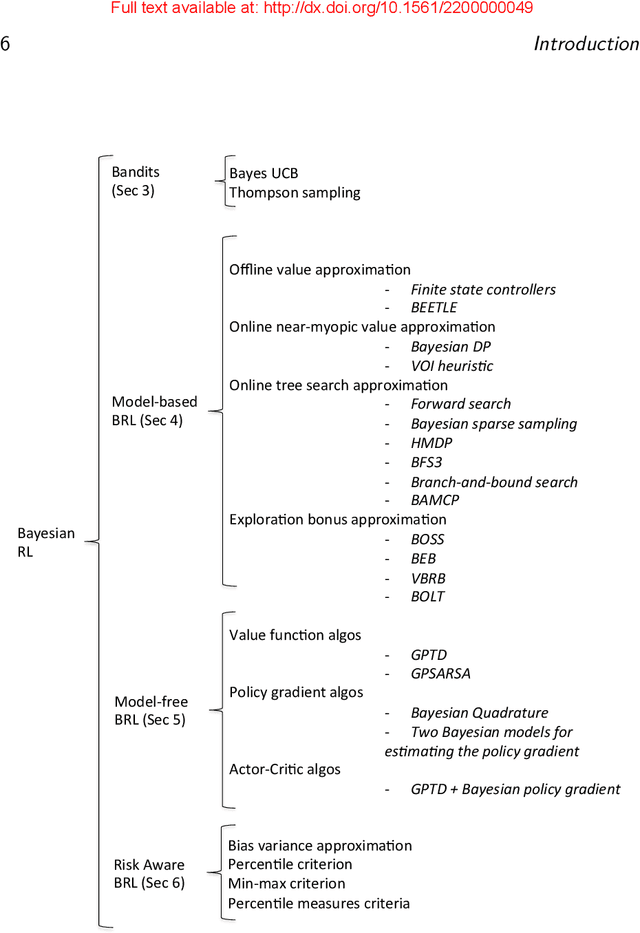
Bayesian methods for machine learning have been widely investigated, yielding principled methods for incorporating prior information into inference algorithms. In this survey, we provide an in-depth review of the role of Bayesian methods for the reinforcement learning (RL) paradigm. The major incentives for incorporating Bayesian reasoning in RL are: 1) it provides an elegant approach to action-selection (exploration/exploitation) as a function of the uncertainty in learning; and 2) it provides a machinery to incorporate prior knowledge into the algorithms. We first discuss models and methods for Bayesian inference in the simple single-step Bandit model. We then review the extensive recent literature on Bayesian methods for model-based RL, where prior information can be expressed on the parameters of the Markov model. We also present Bayesian methods for model-free RL, where priors are expressed over the value function or policy class. The objective of the paper is to provide a comprehensive survey on Bayesian RL algorithms and their theoretical and empirical properties.
Clustering Time Series and the Surprising Robustness of HMMs
Sep 14, 2016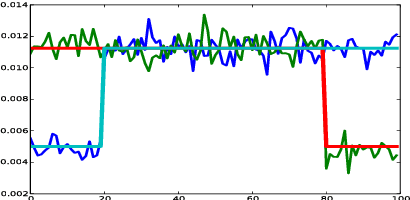
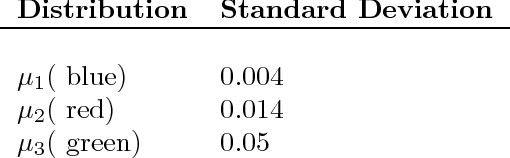
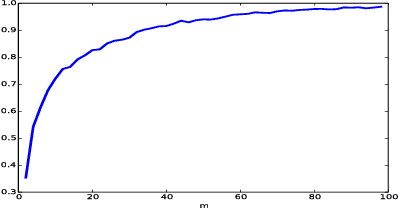
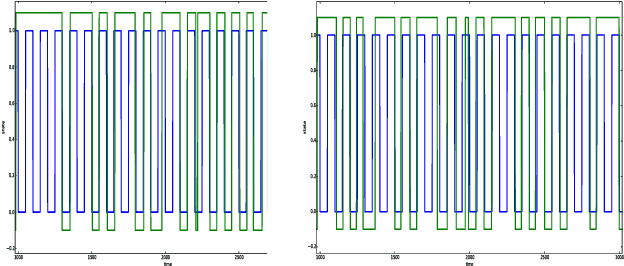
Suppose that we are given a time series where consecutive samples are believed to come from a probabilistic source, that the source changes from time to time and that the total number of sources is fixed. Our objective is to estimate the distributions of the sources. A standard approach to this problem is to model the data as a hidden Markov model (HMM). However, since the data often lacks the Markov or the stationarity properties of an HMM, one can ask whether this approach is still suitable or perhaps another approach is required. In this paper we show that a maximum likelihood HMM estimator can be used to approximate the source distributions in a much larger class of models than HMMs. Specifically, we propose a natural and fairly general non-stationary model of the data, where the only restriction is that the sources do not change too often. Our main result shows that for this model, a maximum-likelihood HMM estimator produces the correct second moment of the data, and the results can be extended to higher moments.
