 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Robust Kalman Filter
Mar 07, 2017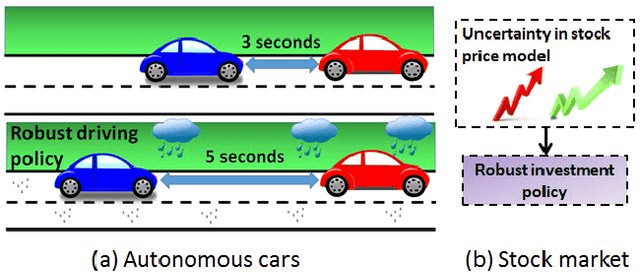
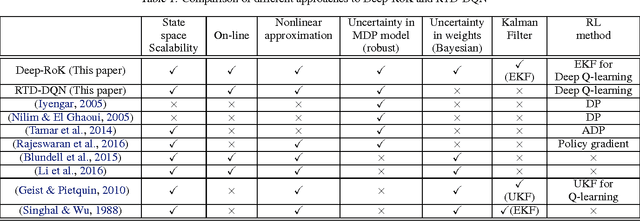
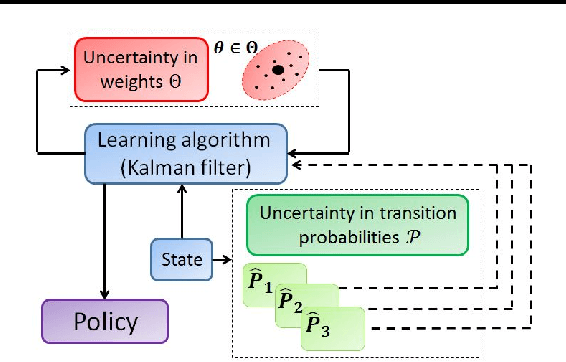
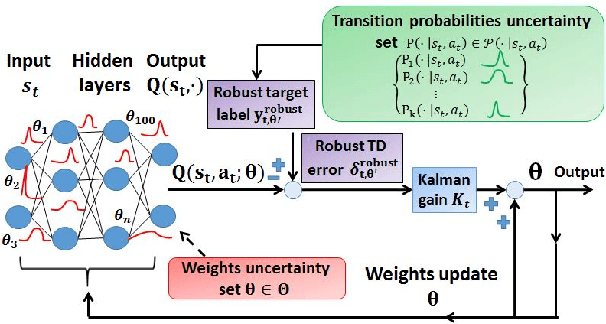
A Robust Markov Decision Process (RMDP) is a sequential decision making model that accounts for uncertainty in the parameters of dynamic systems. This uncertainty introduces difficulties in learning an optimal policy, especially for environments with large state spaces. We propose two algorithms, RTD-DQN and Deep-RoK, for solving large-scale RMDPs using nonlinear approximation schemes such as deep neural networks. The RTD-DQN algorithm incorporates the robust Bellman temporal difference error into a robust loss function, yielding robust policies for the agent. The Deep-RoK algorithm is a robust Bayesian method, based on the Extended Kalman Filter (EKF), that accounts for both the uncertainty in the weights of the approximated value function and the uncertainty in the transition probabilities, improving the robustness of the agent. We provide theoretical results for our approach and test the proposed algorithms on a continuous state domain.
Online Learning with Many Experts
Feb 25, 2017We study the problem of prediction with expert advice when the number of experts in question may be extremely large or even infinite. We devise an algorithm that obtains a tight regret bound of $\widetilde{O}(\epsilon T + N + \sqrt{NT})$, where $N$ is the empirical $\epsilon$-covering number of the sequence of loss functions generated by the environment. In addition, we present a hedging procedure that allows us to find the optimal $\epsilon$ in hindsight. Finally, we discuss a few interesting applications of our algorithm. We show how our algorithm is applicable in the approximately low rank experts model of Hazan et al. (2016), and discuss the case of experts with bounded variation, in which there is a surprisingly large gap between the regret bounds obtained in the statistical and online settings.
