 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIISCNLP at SemEval-2016 Task 2: Interpretable STS with ILP based Multiple Chunk Aligner
May 04, 2016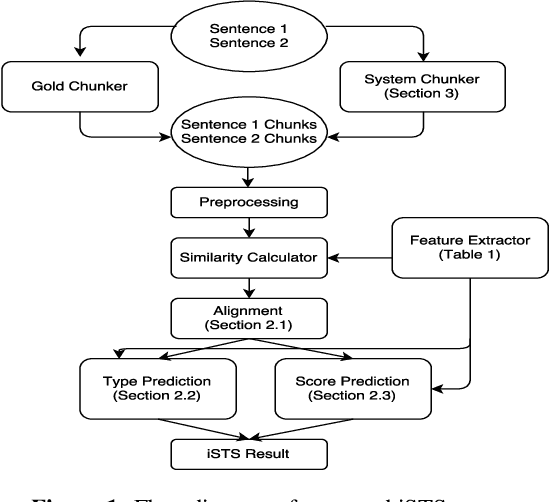
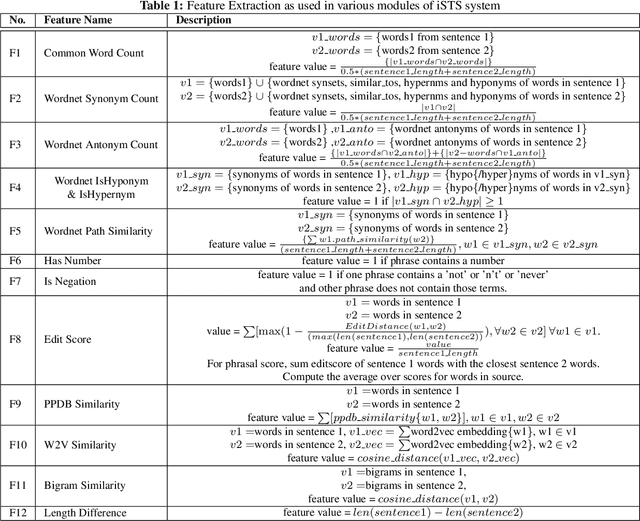
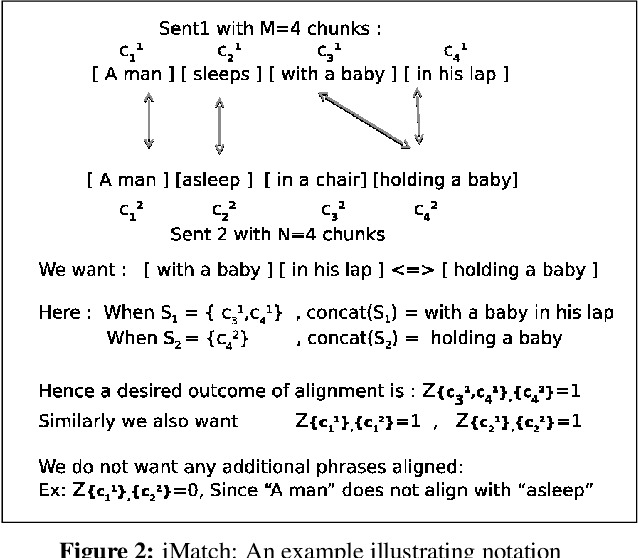
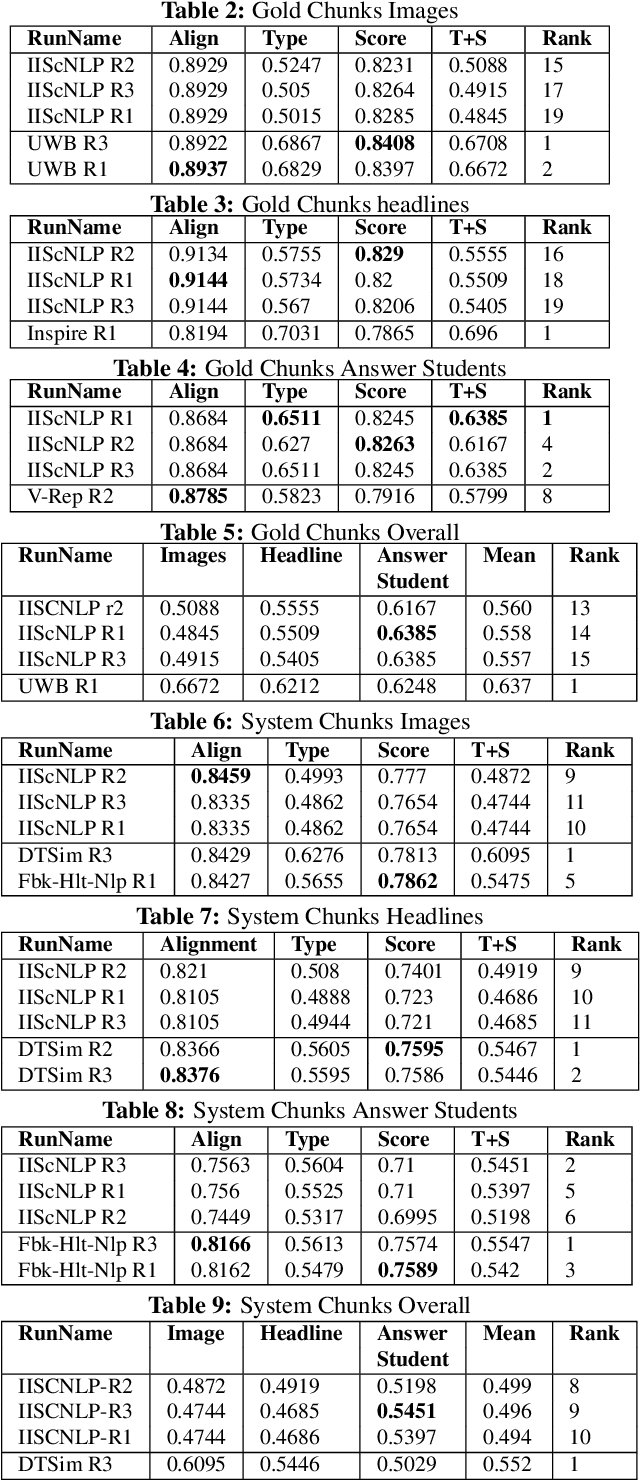
Interpretable semantic textual similarity (iSTS) task adds a crucial explanatory layer to pairwise sentence similarity. We address various components of this task: chunk level semantic alignment along with assignment of similarity type and score for aligned chunks with a novel system presented in this paper. We propose an algorithm, iMATCH, for the alignment of multiple non-contiguous chunks based on Integer Linear Programming (ILP). Similarity type and score assignment for pairs of chunks is done using a supervised multiclass classification technique based on Random Forrest Classifier. Results show that our algorithm iMATCH has low execution time and outperforms most other participating systems in terms of alignment score. Of the three datasets, we are top ranked for answer- students dataset in terms of overall score and have top alignment score for headlines dataset in the gold chunks track.
Nested Hierarchical Dirichlet Processes for Multi-Level Non-Parametric Admixture Modeling
Aug 27, 2015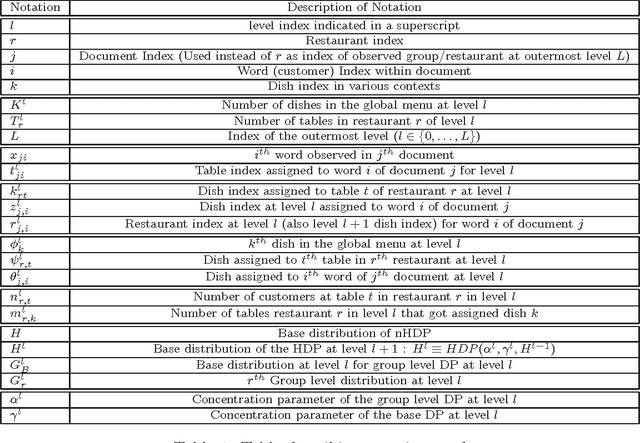
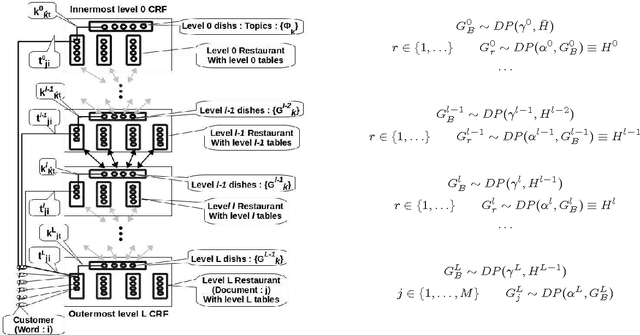
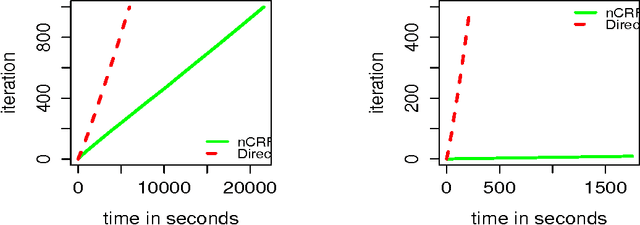

Dirichlet Process(DP) is a Bayesian non-parametric prior for infinite mixture modeling, where the number of mixture components grows with the number of data items. The Hierarchical Dirichlet Process (HDP), is an extension of DP for grouped data, often used for non-parametric topic modeling, where