How to Allocate Resources For Features Acquisition?
Jul 10, 2016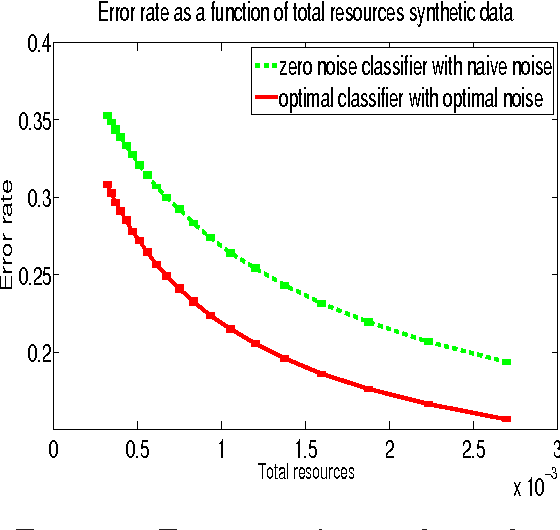
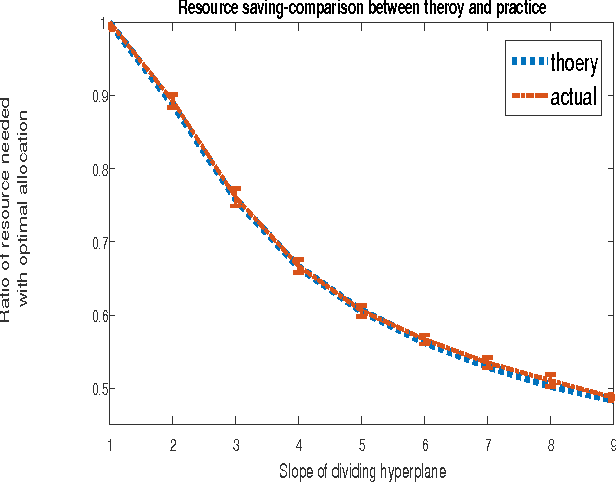
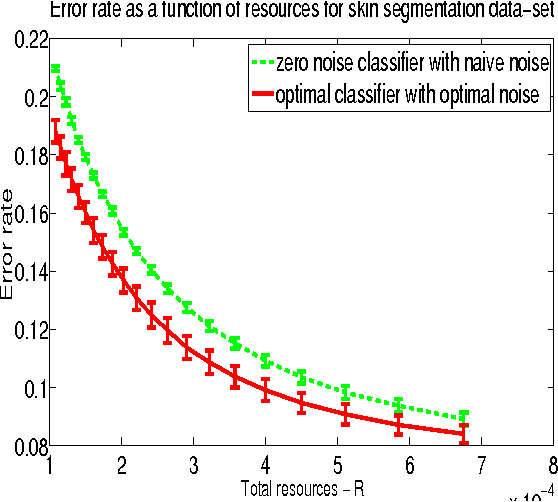
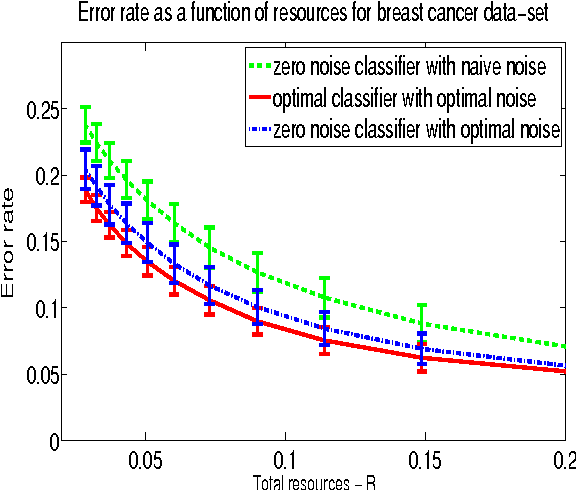
We study classification problems where features are corrupted by noise and where the magnitude of the noise in each feature is influenced by the resources allocated to its acquisition. This is the case, for example, when multiple sensors share a common resource (power, bandwidth, attention, etc.). We develop a method for computing the optimal resource allocation for a variety of scenarios and derive theoretical bounds concerning the benefit that may arise by non-uniform allocation. We further demonstrate the effectiveness of the developed method in simulations.
