 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARM-Net: Adaptive Relation Modeling Network for Structured Data
Jul 05, 2021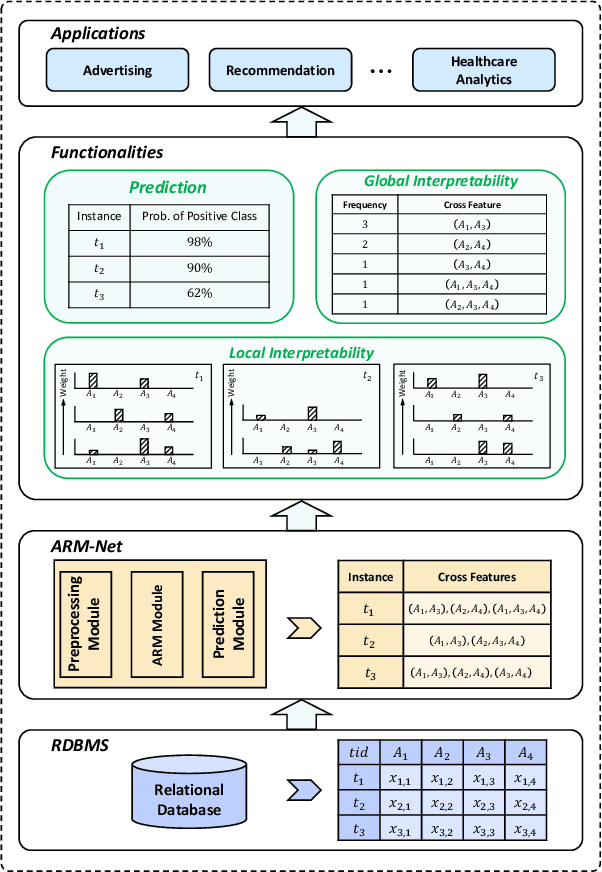
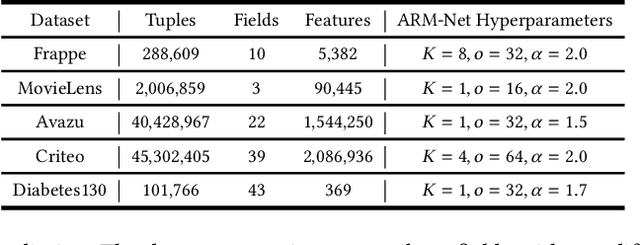
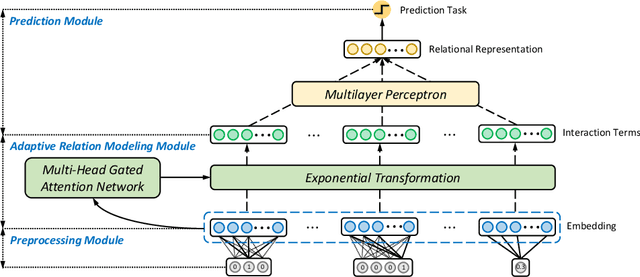
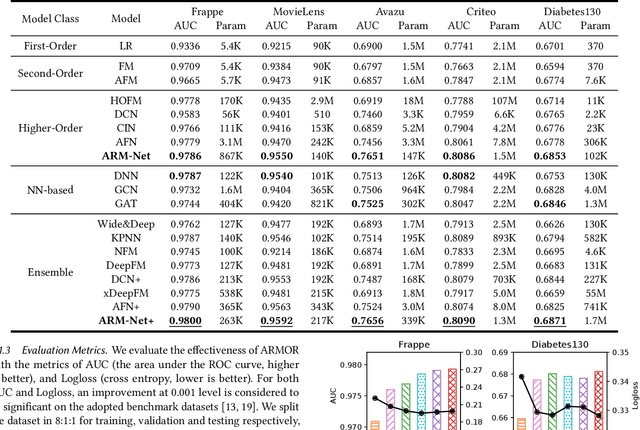
Relational databases are the de facto standard for storing and querying structured data, and extracting insights from structured data requires advanced analytics. Deep neural networks (DNNs) have achieved super-human prediction performance in particular data types, e.g., images. However, existing DNNs may not produce meaningful results when applied to structured data. The reason is that there are correlations and dependencies across combinations of attribute values in a table, and these do not follow simple additive patterns that can be easily mimicked by a DNN. The number of possible such cross features is combinatorial, making them computationally prohibitive to model. Furthermore, the deployment of learning models in real-world applications has also highlighted the need for interpretability, especially for high-stakes applications, which remains another issue of concern to DNNs. In this paper, we present ARM-Net, an adaptive relation modeling network tailored for structured data, and a lightweight framework ARMOR based on ARM-Net for relational data analytics. The key idea is to model feature interactions with cross features selectively and dynamically, by first transforming the input features into exponential space, and then determining the interaction order and interaction weights adaptively for each cross feature. We propose a novel sparse attention mechanism to dynamically generate the interaction weights given the input tuple, so that we can explicitly model cross features of arbitrary orders with noisy features filtered selectively. Then during model inference, ARM-Net can specify the cross features being used for each prediction for higher accuracy and better interpretability. Our extensive experiments on real-world datasets demonstrate that ARM-Net consistently outperforms existing models and provides more interpretable predictions for data-driven decision making.
