 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network
Feb 04, 2019
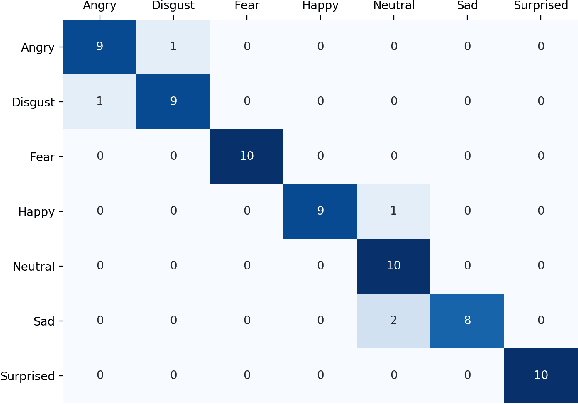


Facial expression recognition has been an active research area over the past few decades, and it is still challenging due to the high intra-class variation. Traditional approaches for this problem rely on hand-crafted features such as SIFT, HOG and LBP, followed by a classifier trained on a database of images or videos. Most of these works perform reasonably well on datasets of images captured in a controlled condition, but fail to perform as good on more challenging datasets with more image variation and partial faces. In recent years, several works proposed an end-to-end framework for facial expression recognition, using deep learning models. Despite the better performance of these works, there still seems to be a great room for improvement. In this work, we propose a deep learning approach based on attentional convolutional network, which is able to focus on important parts of the face, and achieves significant improvement over previous models on multiple datasets, including FER-2013, CK+, FERG, and JAFFE. We also use a visualization technique which is able to find important face regions for detecting different emotions, based on the classifier's output. Through experimental results, we show that different emotions seems to be sensitive to different parts of the face.
Efficient Super Resolution For Large-Scale Images Using Attentional GAN
Jan 13, 2019

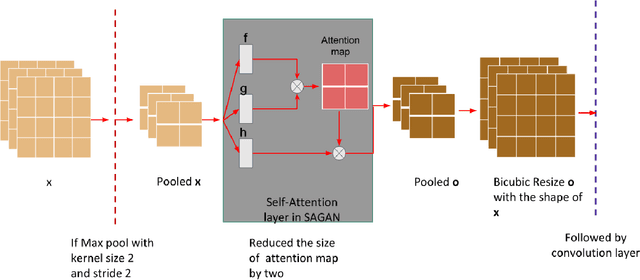
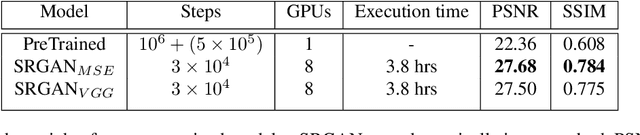
Single Image Super Resolution (SISR) is a well-researched problem with broad commercial relevance. However, most of the SISR literature focuses on small-size images under 500px, whereas business needs can mandate the generation of very high resolution images. At Expedia Group, we were tasked with generating images of at least 2000px for display on the website, four times greater than the sizes typically reported in the literature. This requirement poses a challenge that state-of-the-art models, validated on small images, have not been proven to handle. In this paper, we investigate solutions to the problem of generating high-quality images for large-scale super resolution in a commercial setting. We find that training a generative adversarial network (GAN) with attention from scratch using a large-scale lodging image data set generates images with high PSNR and SSIM scores. We describe a novel attentional SISR model for large-scale images, A-SRGAN, that uses a Flexible Self Attention layer to enable processing of large-scale images. We also describe a distributed algorithm which speeds up training by around a factor of five.