Visualizing Dynamics: from t-SNE to SEMI-MDPs
Jun 22, 2016
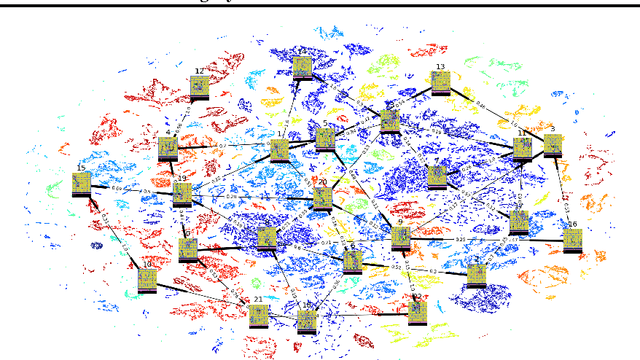
Deep Reinforcement Learning (DRL) is a trending field of research, showing great promise in many challenging problems such as playing Atari, solving Go and controlling robots. While DRL agents perform well in practice we are still missing the tools to analayze their performance and visualize the temporal abstractions that they learn. In this paper, we present a novel method that automatically discovers an internal Semi Markov Decision Process (SMDP) model in the Deep Q Network's (DQN) learned representation. We suggest a novel visualization method that represents the SMDP model by a directed graph and visualize it above a t-SNE map. We show how can we interpret the agent's policy and give evidence for the hierarchical state aggregation that DQNs are learning automatically. Our algorithm is fully automatic, does not require any domain specific knowledge and is evaluated by a novel likelihood based evaluation criteria.
Approachability in unknown games: Online learning meets multi-objective optimization
Jun 17, 2016
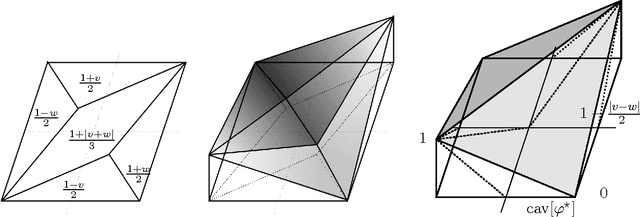
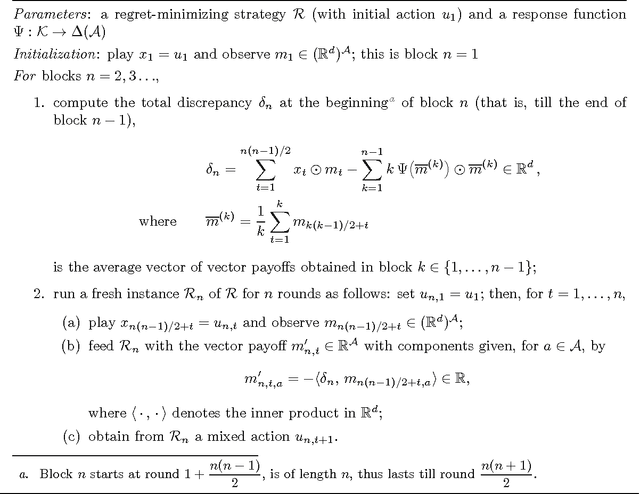
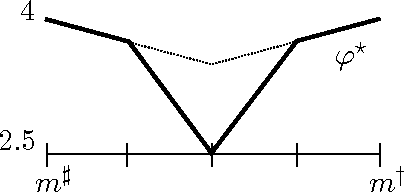
In the standard setting of approachability there are two players and a target set. The players play repeatedly a known vector-valued game where the first player wants to have the average vector-valued payoff converge to the target set which the other player tries to exclude it from this set. We revisit this setting in the spirit of online learning and do not assume that the first player knows the game structure: she receives an arbitrary vector-valued reward vector at every round. She wishes to approach the smallest ("best") possible set given the observed average payoffs in hindsight. This extension of the standard setting has implications even when the original target set is not approachable and when it is not obvious which expansion of it should be approached instead. We show that it is impossible, in general, to approach the best target set in hindsight and propose achievable though ambitious alternative goals. We further propose a concrete strategy to approach these goals. Our method does not require projection onto a target set and amounts to switching between scalar regret minimization algorithms that are performed in episodes. Applications to global cost minimization and to approachability under sample path constraints are considered.
