 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYN2REAL: Leveraging Task Arithmetic for Mitigating Synthetic-Real Discrepancies in ASR Domain Adaptation
Jun 05, 2024



Recent advancements in large language models (LLMs) have introduced the 'task vector' concept, which has significantly impacted various domains but remains underexplored in speech recognition. This paper presents a novel 'SYN2REAL' task vector for domain adaptation in automatic speech recognition (ASR), specifically targeting text-only domains. Traditional fine-tuning on synthetic speech often results in performance degradation due to acoustic mismatches. To address this issue, we propose creating a 'SYN2REAL' vector by subtracting the parameter differences between models fine-tuned on real and synthetic speech. This vector effectively bridges the gap between the two domains. Experiments on the SLURP dataset demonstrate that our approach yields an average improvement of 11.15% in word error rate for unseen target domains, highlighting the potential of task vectors in enhancing speech domain adaptation.
Step by Step to Fairness: Attributing Societal Bias in Task-oriented Dialogue Systems
Nov 14, 2023



Recent works have shown considerable improvements in task-oriented dialogue (TOD) systems by utilizing pretrained large language models (LLMs) in an end-to-end manner. However, the biased behavior of each component in a TOD system and the error propagation issue in the end-to-end framework can lead to seriously biased TOD responses. Existing works of fairness only focus on the total bias of a system. In this paper, we propose a diagnosis method to attribute bias to each component of a TOD system. With the proposed attribution method, we can gain a deeper understanding of the sources of bias. Additionally, researchers can mitigate biased model behavior at a more granular level. We conduct experiments to attribute the TOD system's bias toward three demographic axes: gender, age, and race. Experimental results show that the bias of a TOD system usually comes from the response generation model.
Learning from Red Teaming: Gender Bias Provocation and Mitigation in Large Language Models
Oct 17, 2023



Recently, researchers have made considerable improvements in dialogue systems with the progress of large language models (LLMs) such as ChatGPT and GPT-4. These LLM-based chatbots encode the potential biases while retaining disparities that can harm humans during interactions. The traditional biases investigation methods often rely on human-written test cases. However, these test cases are usually expensive and limited. In this work, we propose a first-of-its-kind method that automatically generates test cases to detect LLMs' potential gender bias. We apply our method to three well-known LLMs and find that the generated test cases effectively identify the presence of biases. To address the biases identified, we propose a mitigation strategy that uses the generated test cases as demonstrations for in-context learning to circumvent the need for parameter fine-tuning. The experimental results show that LLMs generate fairer responses with the proposed approach.
Annealing Self-Distillation Rectification Improves Adversarial Training
May 20, 2023



In standard adversarial training, models are optimized to fit one-hot labels within allowable adversarial perturbation budgets. However, the ignorance of underlying distribution shifts brought by perturbations causes the problem of robust overfitting. To address this issue and enhance adversarial robustness, we analyze the characteristics of robust models and identify that robust models tend to produce smoother and well-calibrated outputs. Based on the observation, we propose a simple yet effective method, Annealing Self-Distillation Rectification (ADR), which generates soft labels as a better guidance mechanism that accurately reflects the distribution shift under attack during adversarial training. By utilizing ADR, we can obtain rectified distributions that significantly improve model robustness without the need for pre-trained models or extensive extra computation. Moreover, our method facilitates seamless plug-and-play integration with other adversarial training techniques by replacing the hard labels in their objectives. We demonstrate the efficacy of ADR through extensive experiments and strong performances across datasets.