Consistent On-Line Off-Policy Evaluation
Feb 23, 2017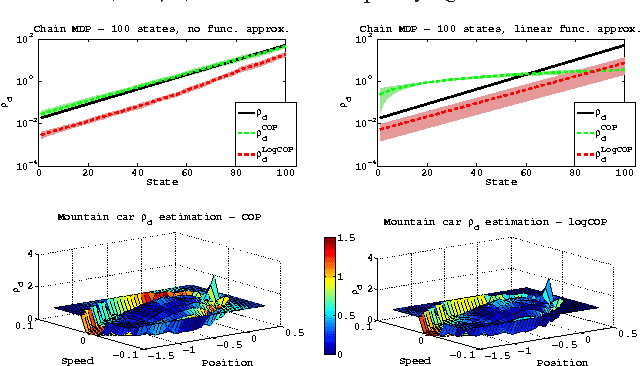
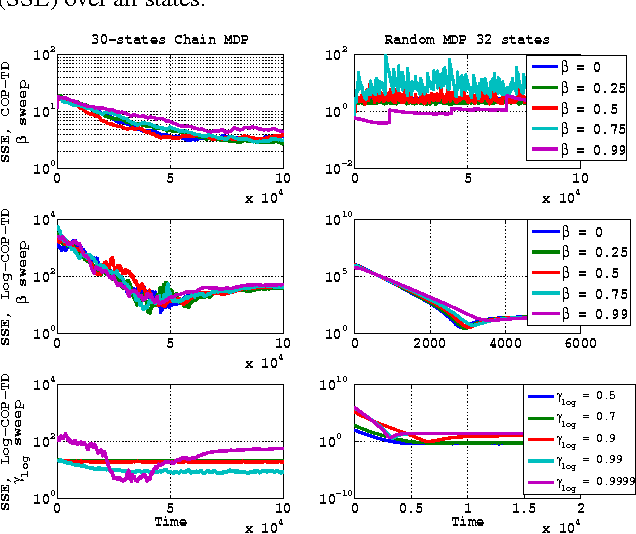
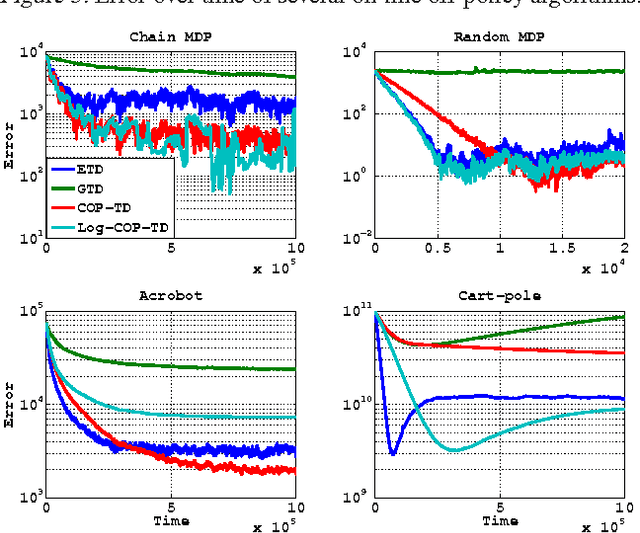
The problem of on-line off-policy evaluation (OPE) has been actively studied in the last decade due to its importance both as a stand-alone problem and as a module in a policy improvement scheme. However, most Temporal Difference (TD) based solutions ignore the discrepancy between the stationary distribution of the behavior and target policies and its effect on the convergence limit when function approximation is applied. In this paper we propose the Consistent Off-Policy Temporal Difference (COP-TD($\lambda$, $\beta$)) algorithm that addresses this issue and reduces this bias at some computational expense. We show that COP-TD($\lambda$, $\beta$) can be designed to converge to the same value that would have been obtained by using on-policy TD($\lambda$) with the target policy. Subsequently, the proposed scheme leads to a related and promising heuristic we call log-COP-TD($\lambda$, $\beta$). Both algorithms have favorable empirical results to the current state of the art on-line OPE algorithms. Finally, our formulation sheds some new light on the recently proposed Emphatic TD learning.
Outlier Robust Online Learning
Jan 01, 2017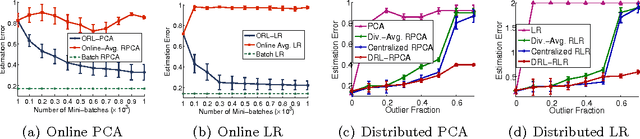
We consider the problem of learning from noisy data in practical settings where the size of data is too large to store on a single machine. More challenging, the data coming from the wild may contain malicious outliers. To address the scalability and robustness issues, we present an online robust learning (ORL) approach. ORL is simple to implement and has provable robustness guarantee -- in stark contrast to existing online learning approaches that are generally fragile to outliers. We specialize the ORL approach for two concrete cases: online robust principal component analysis and online linear regression. We demonstrate the efficiency and robustness advantages of ORL through comprehensive simulations and predicting image tags on a large-scale data set. We also discuss extension of the ORL to distributed learning and provide experimental evaluations.