Deep Reinforcement Learning Discovers Internal Models
Jun 16, 2016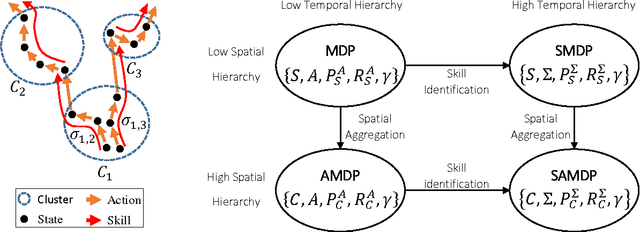

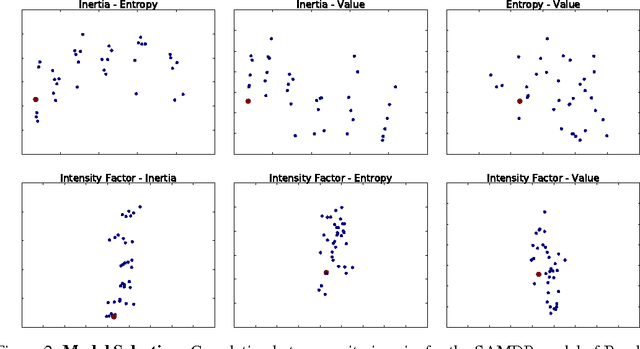
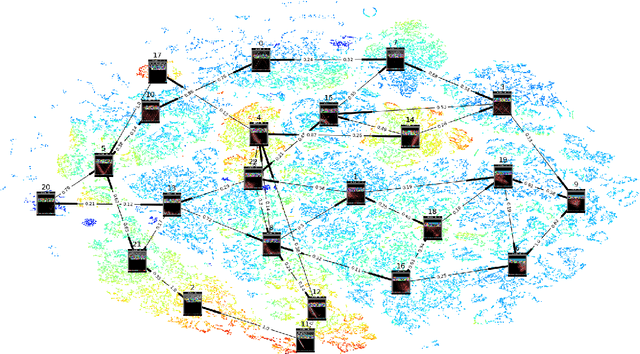
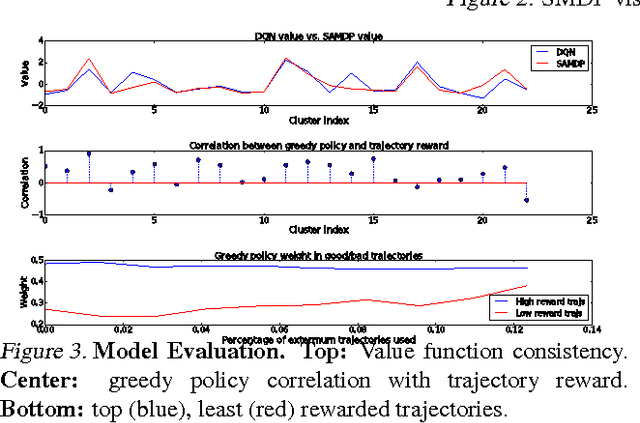
Deep Reinforcement Learning (DRL) is a trending field of research, showing great promise in challenging problems such as playing Atari, solving Go and controlling robots. While DRL agents perform well in practice we are still lacking the tools to analayze their performance. In this work we present the Semi-Aggregated MDP (SAMDP) model. A model best suited to describe policies exhibiting both spatial and temporal hierarchies. We describe its advantages for analyzing trained policies over other modeling approaches, and show that under the right state representation, like that of DQN agents, SAMDP can help to identify skills. We detail the automatic process of creating it from recorded trajectories, up to presenting it on t-SNE maps. We explain how to evaluate its fitness and show surprising results indicating high compatibility with the policy at hand. We conclude by showing how using the SAMDP model, an extra performance gain can be squeezed from the agent.