Position Matters! Empirical Study of Order Effect in Knowledge-grounded Dialogue
Feb 12, 2023



With the power of large pretrained language models, various research works have integrated knowledge into dialogue systems. The traditional techniques treat knowledge as part of the input sequence for the dialogue system, prepending a set of knowledge statements in front of dialogue history. However, such a mechanism forces knowledge sets to be concatenated in an ordered manner, making models implicitly pay imbalanced attention to the sets during training. In this paper, we first investigate how the order of the knowledge set can influence autoregressive dialogue systems' responses. We conduct experiments on two commonly used dialogue datasets with two types of transformer-based models and find that models view the input knowledge unequally. To this end, we propose a simple and novel technique to alleviate the order effect by modifying the position embeddings of knowledge input in these models. With the proposed position embedding method, the experimental results show that each knowledge statement is uniformly considered to generate responses.
QCRS: Improve Randomized Smoothing using Quasi-Concave Optimization
Feb 01, 2023



Randomized smoothing is currently the state-of-the-art method that provides certified robustness for deep neural networks. However, it often cannot achieve an adequate certified region on real-world datasets. One way to obtain a larger certified region is to use an input-specific algorithm instead of using a fixed Gaussian filter for all data points. Several methods based on this idea have been proposed, but they either suffer from high computational costs or gain marginal improvement in certified radius. In this work, we show that by exploiting the quasiconvex problem structure, we can find the optimal certified radii for most data points with slight computational overhead. This observation leads to an efficient and effective input-specific randomized smoothing algorithm. We conduct extensive experiments and empirical analysis on Cifar10 and ImageNet. The results show that the proposed method significantly enhances the certified radii with low computational overhead.
Fair Robust Active Learning by Joint Inconsistency