Privacy Preserving Vertical Federated Learning for Tree-based Models
Aug 14, 2020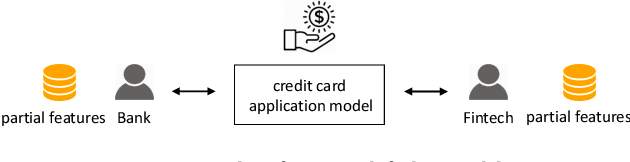

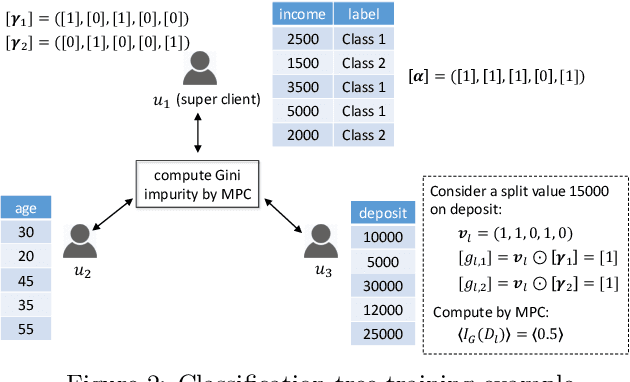
Federated learning (FL) is an emerging paradigm that enables multiple organizations to jointly train a model without revealing their private data to each other. This paper studies {\it vertical} federated learning, which tackles the scenarios where (i) collaborating organizations own data of the same set of users but with disjoint features, and (ii) only one organization holds the labels. We propose Pivot, a novel solution for privacy preserving vertical decision tree training and prediction, ensuring that no intermediate information is disclosed other than those the clients have agreed to release (i.e., the final tree model and the prediction output). Pivot does not rely on any trusted third party and provides protection against a semi-honest adversary that may compromise $m-1$ out of $m$ clients. We further identify two privacy leakages when the trained decision tree model is released in plaintext and propose an enhanced protocol to mitigate them. The proposed solution can also be extended to tree ensemble models, e.g., random forest (RF) and gradient boosting decision tree (GBDT) by treating single decision trees as building blocks. Theoretical and experimental analysis suggest that Pivot is efficient for the privacy achieved.