Iris-GAN: Learning to Generate Realistic Iris Images Using Convolutional GAN
Dec 25, 2018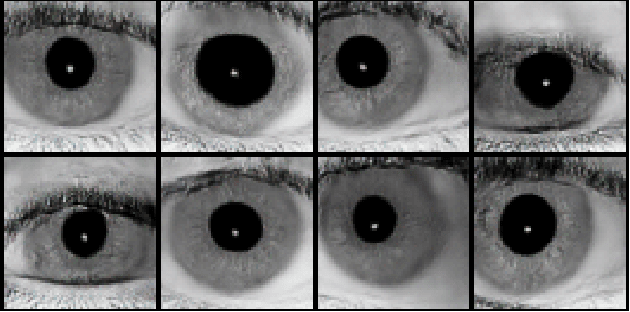
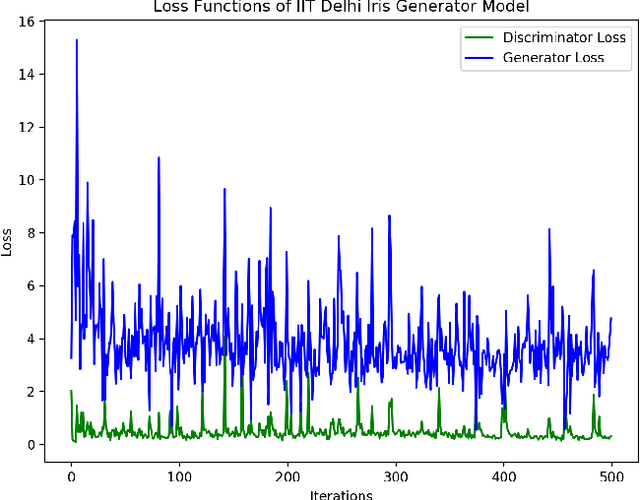
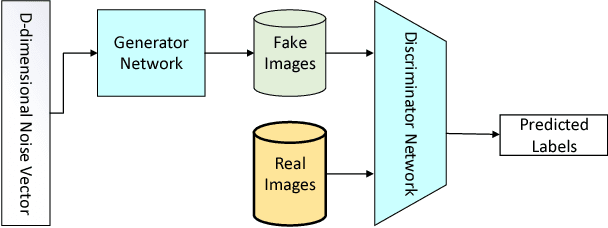
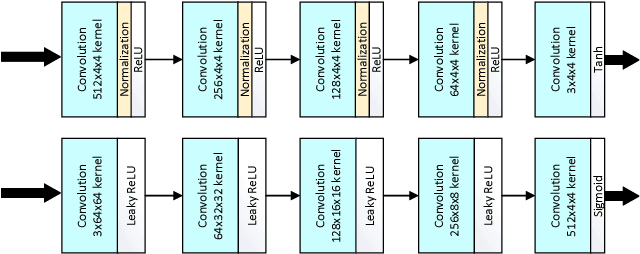
Generating iris images which look realistic is both an interesting and challenging problem. Most of the classical statistical models are not powerful enough to capture the complicated texture representation in iris images, and therefore fail to generate iris images which look realistic. In this work, we present a machine learning framework based on generative adversarial network (GAN), which is able to generate iris images sampled from a prior distribution (learned from a set of training images). We apply this framework to two popular iris databases, and generate images which look very realistic, and similar to the image distribution in those databases. Through experimental results, we show that the generated iris images have a good diversity, and are able to capture different part of the prior distribution.