Adaptive Lambda Least-Squares Temporal Difference Learning
Dec 30, 2016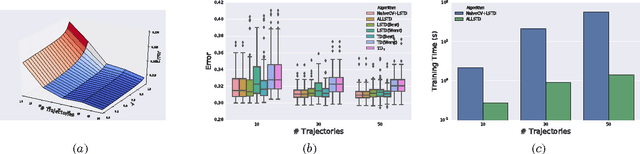
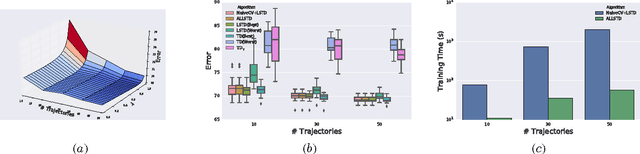
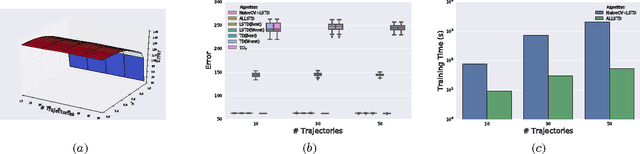
Temporal Difference learning or TD($\lambda$) is a fundamental algorithm in the field of reinforcement learning. However, setting TD's $\lambda$ parameter, which controls the timescale of TD updates, is generally left up to the practitioner. We formalize the $\lambda$ selection problem as a bias-variance trade-off where the solution is the value of $\lambda$ that leads to the smallest Mean Squared Value Error (MSVE). To solve this trade-off we suggest applying Leave-One-Trajectory-Out Cross-Validation (LOTO-CV) to search the space of $\lambda$ values. Unfortunately, this approach is too computationally expensive for most practical applications. For Least Squares TD (LSTD) we show that LOTO-CV can be implemented efficiently to automatically tune $\lambda$ and apply function optimization methods to efficiently search the space of $\lambda$ values. The resulting algorithm, ALLSTD, is parameter free and our experiments demonstrate that ALLSTD is significantly computationally faster than the na\"{i}ve LOTO-CV implementation while achieving similar performance.
Supervised Learning for Optimal Power Flow as a Real-Time Proxy
Dec 20, 2016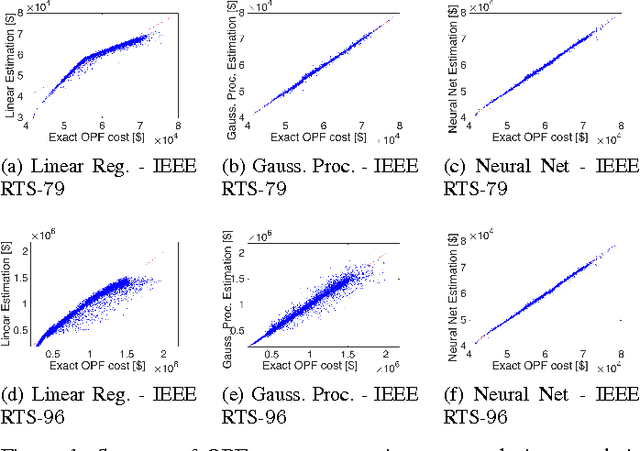
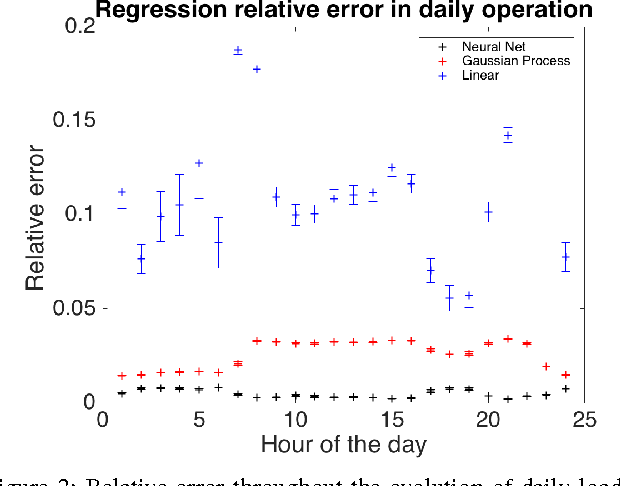
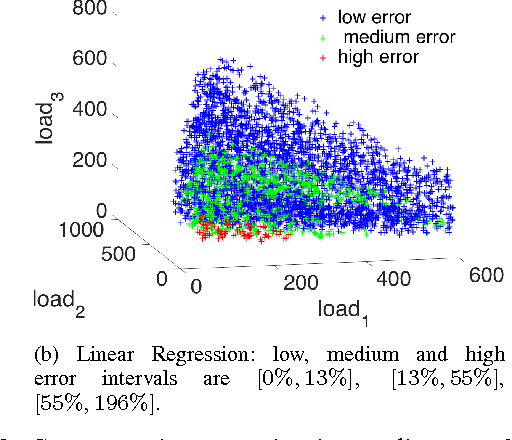
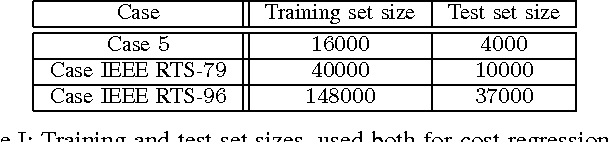
In this work we design and compare different supervised learning algorithms to compute the cost of Alternating Current Optimal Power Flow (ACOPF). The motivation for quick calculation of OPF cost outcomes stems from the growing need of algorithmic-based long-term and medium-term planning methodologies in power networks. Integrated in a multiple time-horizon coordination framework, we refer to this approximation