GraphTCN: Spatio-Temporal Interaction Modeling for Human Trajectory Prediction
Mar 26, 2020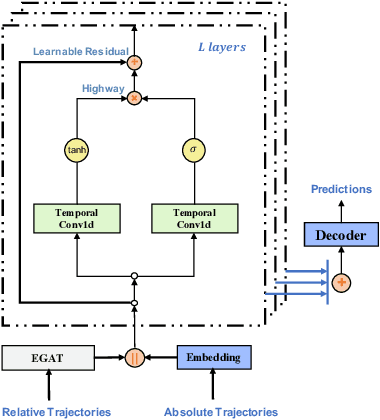
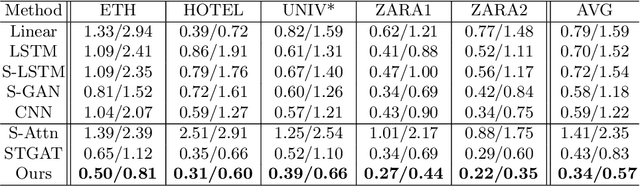

Trajectory prediction is a fundamental and challenging task to forecast the future path of the agents in autonomous applications with multi-agent interaction, where the agents need to predict the future movements of their neighbors to avoid collisions. To respond timely and precisely to the environment, high efficiency and accuracy are required in the prediction. Conventional approaches, e.g., LSTM-based models, take considerable computation costs in the prediction, especially for the long sequence prediction. To support a more efficient and accurate trajectory prediction, we instead propose a novel CNN-based spatial-temporal graph framework GraphTCN, which captures the spatial and temporal interactions in an input-aware manner. The spatial interaction between agents at each time step is captured with an edge graph attention network (EGAT), and the temporal interaction across time step is modeled with a modified gated convolutional network (CNN). In contrast to conventional models, both the spatial and temporal modeling in GraphTCN are computed within each local time window. Therefore, GraphTCN can be executed in parallel for much higher efficiency, and meanwhile with accuracy comparable to best-performing approaches. Experimental results confirm that GraphTCN achieves noticeably better performance in terms of both efficiency and accuracy compared with state-of-the-art methods on various trajectory prediction benchmark datasets.
TRACER: A Framework for Facilitating Accurate and Interpretable Analytics for High Stakes Applications
Mar 24, 2020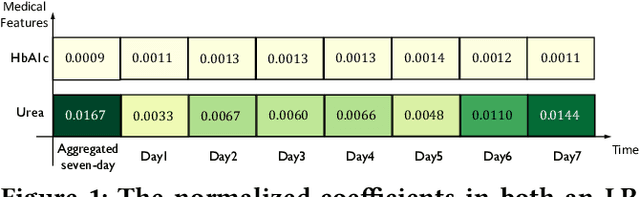
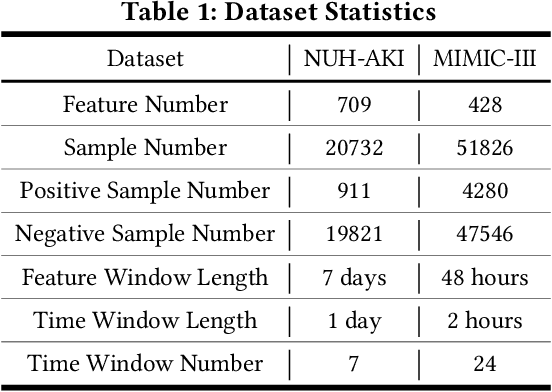
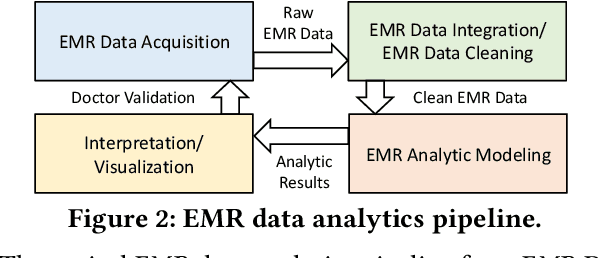
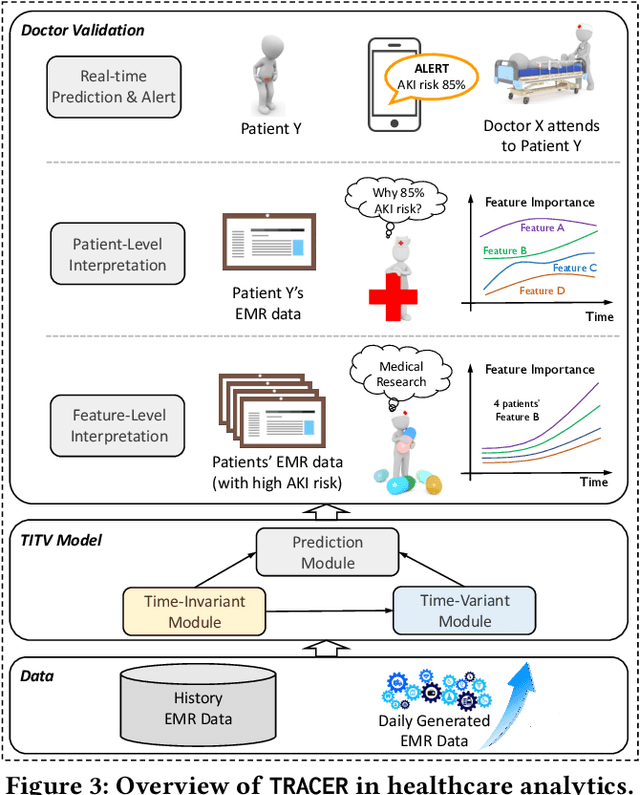
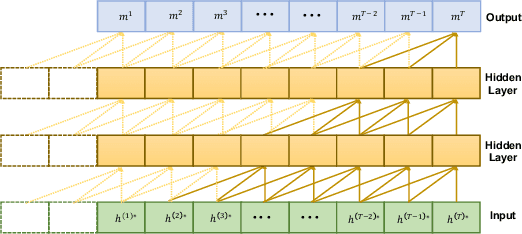
In high stakes applications such as healthcare and finance analytics, the interpretability of predictive models is required and necessary for domain practitioners to trust the predictions. Traditional machine learning models, e.g., logistic regression (LR), are easy to interpret in nature. However, many of these models aggregate time-series data without considering the temporal correlations and variations. Therefore, their performance cannot match up to recurrent neural network (RNN) based models, which are nonetheless difficult to interpret. In this paper, we propose a