each group is a mixture over shared mixture densities. The Nested Dirichlet Process (nDP), on the other hand, is an extension of the DP for learning group level distributions from data, simultaneously clustering the groups. It allows group level distributions to be shared across groups in a non-parametric setting, leading to a non-parametric mixture of mixtures. The nCRF extends the nDP for multilevel non-parametric mixture modeling, enabling modeling topic hierarchies. However, the nDP and nCRF do not allow sharing of distributions as required in many applications, motivating the need for multi-level non-parametric admixture modeling. We address this gap by proposing multi-level nested HDPs (nHDP) where the base distribution of the HDP is itself a HDP at each level thereby leading to admixtures of admixtures at each level. Because of couplings between various HDP levels, scaling up is naturally a challenge during inference. We propose a multi-level nested Chinese Restaurant Franchise (nCRF) representation for the nested HDP, with which we outline an inference algorithm based on Gibbs Sampling. We evaluate our model with the two level nHDP for non-parametric entity topic modeling where an inner HDP creates a countably infinite set of topic mixtures and associates them with author entities, while an outer HDP associates documents with these author entities. In our experiments on two real world research corpora, the nHDP is able to generalize significantly better than existing models and detect missing author entities with a reasonable level of accuracy.
Mining Block I/O Traces for Cache Preloading with Sparse Temporal Non-parametric Mixture of Multivariate Poisson
Oct 13, 2014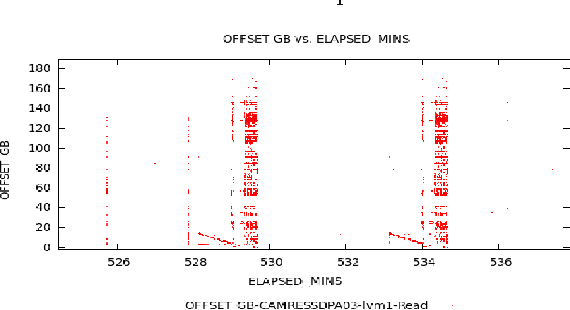
