 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForest Representation Learning Guided by Margin Distribution
May 07, 2019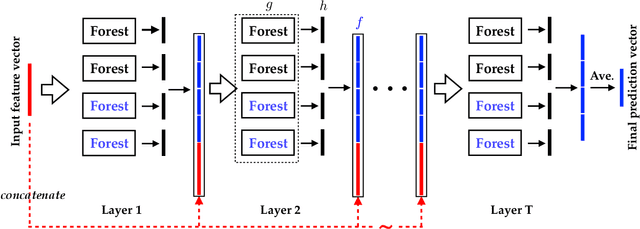
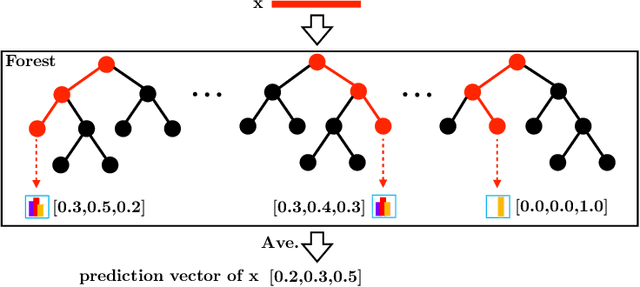
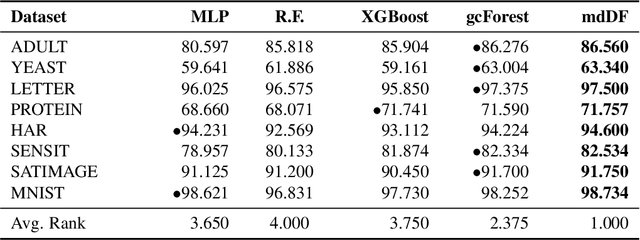
In this paper, we reformulate the forest representation learning approach as an additive model which boosts the augmented feature instead of the prediction. We substantially improve the upper bound of generalization gap from $\mathcal{O}(\sqrt\frac{\ln m}{m})$ to $\mathcal{O}(\frac{\ln m}{m})$, while $\lambda$ - the margin ratio between the margin standard deviation and the margin mean is small enough. This tighter upper bound inspires us to optimize the margin distribution ratio $\lambda$. Therefore, we design the margin distribution reweighting approach (mdDF) to achieve small ratio $\lambda$ by boosting the augmented feature. Experiments and visualizations confirm the effectiveness of the approach in terms of performance and representation learning ability. This study offers a novel understanding of the cascaded deep forest from the margin-theory perspective and further uses the mdDF approach to guide the layer-by-layer forest representation learning.
Optimal Margin Distribution Network
Dec 27, 2018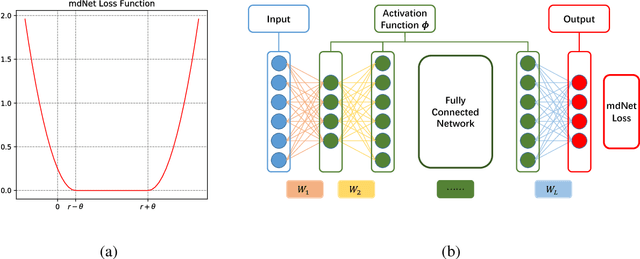

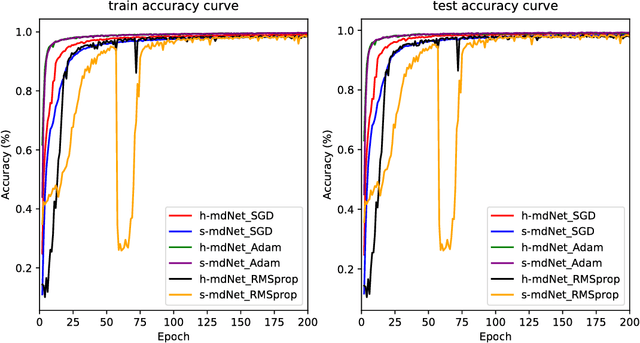
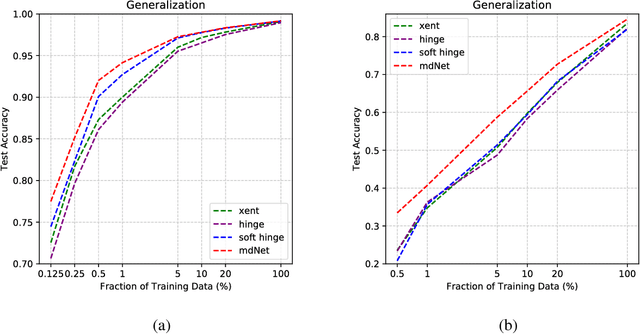
Recent research about margin theory has proved that maximizing the minimum margin like support vector machines does not necessarily lead to better performance, and instead, it is crucial to optimize the margin distribution. In the meantime, margin theory has been used to explain the empirical success of deep network in recent studies. In this paper, we present mdNet (the Optimal Margin Distribution Network), a network which embeds a loss function in regard to the optimal margin distribution. We give a theoretical analysis of our method using the PAC-Bayesian framework, which confirms the significance of the margin distribution for classification within the framework of deep networks. In addition, empirical results show that the mdNet model always outperforms the baseline cross-entropy loss model consistently across different regularization situations. And our mdNet model also outperforms the cross-entropy loss (Xent), hinge loss and soft hinge loss model in generalization task through limited training data.