general framework TRACER to facilitate accurate and interpretable predictions, with a novel model TITV devised for healthcare analytics and other high stakes applications such as financial investment and risk management. Different from LR and other existing RNN-based models, TITV is designed to capture both the time-invariant and the time-variant feature importance using a feature-wise transformation subnetwork and a self-attention subnetwork, for the feature influence shared over the entire time series and the time-related importance respectively. Healthcare analytics is adopted as a driving use case, and we note that the proposed TRACER is also applicable to other domains, e.g., fintech. We evaluate the accuracy of TRACER extensively in two real-world hospital datasets, and our doctors/clinicians further validate the interpretability of TRACER in both the patient level and the feature level. Besides, TRACER is also validated in a high stakes financial application and a critical temperature forecasting application. The experimental results confirm that TRACER facilitates both accurate and interpretable analytics for high stakes applications.
Understanding Architectures Learnt by Cell-based Neural Architecture Search
Sep 23, 2019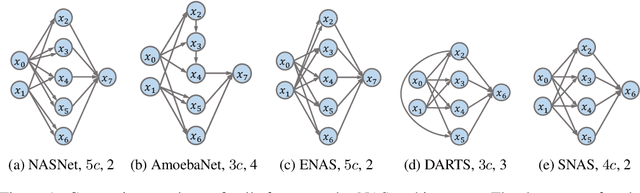
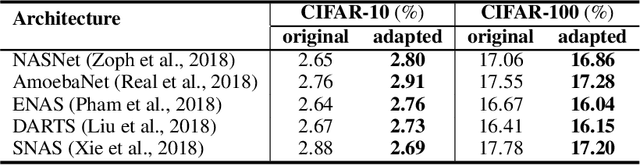
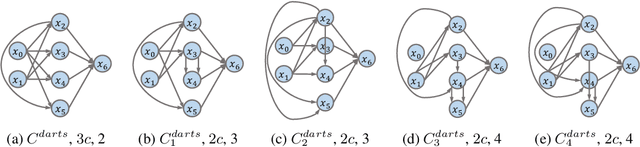
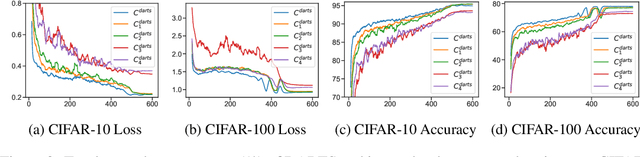
Neural architecture search (NAS) generates architectures automatically for given tasks, e.g., image classification and language modeling. Recently, various NAS algorithms have been proposed to improve search efficiency and effectiveness. However, little attention is paid to understand the generated architectures, including whether they share any commonality. In this paper, we analyze the generated architectures and give our explanations of their superior performance. We firstly uncover that the architectures generated by NAS algorithms share a common connection pattern, which contributes to their fast convergence. Consequently, these architectures are selected during architecture search. We further empirically and theoretically show that the fast convergence is the consequence of smooth loss landscape and accurate gradient information conducted by the common connection pattern. Contracting to universal recognition, we finally observe that popular NAS architectures do not always generalize better than the candidate architectures, encouraging us to re-think about the state-of-the-art NAS algorithms.