module as a proxy for predicting short-term decision outcomes without the need of actual simulation and optimization of them. Our method enables fast approximate calculation of OPF cost with less than 1% error on average, achieved in run-times that are several orders of magnitude lower than of exact computation. Several test-cases such as IEEE-RTS96 are used to demonstrate the efficiency of our approach.
Model-based Adversarial Imitation Learning
Dec 07, 2016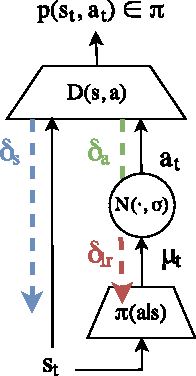
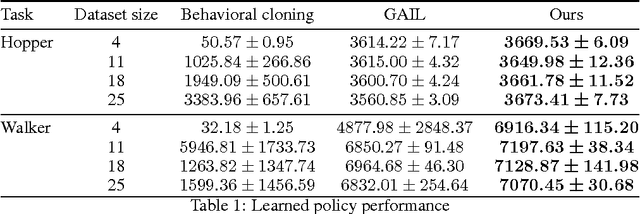
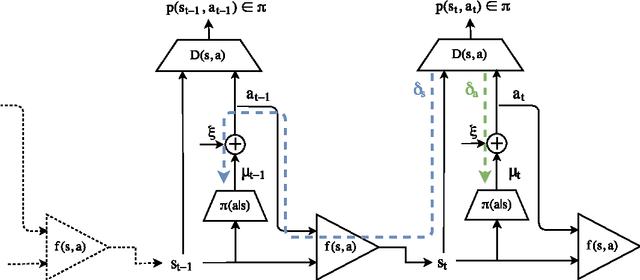

Generative adversarial learning is a popular new approach to training generative models which has been proven successful for other related problems as well. The general idea is to maintain an oracle $D$ that discriminates between the expert's data distribution and that of the generative model $G$. The generative model is trained to capture the expert's distribution by maximizing the probability of $D$ misclassifying the data it generates. Overall, the system is \emph{differentiable} end-to-end and is trained using basic backpropagation. This type of learning was successfully applied to the problem of policy imitation in a model-free setup. However, a model-free approach does not allow the system to be differentiable, which requires the use of high-variance gradient estimations. In this paper we introduce the Model based Adversarial Imitation Learning (MAIL) algorithm. A model-based approach for the problem of adversarial imitation learning. We show how to use a forward model to make the system fully differentiable, which enables us to train policies using the (stochastic) gradient of $D$. Moreover, our approach requires relatively few environment interactions, and fewer hyper-parameters to tune. We test our method on the MuJoCo physics simulator and report initial results that surpass the current state-of-the-art.