Iterative Hierarchical Optimization for Misspecified Problems (IHOMP)
Jun 07, 2016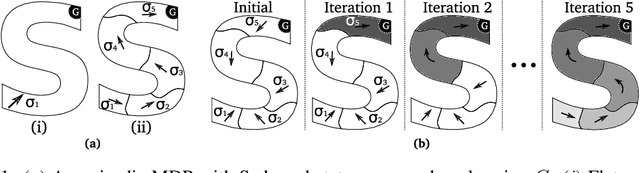
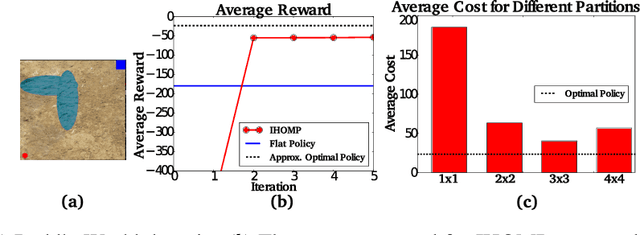
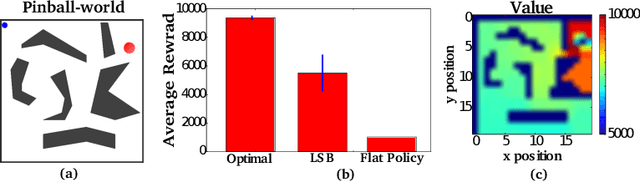
For complex, high-dimensional Markov Decision Processes (MDPs), it may be necessary to represent the policy with function approximation. A problem is misspecified whenever, the representation cannot express any policy with acceptable performance. We introduce IHOMP : an approach for solving misspecified problems. IHOMP iteratively learns a set of context specialized options and combines these options to solve an otherwise misspecified problem. Our main contribution is proving that IHOMP enjoys theoretical convergence guarantees. In addition, we extend IHOMP to exploit Option Interruption (OI) enabling it to decide where the learned options can be reused. Our experiments demonstrate that IHOMP can find near-optimal solutions to otherwise misspecified problems and that OI can further improve the solutions.
Adaptive Skills, Adaptive Partitions (ASAP)
Jun 07, 2016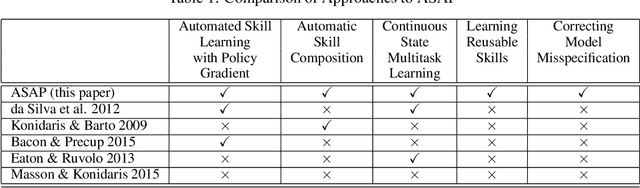
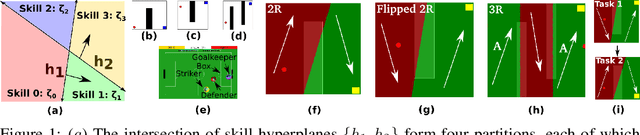
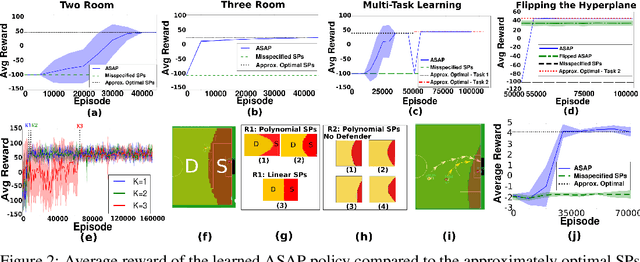
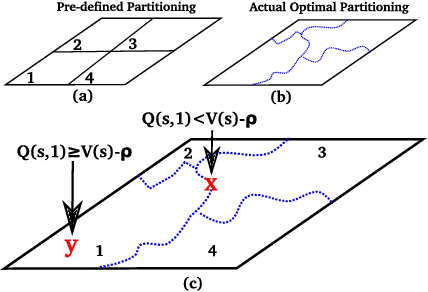
We introduce the Adaptive Skills, Adaptive Partitions (ASAP) framework that (1) learns skills (i.e., temporally extended actions or options) as well as (2) where to apply them. We believe that both (1) and (2) are necessary for a truly general skill learning framework, which is a key building block needed to scale up to lifelong learning agents. The ASAP framework can also solve related new tasks simply by adapting where it applies its existing learned skills. We prove that ASAP converges to a local optimum under natural conditions. Finally, our experimental results, which include a RoboCup domain, demonstrate the ability of ASAP to learn where to reuse skills as well as solve multiple tasks with considerably less experience than solving each task from scratch.