ISBNet: Instance-aware Selective Branching Network
May 23, 2019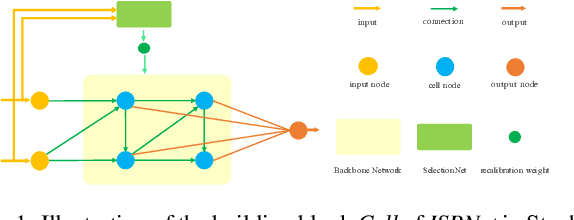
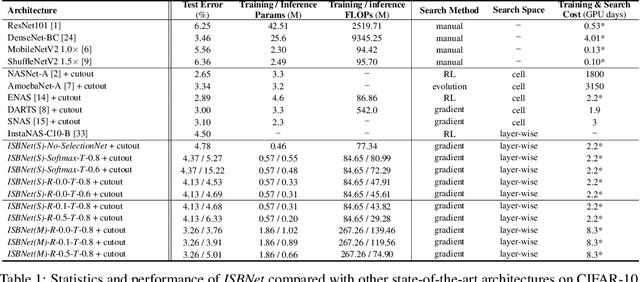
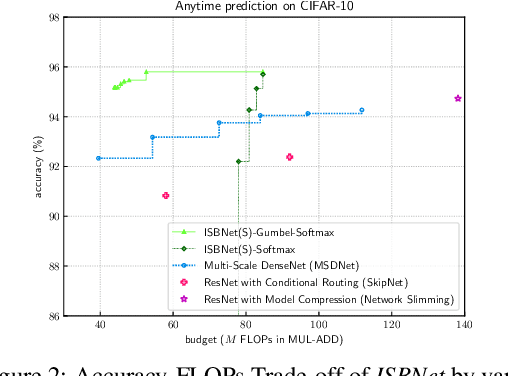

Recent years have witnessed growing interests in designing efficient neural networks and neural architecture search (NAS). Although remarkable efficiency and accuracy have been achieved, existing expert designed and NAS models neglect the fact that input instances are of varying complexity thus different amount of computation is required. Inference with a fixed model that processes all instances through the same transformations would waste plenty of computational resources. Therefore, customizing the model capacity in an instance-aware manner is highly demanded. To address this issue, we propose an Instance-aware Selective Branching Network-ISBNet, which supports efficient instance-level inference by selectively bypassing transformation branches of insignificant importance weight. These weights are determined dynamically by accompanying lightweight hypernetworks SelectionNets and further recalibrated by gumbel-softmax for sparse branch selection. Extensive experiments show that ISBNet achieves extremely efficient inference in terms of parameter size and FLOPs comparing to existing networks. For example, ISBNet takes only 8.03% parameters and 30.60% FLOPs of the state-of-the-art efficient network ShuffleNetV2 with comparable accuracy.