A Deep Hierarchical Approach to Lifelong Learning in Minecraft
Nov 30, 2016
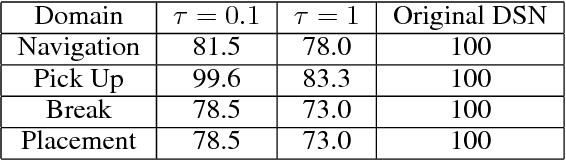
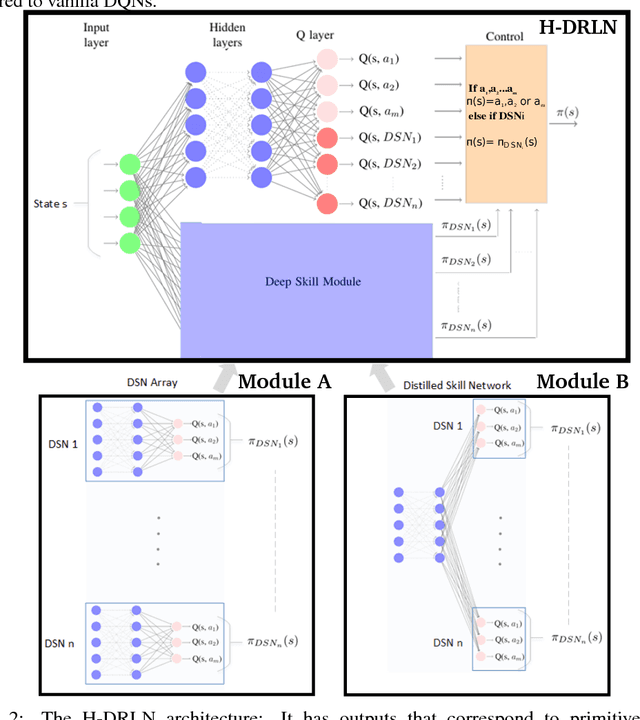
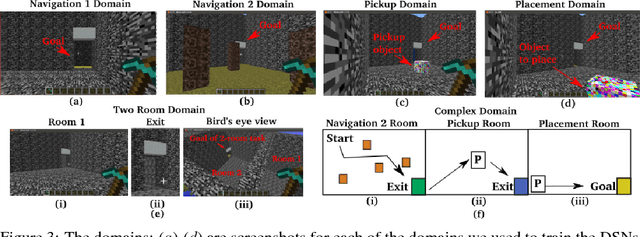
We propose a lifelong learning system that has the ability to reuse and transfer knowledge from one task to another while efficiently retaining the previously learned knowledge-base. Knowledge is transferred by learning reusable skills to solve tasks in Minecraft, a popular video game which is an unsolved and high-dimensional lifelong learning problem. These reusable skills, which we refer to as Deep Skill Networks, are then incorporated into our novel Hierarchical Deep Reinforcement Learning Network (H-DRLN) architecture using two techniques: (1) a deep skill array and (2) skill distillation, our novel variation of policy distillation (Rusu et. al. 2015) for learning skills. Skill distillation enables the HDRLN to efficiently retain knowledge and therefore scale in lifelong learning, by accumulating knowledge and encapsulating multiple reusable skills into a single distilled network. The H-DRLN exhibits superior performance and lower learning sample complexity compared to the regular Deep Q Network (Mnih et. al. 2015) in sub-domains of Minecraft.
