 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation
Sep 04, 2024



Skin cancer segmentation poses a significant challenge in medical image analysis. Numerous existing solutions, predominantly CNN-based, face issues related to a lack of global contextual understanding. Alternatively, some approaches resort to large-scale Transformer models to bridge the global contextual gaps, but at the expense of model size and computational complexity. Finally many Transformer based approaches rely primarily on CNN based decoders overlooking the benefits of Transformer based decoding models. Recognizing these limitations, we address the need efficient lightweight solutions by introducing MobileUNETR, which aims to overcome the performance constraints associated with both CNNs and Transformers while minimizing model size, presenting a promising stride towards efficient image segmentation. MobileUNETR has 3 main features. 1) MobileUNETR comprises of a lightweight hybrid CNN-Transformer encoder to help balance local and global contextual feature extraction in an efficient manner; 2) A novel hybrid decoder that simultaneously utilizes low-level and global features at different resolutions within the decoding stage for accurate mask generation; 3) surpassing large and complex architectures, MobileUNETR achieves superior performance with 3 million parameters and a computational complexity of 1.3 GFLOP resulting in 10x and 23x reduction in parameters and FLOPS, respectively. Extensive experiments have been conducted to validate the effectiveness of our proposed method on four publicly available skin lesion segmentation datasets, including ISIC 2016, ISIC 2017, ISIC 2018, and PH2 datasets. The code will be publicly available at: https://github.com/OSUPCVLab/MobileUNETR.git
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
Apr 15, 2024



The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
Adaptive Few-Shot Learning PoC Ultrasound COVID-19 Diagnostic System
Sep 08, 2021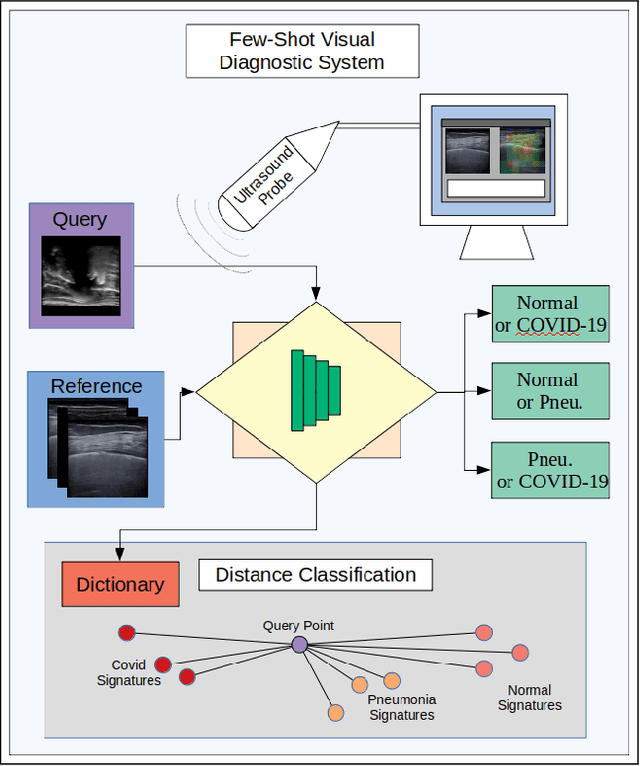
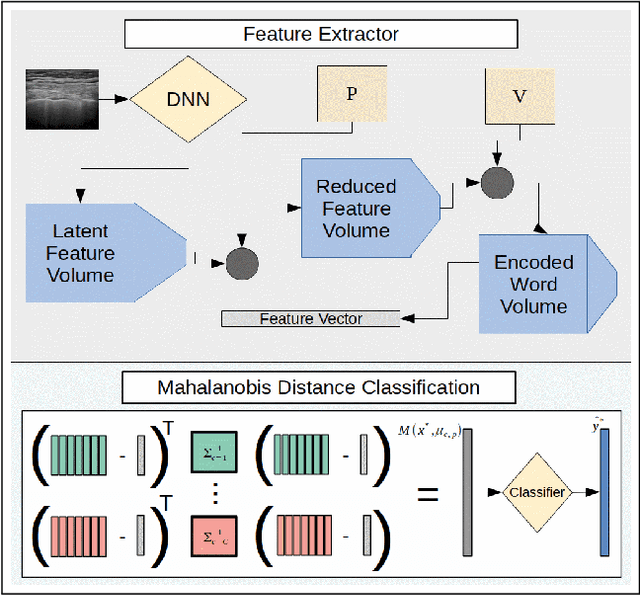
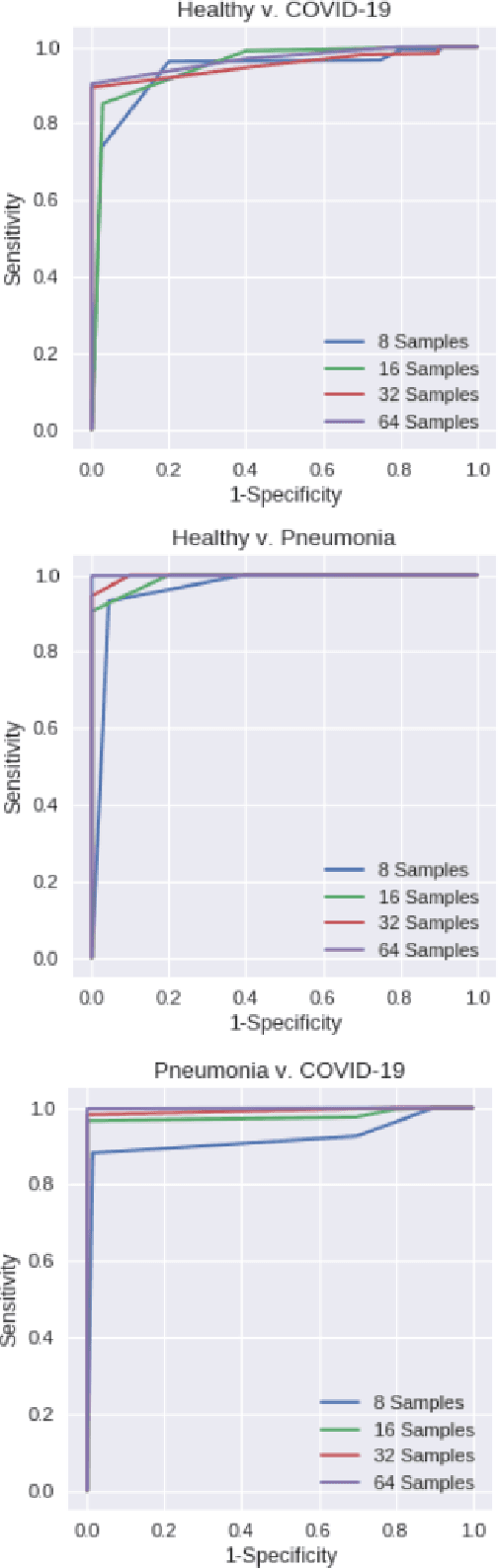