Bending the Curve: Improving the ROC Curve Through Error Redistribution
May 21, 2016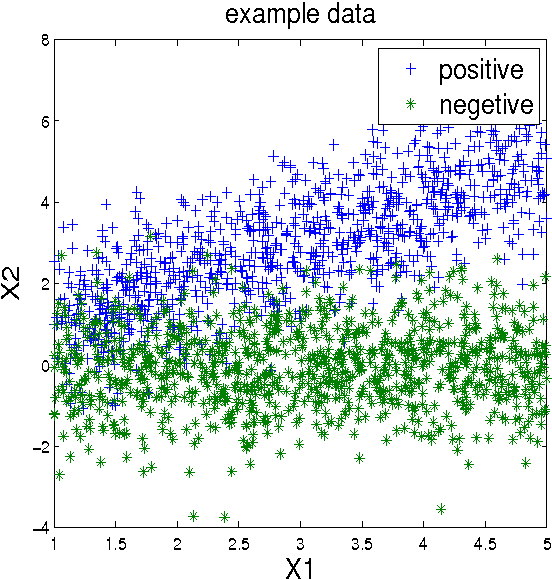
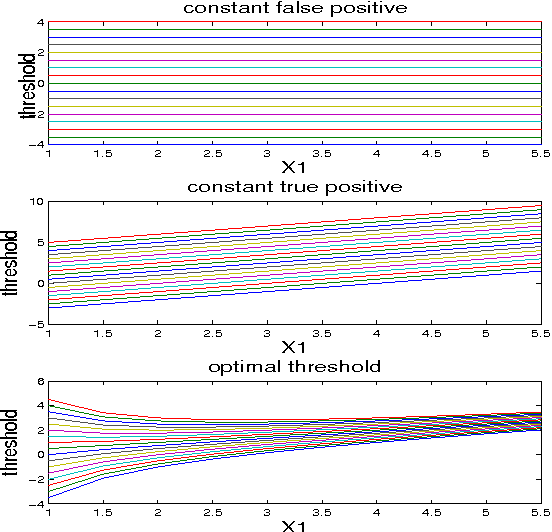
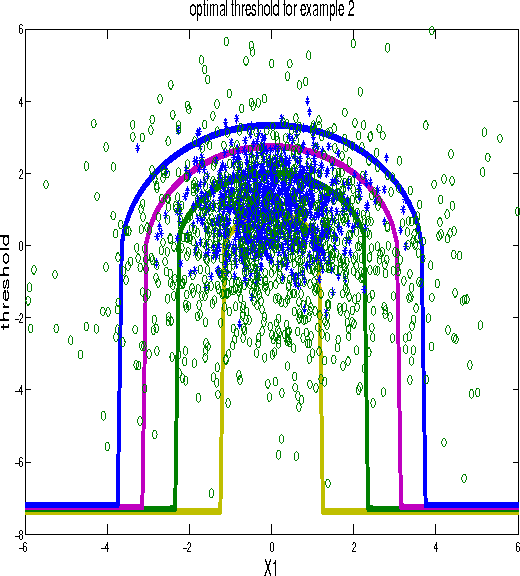
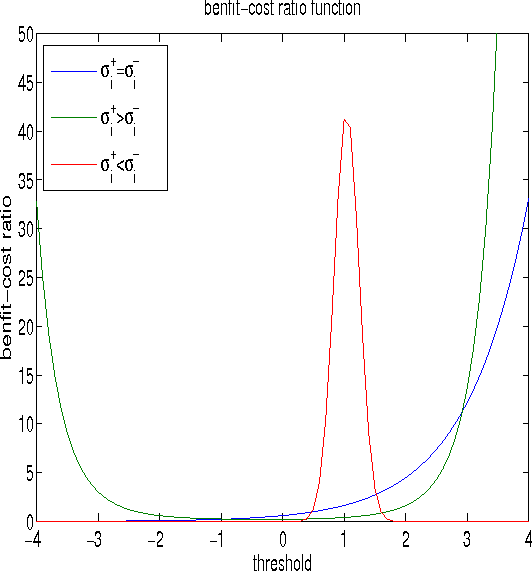
Classification performance is often not uniform over the data. Some areas in the input space are easier to classify than others. Features that hold information about the "difficulty" of the data may be non-discriminative and are therefore disregarded in the classification process. We propose a meta-learning approach where performance may be improved by post-processing. This improvement is done by establishing a dynamic threshold on the base-classifier results. Since the base-classifier is treated as a "black box" the method presented can be used on any state of the art classifier in order to try an improve its performance. We focus our attention on how to better control the true-positive/false-positive trade-off known as the ROC curve. We propose an algorithm for the derivation of optimal thresholds by redistributing the error depending on features that hold information about difficulty. We demonstrate the resulting benefit on both synthetic and real-life data.
A Reinforcement Learning System to Encourage Physical Activity in Diabetes Patients
May 13, 2016
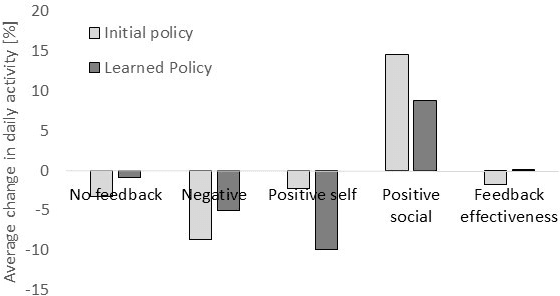

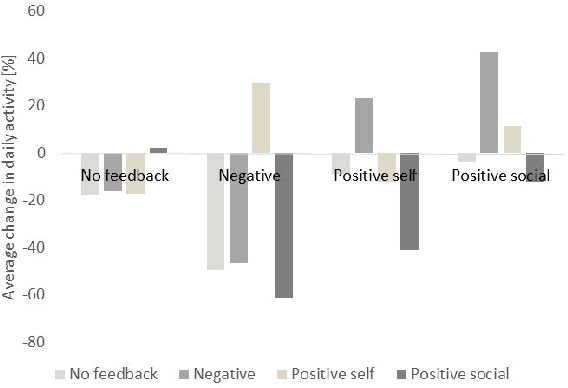
Regular physical activity is known to be beneficial to people suffering from diabetes type 2. Nevertheless, most such people are sedentary. Smartphones create new possibilities for helping people to adhere to their physical activity goals, through continuous monitoring and communication, coupled with personalized feedback. We provided 27 sedentary diabetes type 2 patients with a smartphone-based pedometer and a personal plan for physical activity. Patients were sent SMS messages to encourage physical activity between once a day and once per week. Messages were personalized through a Reinforcement Learning (RL) algorithm which optimized messages to improve each participant's compliance with the activity regimen. The RL algorithm was compared to a static policy for sending messages and to weekly reminders. Our results show that participants who received messages generated by the RL algorithm increased the amount of activity and pace of walking, while the control group patients did not. Patients assigned to the RL algorithm group experienced a superior reduction in blood glucose levels (HbA1c) compared to control policies, and longer participation caused greater reductions in blood glucose levels. The learning algorithm improved gradually in predicting which messages would lead participants to exercise. Our results suggest that a mobile phone application coupled with a learning algorithm can improve adherence to exercise in diabetic patients. As a learning algorithm is automated, and delivers personalized messages, it could be used in large populations of diabetic patients to improve health and glycemic control. Our results can be expanded to other areas where computer-led health coaching of humans may have a positive impact.