Sep 22, 2022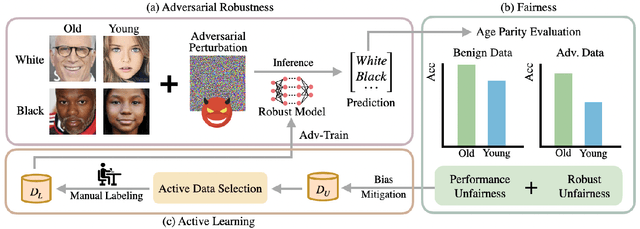
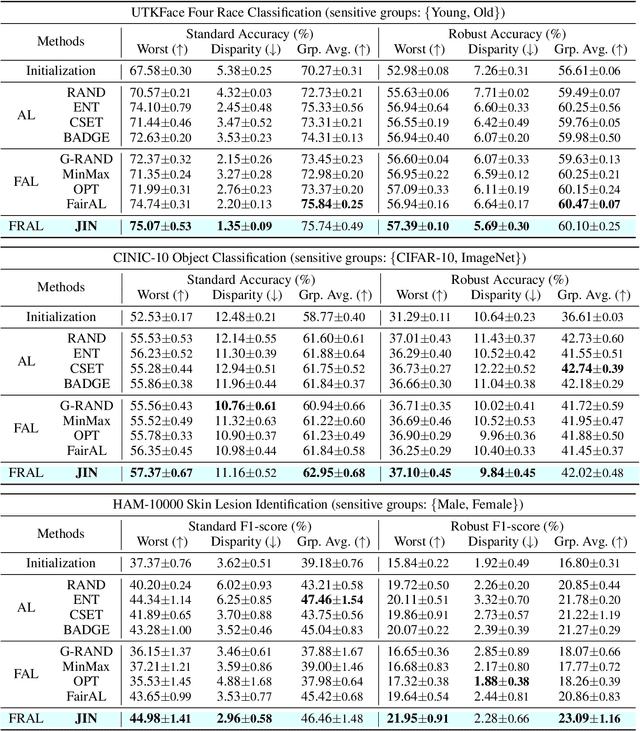
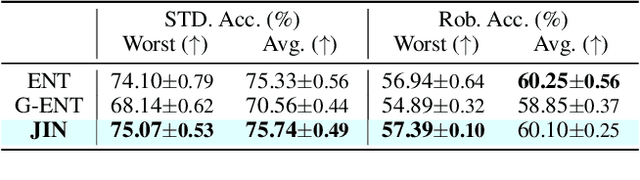
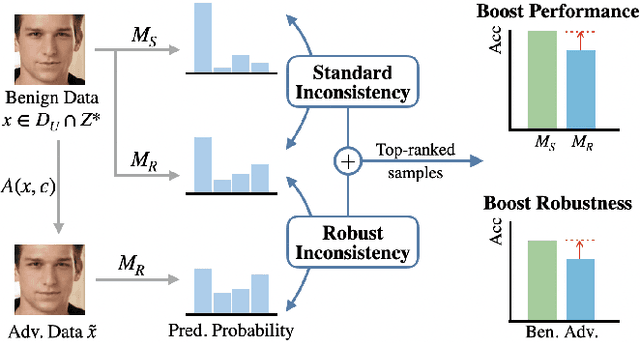
Fair Active Learning (FAL) utilized active learning techniques to achieve high model performance with limited data and to reach fairness between sensitive groups (e.g., genders). However, the impact of the adversarial attack, which is vital for various safety-critical machine learning applications, is not yet addressed in FAL. Observing this, we introduce a novel task, Fair Robust Active Learning (FRAL), integrating conventional FAL and adversarial robustness. FRAL requires ML models to leverage active learning techniques to jointly achieve equalized performance on benign data and equalized robustness against adversarial attacks between groups. In this new task, previous FAL methods generally face the problem of unbearable computational burden and ineffectiveness. Therefore, we develop a simple yet effective FRAL strategy by Joint INconsistency (JIN). To efficiently find samples that can boost the performance and robustness of disadvantaged groups for labeling, our method exploits the prediction inconsistency between benign and adversarial samples as well as between standard and robust models. Extensive experiments under diverse datasets and sensitive groups demonstrate that our method not only achieves fairer performance on benign samples but also obtains fairer robustness under white-box PGD attacks compared with existing active learning and FAL baselines. We are optimistic that FRAL would pave a new path for developing safe and robust ML research and applications such as facial attribute recognition in biometrics systems.
Enhancing Targeted Attack Transferability via Diversified Weight Pruning
Aug 18, 2022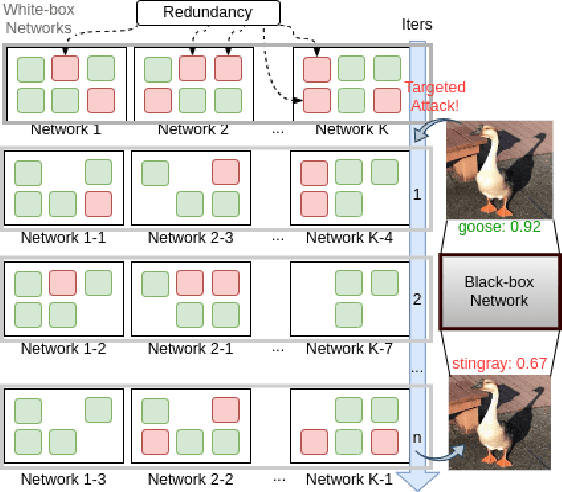
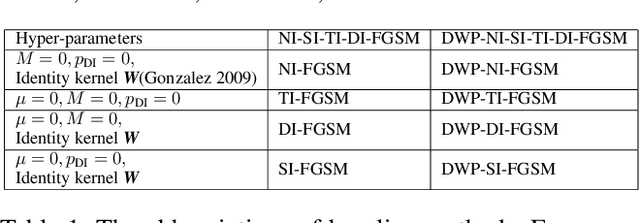
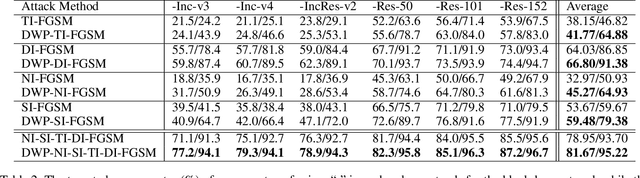
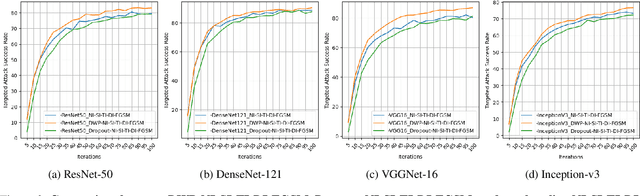
