 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainTorrent: A Peer-to-Peer Environment for Decentralized Federated Learning
May 16, 2019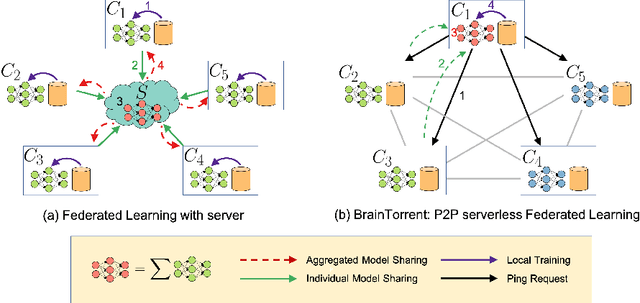
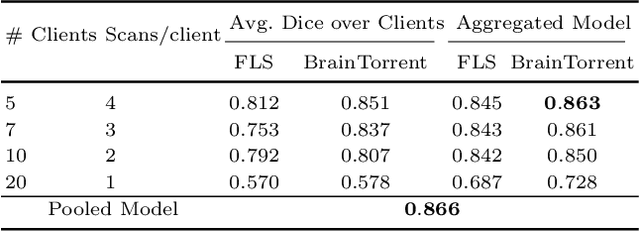

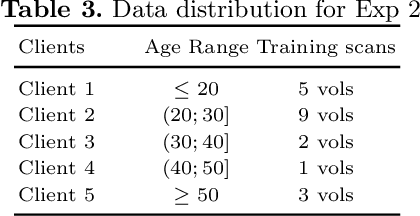
Access to sufficient annotated data is a common challenge in training deep neural networks on medical images. As annotating data is expensive and time-consuming, it is difficult for an individual medical center to reach large enough sample sizes to build their own, personalized models. As an alternative, data from all centers could be pooled to train a centralized model that everyone can use. However, such a strategy is often infeasible due to the privacy-sensitive nature of medical data. Recently, federated learning (FL) has been introduced to collaboratively learn a shared prediction model across centers without the need for sharing data. In FL, clients are locally training models on site-specific datasets for a few epochs and then sharing their model weights with a central server, which orchestrates the overall training process. Importantly, the sharing of models does not compromise patient privacy. A disadvantage of FL is the dependence on a central server, which requires all clients to agree on one trusted central body, and whose failure would disrupt the training process of all clients. In this paper, we introduce BrainTorrent, a new FL framework without a central server, particularly targeted towards medical applications. BrainTorrent presents a highly dynamic peer-to-peer environment, where all centers directly interact with each other without depending on a central body. We demonstrate the overall effectiveness of FL for the challenging task of whole brain segmentation and observe that the proposed server-less BrainTorrent approach does not only outperform the traditional server-based one but reaches a similar performance to a model trained on pooled data.
'Squeeze & Excite' Guided Few-Shot Segmentation of Volumetric Images
Feb 04, 2019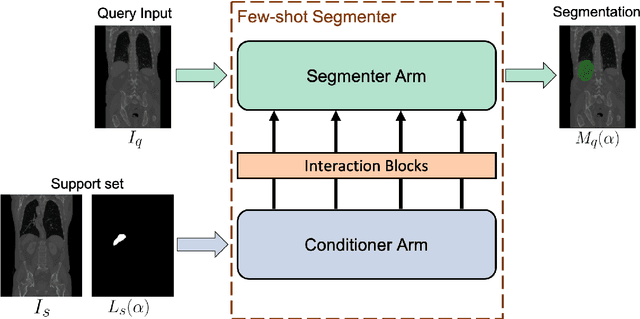
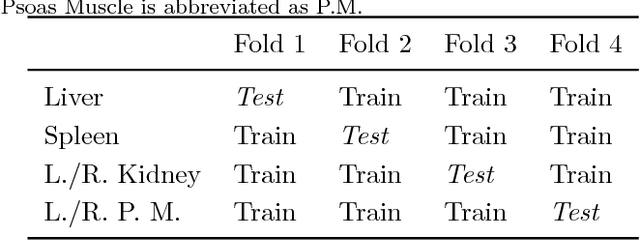
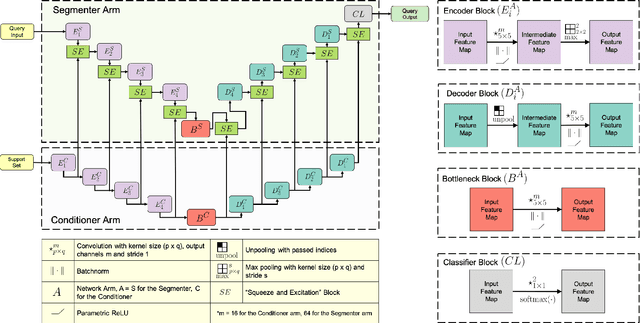
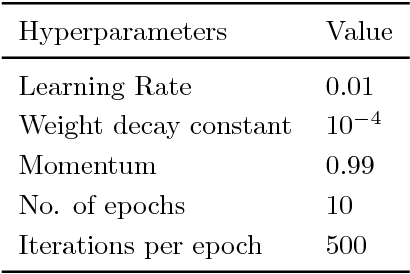
Deep neural networks enable highly accurate image segmentation, but require large amounts of manually annotated data for supervised training. Few-shot learning aims to address this shortcoming by learning a new class from a few annotated support examples. We introduce, for the first time, a novel few-shot framework, for the segmentation of volumetric medical images with only a few annotated slices. Compared to other related works in computer vision, the major challenges are the absence of pre-trained networks and the volumetric nature of medical scans. We address these challenges by proposing a new architecture for few-shot segmentation that incorporates 'squeeze & excite' blocks. Our two-armed architecture consists of a conditioner arm, which processes the annotated support input and generates a task representation which is used the relevant information for segmenting a new class. This representation is passed on to the segmenter arm that uses this information to segment the new query image. To facilitate efficient interaction between the conditioner and the segmenter arm, we propose to use 'channel squeeze & spatial excitation' blocks: a light-weight computational module, that enables heavy interaction between the both arms with negligible increase in model complexity. This contribution allows us to perform image segmentation without relying on a pre-trained model, which generally is unavailable for medical scans. Furthermore, we propose an efficient strategy for volumetric segmentation by optimally pairing a few slices of the support volume to all the slices of query volume. We perform the experiments for organ segmentation on whole-body contrast-enhanced CT scans from Visceral Dataset. Our proposed model outperforms multiple baselines and existing approaches with respect to the segmentation accuracy by a significant margin.