Finger-GAN: Generating Realistic Fingerprint Images Using Connectivity Imposed GAN
Dec 25, 2018
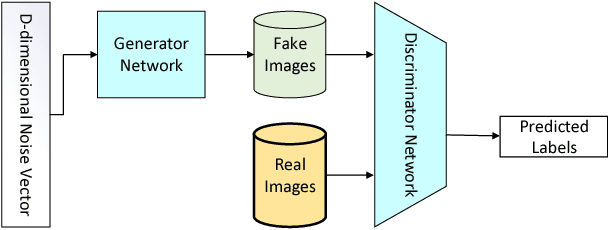
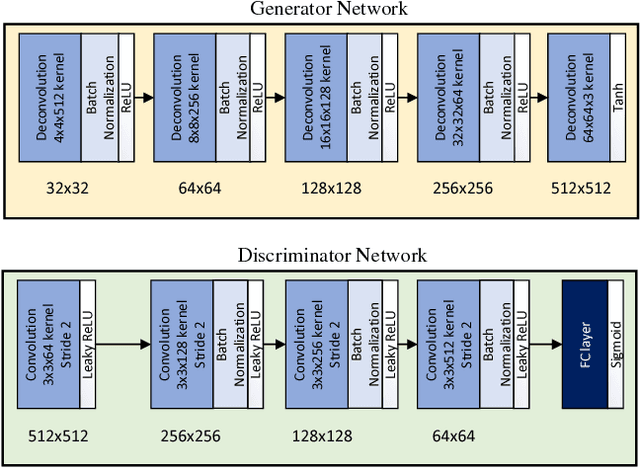
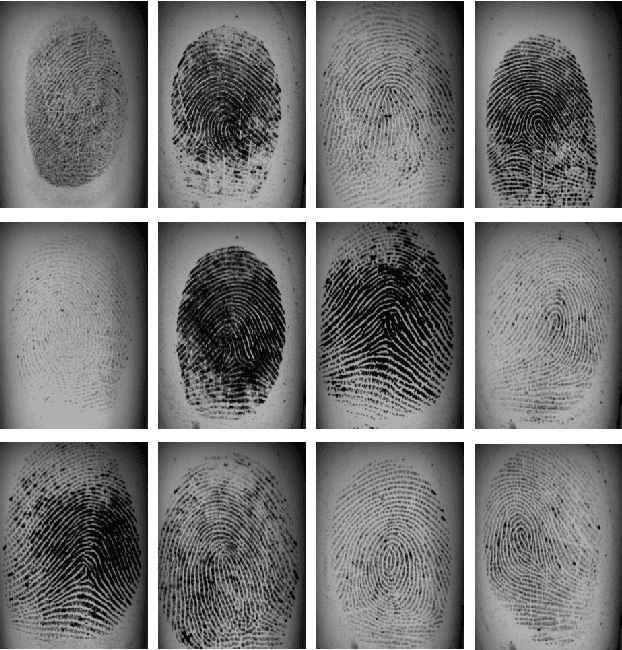
Generating realistic biometric images has been an interesting and, at the same time, challenging problem. Classical statistical models fail to generate realistic-looking fingerprint images, as they are not powerful enough to capture the complicated texture representation in fingerprint images. In this work, we present a machine learning framework based on generative adversarial networks (GAN), which is able to generate fingerprint images sampled from a prior distribution (learned from a set of training images). We also add a suitable regularization term to the loss function, to impose the connectivity of generated fingerprint images. This is highly desirable for fingerprints, as the lines in each finger are usually connected. We apply this framework to two popular fingerprint databases, and generate images which look very realistic, and similar to the samples in those databases. Through experimental results, we show that the generated fingerprint images have a good diversity, and are able to capture different parts of the prior distribution. We also evaluate the Frechet Inception distance (FID) of our proposed model, and show that our model is able to achieve good quantitative performance in terms of this score.
MTBI Identification From Diffusion MR Images Using Bag of Adversarial Visual Features
Jun 27, 2018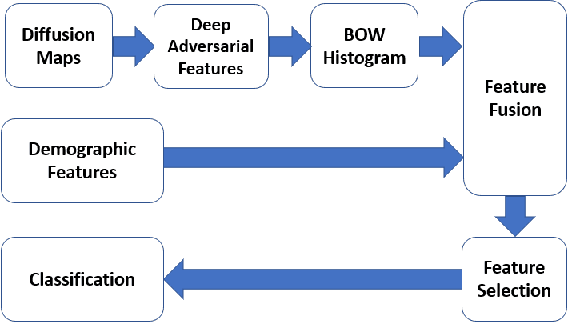
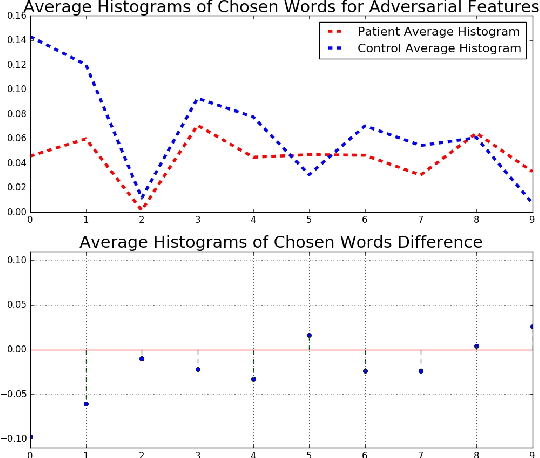


In this work, we propose bag of adversarial features (BAF) for identifying mild traumatic brain injury (MTBI) patients from their diffusion magnetic resonance images (MRI) (obtained within one month of injury) by incorporating unsupervised feature learning techniques. MTBI is a growing public health problem with an estimated incidence of over 1.7 million people annually in US. Diagnosis is based on clinical history and symptoms, and accurate, concrete measures of injury are lacking. Unlike most of previous works, which use hand-crafted features extracted from different parts of brain for MTBI classification, we employ feature learning algorithms to learn