 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthical Fairness without Demographics in Human-Centered AI
Mar 17, 2026Computational models are increasingly embedded in human-centered domains such as healthcare, education, workplace analytics, and digital well-being, where their predictions directly influence individual outcomes and collective welfare. In such contexts, achieving high accuracy alone is insufficient; models must also act ethically and equitably across diverse populations. However, fair AI approaches that rely on demographic attributes are impractical, as such information is often unavailable, privacy-sensitive, or restricted by regulatory frameworks. Moreover, conventional parity-based fairness approaches, while aiming for equity, can inadvertently violate core ethical principles by trading off subgroup performance or stability. To address this challenge, we present Flare (Fisher-guided LAtent-subgroup learning with do-no-harm REgularization), the first demographic-agnostic framework that aligns algorithmic fairness with ethical principles through the geometry of optimization. Flare leverages Fisher Information to regularize curvature, uncovering latent disparities in model behavior without access to demographic or sensitive attributes. By integrating representation, loss, and curvature signals, it identifies hidden performance strata and adaptively refines them through collaborative but do-no-harm optimization, enhancing each subgroup's performance while preserving global stability and ethical balance. We also introduce BHE (Beneficence-Harm Avoidance-Equity), a novel metric suite that operationalizes ethical fairness evaluation beyond statistical parity. Extensive evaluations across diverse physiological (EDA), behavioral (IHS), and clinical (OhioT1DM) datasets show that Flare consistently enhances ethical fairness compared to state-of-the-art baselines.
Generalization Gaps in Political Fake News Detection: An Empirical Study on the LIAR Dataset
Dec 20, 2025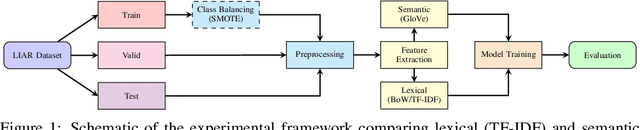
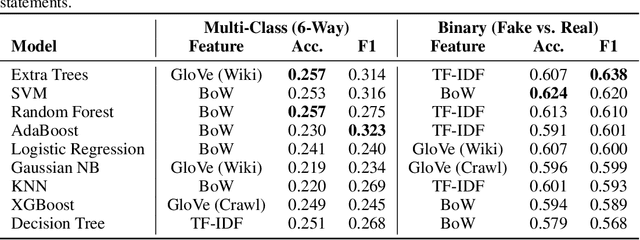
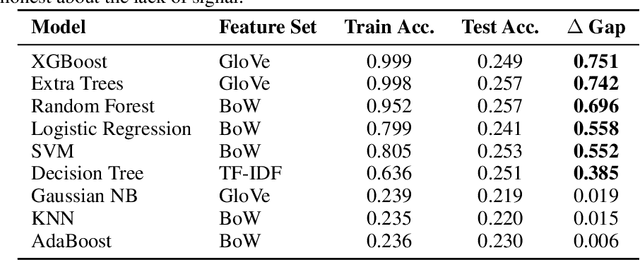
The proliferation of linguistically subtle political disinformation poses a significant challenge to automated fact-checking systems. Despite increasing emphasis on complex neural architectures, the empirical limits of text-only linguistic modeling remain underexplored. We present a systematic diagnostic evaluation of nine machine learning algorithms on the LIAR benchmark. By isolating lexical features (Bag-of-Words, TF-IDF) and semantic embeddings (GloVe), we uncover a hard "Performance Ceiling", with fine-grained classification not exceeding a Weighted F1-score of 0.32 across models. Crucially, a simple linear SVM (Accuracy: 0.624) matches the performance of pre-trained Transformers such as RoBERTa (Accuracy: 0.620), suggesting that model capacity is not the primary bottleneck. We further diagnose a massive "Generalization Gap" in tree-based ensembles, which achieve more than 99% training accuracy but collapse to approximately 25% on test data, indicating reliance on lexical memorization rather than semantic inference. Synthetic data augmentation via SMOTE yields no meaningful gains, confirming that the limitation is semantic (feature ambiguity) rather than distributional. These findings indicate that for political fact-checking, increasing model complexity without incorporating external knowledge yields diminishing returns.