Malicious attackers can generate targeted adversarial examples by imposing human-imperceptible noise on images, forcing neural network models to produce specific incorrect outputs. With cross-model transferable adversarial examples, the vulnerability of neural networks remains even if the model information is kept secret from the attacker. Recent studies have shown the effectiveness of ensemble-based methods in generating transferable adversarial examples. However, existing methods fall short under the more challenging scenario of creating targeted attacks transferable among distinct models. In this work, we propose Diversified Weight Pruning (DWP) to further enhance the ensemble-based methods by leveraging the weight pruning method commonly used in model compression. Specifically, we obtain multiple diverse models by a random weight pruning method. These models preserve similar accuracies and can serve as additional models for ensemble-based methods, yielding stronger transferable targeted attacks. Experiments on ImageNet-Compatible Dataset under the more challenging scenarios are provided: transferring to distinct architectures and to adversarially trained models. The results show that our proposed DWP improves the targeted attack success rates with up to 4.1% and 8.0% on the combination of state-of-the-art methods, respectively
Few-shot Prompting Towards Controllable Response Generation
Jun 09, 2022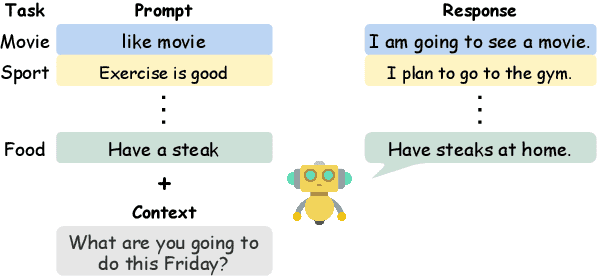
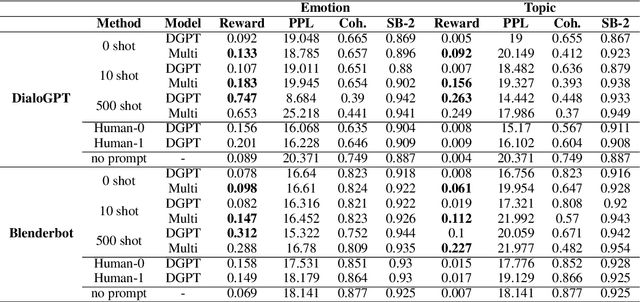
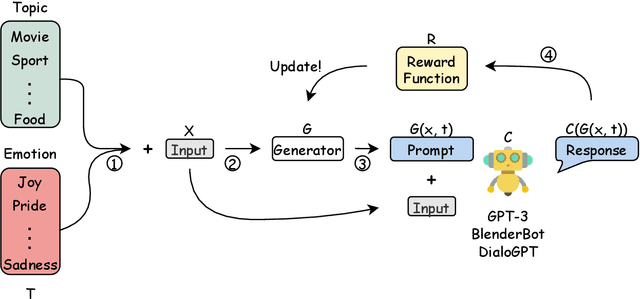
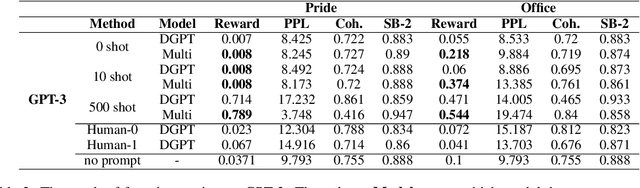
Much literature has shown that prompt-based learning is an efficient method to make use of the large pre-trained language model. Recent works also exhibit the possibility of steering a chatbot's output by plugging in an appropriate prompt. Gradient-based methods are often used to perturb the prompts. However, some language models are not even available to the public. In this work, we first explored the combination of prompting and reinforcement learning (RL) to steer models' generation without accessing any of the models' parameters. Second, to reduce the training effort and enhance the generalizability to the unseen task, we apply multi-task learning to make the model learn to generalize to new tasks better. The experiment results show that our proposed method can successfully control several state-of-the-art (SOTA) dialogue models without accessing their parameters. Furthermore, the model demonstrates the strong ability to quickly adapt to an unseen task in fewer steps than the baseline model.