more discriminative representation for this task. A major challenge in this field thus far is the relatively small number of subjects available for training. This makes it difficult to use an end-to-end convolutional neural network to directly classify a subject from MR images. To overcome this challenge, we first apply an adversarial auto-encoder (with convolutional structure) to learn patch-level features, from overlapping image patches extracted from different brain regions. We then aggregate these features through a bag-of-word approach. We perform an extensive experimental study on a dataset of 227 subjects (including 109 MTBI patients, and 118 age and sex matched healthy controls), and compare the bag-of-deep-features with several previous approaches. Our experimental results show that the BAF significantly outperforms earlier works relying on the mean values of MR metrics in selected brain regions.
Ad-Net: Audio-Visual Convolutional Neural Network for Advertisement Detection In Videos
Jun 22, 2018
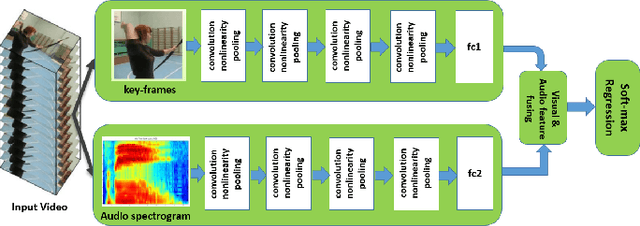
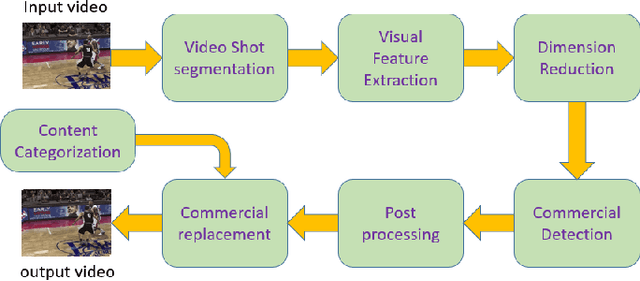
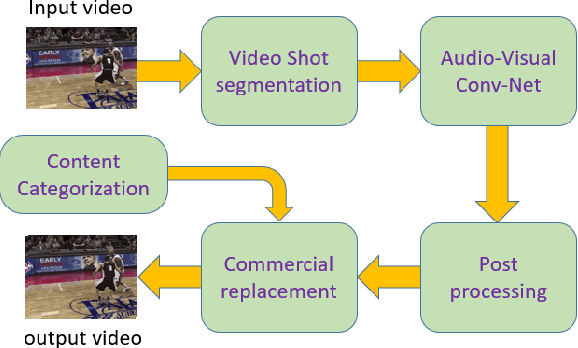
Personalized advertisement is a crucial task for many of the online businesses and video broadcasters. Many of today's broadcasters use the same commercial for all customers, but as one can imagine different viewers have different interests and it seems reasonable to have customized commercial for different group of people, chosen based on their demographic features, and history. In this project, we propose a framework, which gets the broadcast videos, analyzes them, detects the commercial and replaces it with a more suitable commercial. We propose a two-stream audio-visual convolutional neural network, that one branch analyzes the visual information and the other one analyzes the audio information, and then the audio and visual embedding are fused together, and are used for commercial detection, and content categorization. We show that using both the visual and audio content of the videos significantly improves the model performance for video analysis. This network is trained on a dataset of more than 50k regular video and commercial shots, and achieved much better performance compared to the models based on hand-crafted features.