This paper presents a novel ultrasound imaging point-of-care (PoC) COVID-19 diagnostic system. The adaptive visual diagnostics utilize few-shot learning (FSL) to generate encoded disease state models that are stored and classified using a dictionary of knowns. The novel vocabulary based feature processing of the pipeline adapts the knowledge of a pretrained deep neural network to compress the ultrasound images into discrimative descriptions. The computational efficiency of the FSL approach enables high diagnostic deep learning performance in PoC settings, where training data is limited and the annotation process is not strictly controlled. The algorithm performance is evaluated on the open source COVID-19 POCUS Dataset to validate the system's ability to distinguish COVID-19, pneumonia, and healthy disease states. The results of the empirical analyses demonstrate the appropriate efficiency and accuracy for scalable PoC use. The code for this work will be made publicly available on GitHub upon acceptance.
POCFormer: A Lightweight Transformer Architecture for Detection of COVID-19 Using Point of Care Ultrasound
May 20, 2021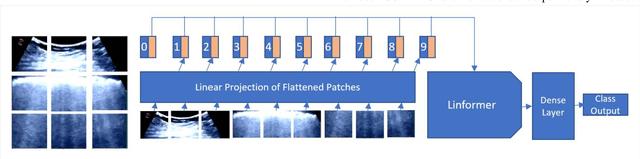
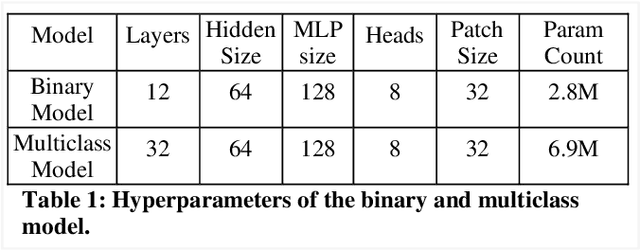
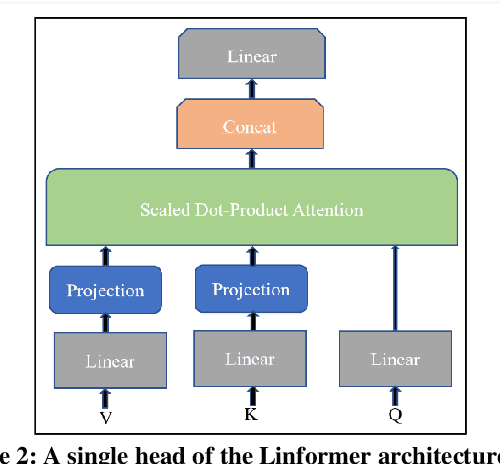
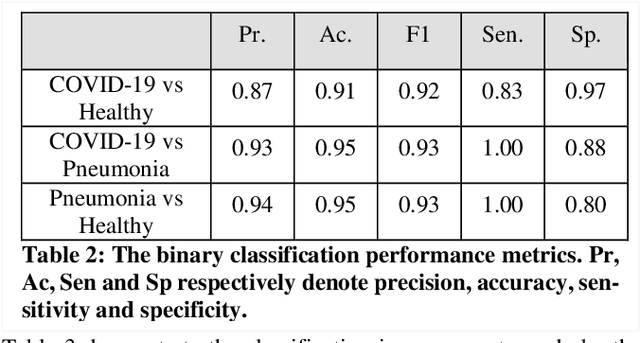
The rapid and seemingly endless expansion of COVID-19 can be traced back to the inefficiency and shortage of testing kits that offer accurate results in a timely manner. An emerging popular technique, which adopts improvements made in mobile ultrasound technology, allows for healthcare professionals to conduct rapid screenings on a large scale. We present an image-based solution that aims at automating the testing process which allows for rapid mass testing to be conducted with or without a trained medical professional that can be applied to rural environments and third world countries. Our contributions towards rapid large-scale testing include a novel deep learning architecture capable of analyzing ultrasound data that can run in real-time and significantly improve the current state-of-the-art detection accuracies using image-based COVID-19 detection.