Effective and Efficient Dropout for Deep Convolutional Neural Networks
Apr 22, 2019
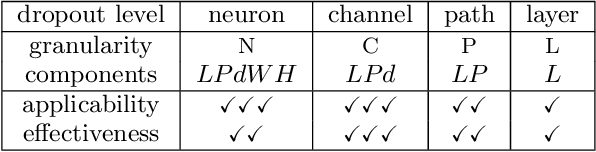
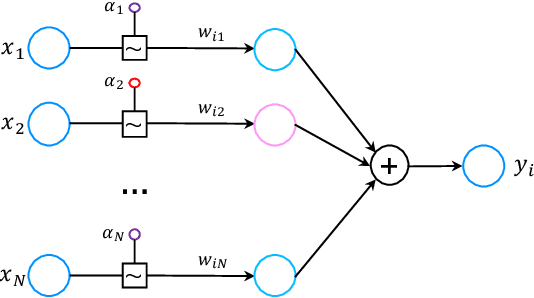
Machine-learning-based data-driven applications have become ubiquitous, e.g., health-care analysis and database system optimization. Big training data and large (deep) models are crucial for good performance. Dropout has been widely used as an efficient regularization technique to prevent large models from overfitting. However, many recent works show that dropout does not bring much performance improvement for deep convolutional neural networks (CNNs), a popular deep learning model for data-driven applications. In this paper, we formulate existing dropout methods for CNNs under the same analysis framework to investigate the failures. We attribute the failure to the conflicts between the dropout and the batch normalization operation after it. Consequently, we propose to change the order of the operations, which results in new building blocks of CNNs.Extensive experiments on benchmark datasets CIFAR, SVHN and ImageNet have been conducted to compare the existing building blocks and our new building blocks with different dropout methods. The results confirm the superiority of our proposed building blocks due to the regularization and implicit model ensemble effect of dropout. In particular, we improve over state-of-the-art CNNs with significantly better performance of 3.17%, 16.15%, 1.44%, 21.46% error rate on CIFAR-10, CIFAR-100, SVHN and ImageNet respectively.
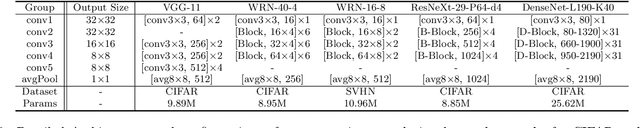
Model Slicing for Supporting Complex Analytics with Elastic Inference Cost and Resource Constraints
Apr 03, 2019

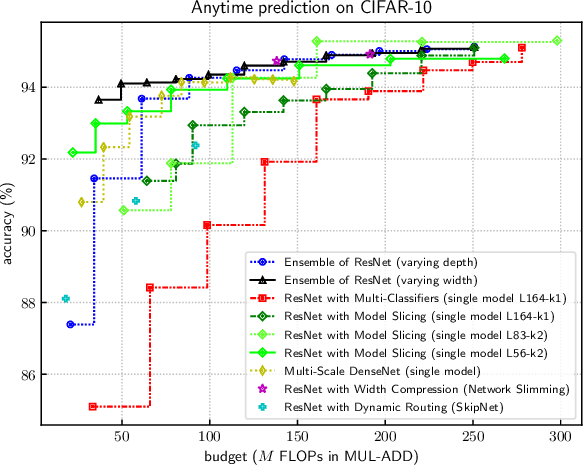
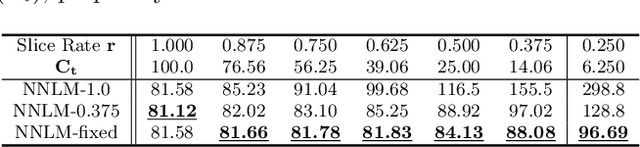
Deep learning models have been used to support analytics beyond simple aggregation, where deeper and wider models have been shown to yield great results. These models consume a huge amount of memory and computational operations. However, most of the large-scale industrial applications are often computational budget constrained. Current solutions are mainly based on model compression -- deploying a smaller model to save the computational resources. Meanwhile, the peak workload of inference service could be 10x higher than the average cases, with even unpredictable extreme cases. Lots of computational resources could be wasted during off-peak hours. On the other hand, the system may crash when the workload exceeds system design. Supporting such deep learning service with dynamic workload cost-efficiently remains to be a challenging problem. We address this conflict with a general and novel training scheme called model slicing, which enables deep learning models to provide predictions within prescribed computational resource budget dynamically. Model slicing could be viewed as an elastic computation solution without requiring more computation resources, but by slightly sacrificing prediction accuracy. In a nutshell, partially ordered relation is introduced to the basic components of each layer in the model, namely neurons in dense layers and channels in convolutional layers. Specifically, if one component participates in the forward pass, then all of its preceding components are also activated. Dynamically trained under such structural constraint, we can slice a narrower sub-model during inference whose run-time memory and computational operation consumption is roughly quadratic to the width controlled by a single parameter slice rate. Extensive experiments show that models trained with model slicing can support elastic inference cost effectively with minimum performance loss.