A Deep Unsupervised Learning Approach Toward MTBI Identification Using Diffusion MRI
Apr 11, 2018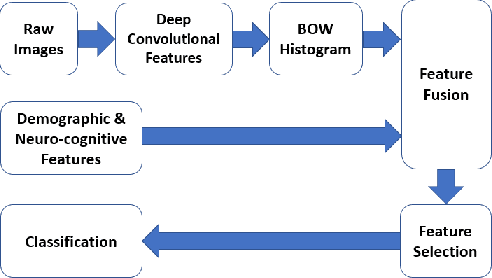
Mild traumatic brain injury is a growing public health problem with an estimated incidence of over 1.7 million people annually in US. Diagnosis is based on clinical history and symptoms, and accurate, concrete measures of injury are lacking. This work aims to directly use diffusion MR images obtained within one month of trauma to detect injury, by incorporating deep learning techniques. To overcome the challenge due to limited training data, we describe each brain region using the bag of word representation, which specifies the distribution of representative patch patterns. We apply a convolutional auto-encoder to learn the patch-level features, from overlapping image patches extracted from the MR images, to learn features from diffusion MR images of brain using an unsupervised approach. Our experimental results show that the bag of word representation using patch level features learnt by the auto encoder provides similar performance as that using the raw patch patterns, both significantly outperform earlier work relying on the mean values of MR metrics in selected brain regions.
Image Segmentation Using Subspace Representation and Sparse Decomposition
Apr 06, 2018
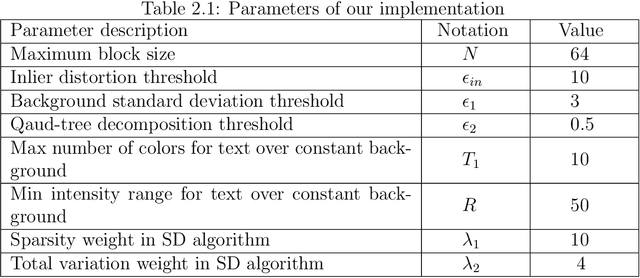


Image foreground extraction is a classical problem in image processing and vision, with a large range of applications. In this dissertation, we focus on the extraction of text and graphics in mixed-content images, and design novel approaches for various aspects of this problem. We first propose a sparse decomposition framework, which models the background by a subspace containing smooth basis vectors, and foreground as a sparse and connected component. We then formulate an optimization framework to solve this problem, by adding suitable regularizations to the cost function to promote the desired characteristics of each component. We present two techniques to solve the proposed optimization problem, one based on alternating direction method of multipliers (ADMM), and the other one based on robust regression. Promising results are obtained for screen content image segmentation using the proposed algorithm. We then propose a robust subspace learning algorithm for the representation of the background component using training images that could contain both background and foreground components, as well as noise. With the learnt subspace for the background, we can further improve the segmentation results, compared to using a fixed subspace. Lastly, we investigate a different class of signal/image decomposition problem, where only one signal component is active at each signal element. In this case, besides estimating each component, we need to find their supports, which can be specified by a binary mask. We propose a mixed-integer programming problem, that jointly estimates the two components and their supports through an alternating optimization scheme. We show the application of this algorithm on various problems, including image segmentation, video motion segmentation, and also separation of text from textured images.