Is a picture worth a thousand words? A Deep Multi-Modal Fusion Architecture for Product Classification in e-commerce
Nov 29, 2016
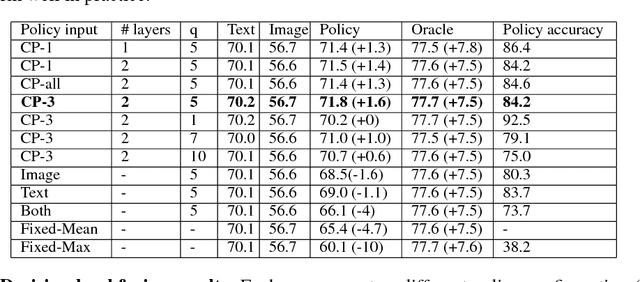
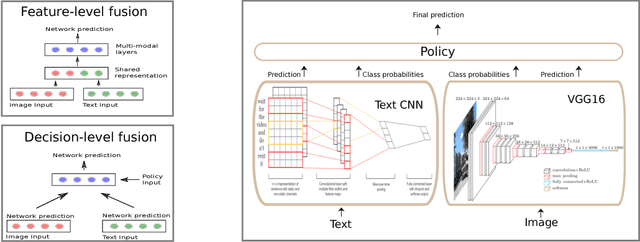
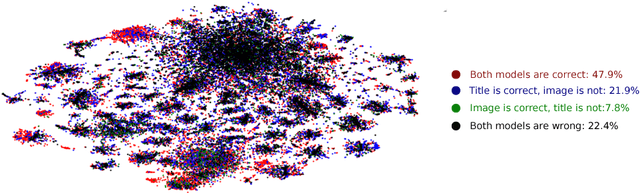
Classifying products into categories precisely and efficiently is a major challenge in modern e-commerce. The high traffic of new products uploaded daily and the dynamic nature of the categories raise the need for machine learning models that can reduce the cost and time of human editors. In this paper, we propose a decision level fusion approach for multi-modal product classification using text and image inputs. We train input specific state-of-the-art deep neural networks for each input source, show the potential of forging them together into a multi-modal architecture and train a novel policy network that learns to choose between them. Finally, we demonstrate that our multi-modal network improves the top-1 accuracy % over both networks on a real-world large-scale product classification dataset that we collected fromWalmart.com. While we focus on image-text fusion that characterizes e-commerce domains, our algorithms can be easily applied to other modalities such as audio, video, physical sensors, etc.
Situational Awareness by Risk-Conscious Skills
Oct 10, 2016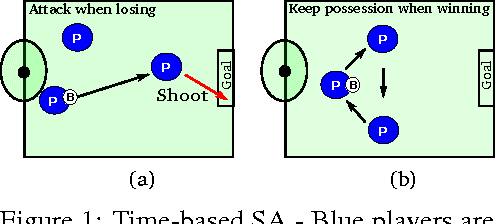
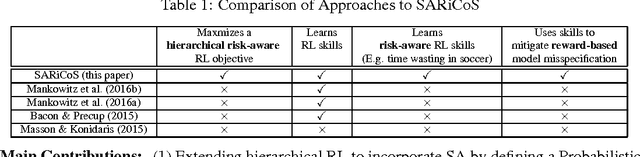
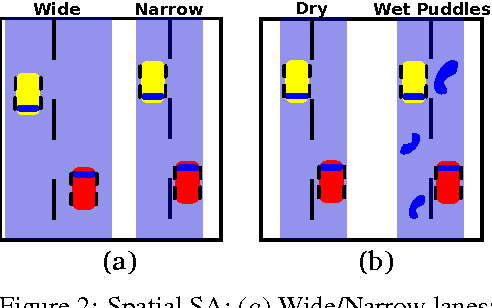
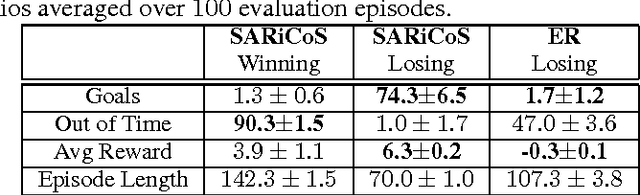
Hierarchical Reinforcement Learning has been previously shown to speed up the convergence rate of RL planning algorithms as well as mitigate feature-based model misspecification (Mankowitz et. al. 2016a,b, Bacon 2015). To do so, it utilizes hierarchical abstractions, also known as skills -- a type of temporally extended action (Sutton et. al. 1999) to plan at a higher level, abstracting away from the lower-level details. We incorporate risk sensitivity, also referred to as Situational Awareness (SA), into hierarchical RL for the first time by defining and learning risk aware skills in a Probabilistic Goal Semi-Markov Decision Process (PG-SMDP). This is achieved using our novel Situational Awareness by Risk-Conscious Skills (SARiCoS) algorithm which comes with a theoretical convergence guarantee. We show in a RoboCup soccer domain that the learned risk aware skills exhibit complex human behaviors such as `time-wasting' in a soccer game. In addition, the learned risk aware skills are able to mitigate reward-based model misspecification.