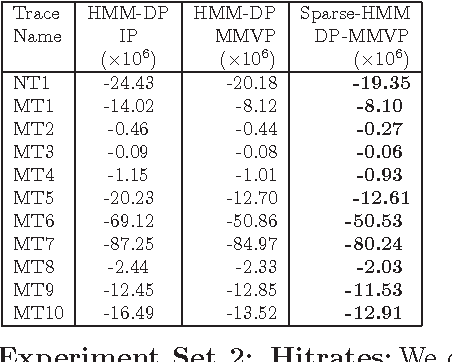

Existing caching strategies, in the storage domain, though well suited to exploit short range spatio-temporal patterns, are unable to leverage long-range motifs for improving hitrates. Motivated by this, we investigate novel Bayesian non-parametric modeling(BNP) techniques for count vectors, to capture long range correlations for cache preloading, by mining Block I/O traces. Such traces comprise of a sequence of memory accesses that can be aggregated into high-dimensional sparse correlated count vector sequences. While there are several state of the art BNP algorithms for clustering and their temporal extensions for prediction, there has been no work on exploring these for correlated count vectors. Our first contribution addresses this gap by proposing a DP based mixture model of Multivariate Poisson (DP-MMVP) and its temporal extension(HMM-DP-MMVP) that captures the full covariance structure of multivariate count data. However, modeling full covariance structure for count vectors is computationally expensive, particularly for high dimensional data. Hence, we exploit sparsity in our count vectors, and as our main contribution, introduce the Sparse DP mixture of multivariate Poisson(Sparse-DP-MMVP), generalizing our DP-MMVP mixture model, also leading to more efficient inference. We then discuss a temporal extension to our model for cache preloading. We take the first step towards mining historical data, to capture long range patterns in storage traces for cache preloading. Experimentally, we show a dramatic improvement in hitrates on benchmark traces and lay the groundwork for further research in storage domain to reduce latencies using data mining techniques to capture long range motifs.