UnMask: Adversarial Detection and Defense Through Robust Feature Alignment
Feb 21, 2020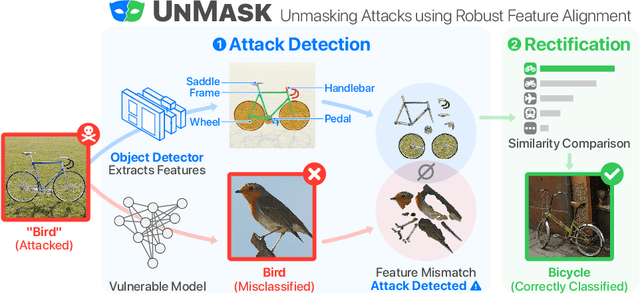
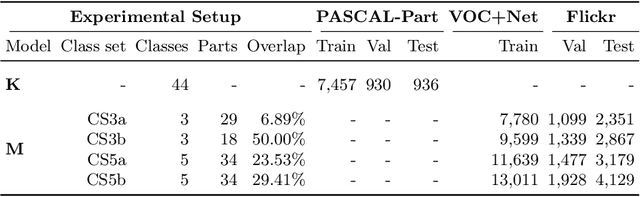
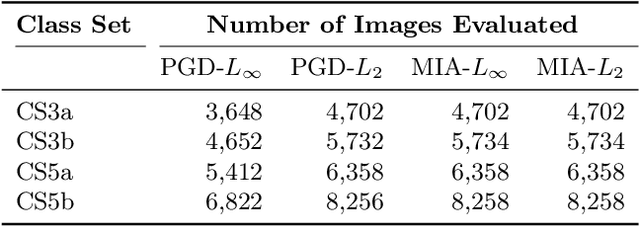
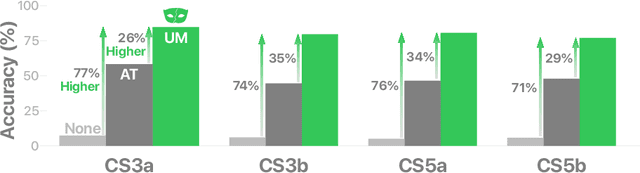
Deep learning models are being integrated into a wide range of high-impact, security-critical systems, from self-driving cars to medical diagnosis. However, recent research has demonstrated that many of these deep learning architectures are vulnerable to adversarial attacks--highlighting the vital need for defensive techniques to detect and mitigate these attacks before they occur. To combat these adversarial attacks, we developed UnMask, an adversarial detection and defense framework based on robust feature alignment. The core idea behind UnMask is to protect these models by verifying that an image's predicted class ("bird") contains the expected robust features (e.g., beak, wings, eyes). For example, if an image is classified as "bird", but the extracted features are wheel, saddle and frame, the model may be under attack. UnMask detects such attacks and defends the model by rectifying the misclassification, re-classifying the image based on its robust features. Our extensive evaluation shows that UnMask (1) detects up to 96.75% of attacks, with a false positive rate of 9.66% and (2) defends the model by correctly classifying up to 93% of adversarial images produced by the current strongest attack, Projected Gradient Descent, in the gray-box setting. UnMask provides significantly better protection than adversarial training across 8 attack vectors, averaging 31.18% higher accuracy. Our proposed method is architecture agnostic and fast. We open source the code repository and data with this paper: https://github.com/unmaskd/unmask.