Identifying Mild Traumatic Brain Injury Patients From MR Images Using Bag of Visual Words
Feb 14, 2018
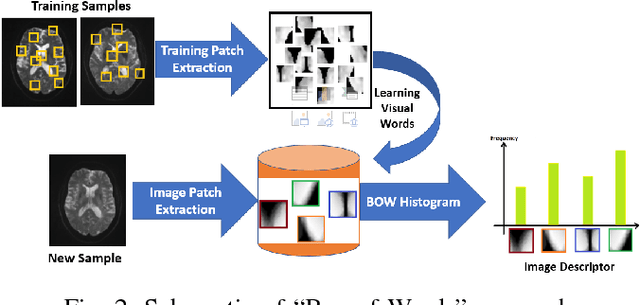
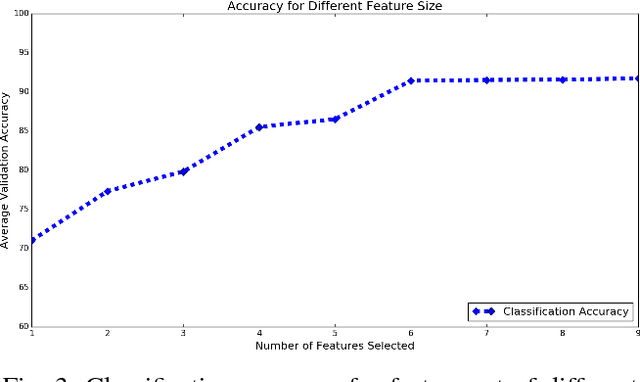
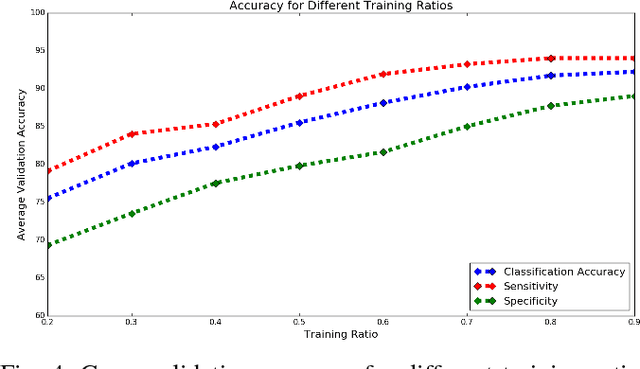
Mild traumatic brain injury (mTBI) is a growing public health problem with an estimated incidence of one million people annually in US. Neurocognitive tests are used to both assess the patient condition and to monitor the patient progress. This work aims to directly use MR images taken shortly after injury to detect whether a patient suffers from mTBI, by incorporating machine learning and computer vision techniques to learn features suitable discriminating between mTBI and normal patients. We focus on 3 regions in brain, and extract multiple patches from them, and use bag-of-visual-word technique to represent each subject as a histogram of representative patterns derived from patches from all training subjects. After extracting the features, we use greedy forward feature selection, to choose a subset of features which achieves highest accuracy. We show through experimental studies that BoW features perform better than the simple mean value features which were used previously.
Image Decomposition Using a Robust Regression Approach
Dec 04, 2017

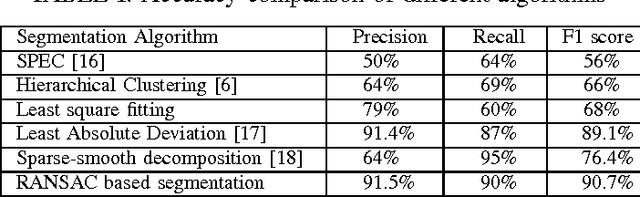
This paper considers how to separate text and/or graphics from smooth background in screen content and mixed content images and proposes an algorithm to perform this segmentation task. The proposed methods make use of the fact that the background in each block is usually smoothly varying and can be modeled well by a linear combination of a few smoothly varying basis functions, while the foreground text and graphics create sharp discontinuity. This algorithm separates the background and foreground pixels by trying to fit pixel values in the block into a smooth function using a robust regression method. The inlier pixels that can be well represented with the smooth model will be considered as background, while remaining outlier pixels will be considered foreground. We have also created a dataset of screen content images extracted from HEVC standard test sequences for screen content coding with their ground truth segmentation result which can be used for this task. The proposed algorithm has been tested on the dataset mentioned above and is shown to have superior performance over other methods, such as the hierarchical k-means clustering algorithm, shape primitive extraction and coding, and the least absolute deviation fitting scheme for foreground segmentation.