 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe, Multi-Agent, Reinforcement Learning for Autonomous Driving
Oct 11, 2016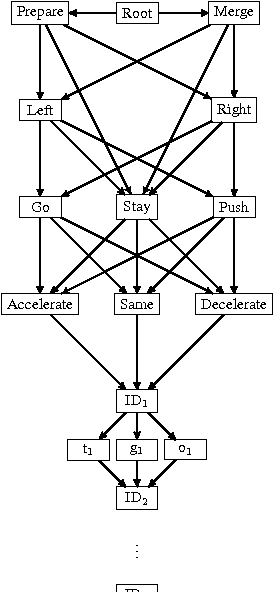
Autonomous driving is a multi-agent setting where the host vehicle must apply sophisticated negotiation skills with other road users when overtaking, giving way, merging, taking left and right turns and while pushing ahead in unstructured urban roadways. Since there are many possible scenarios, manually tackling all possible cases will likely yield a too simplistic policy. Moreover, one must balance between unexpected behavior of other drivers/pedestrians and at the same time not to be too defensive so that normal traffic flow is maintained. In this paper we apply deep reinforcement learning to the problem of forming long term driving strategies. We note that there are two major challenges that make autonomous driving different from other robotic tasks. First, is the necessity for ensuring functional safety - something that machine learning has difficulty with given that performance is optimized at the level of an expectation over many instances. Second, the Markov Decision Process model often used in robotics is problematic in our case because of unpredictable behavior of other agents in this multi-agent scenario. We make three contributions in our work. First, we show how policy gradient iterations can be used without Markovian assumptions. Second, we decompose the problem into a composition of a Policy for Desires (which is to be learned) and trajectory planning with hard constraints (which is not learned). The goal of Desires is to enable comfort of driving, while hard constraints guarantees the safety of driving. Third, we introduce a hierarchical temporal abstraction we call an "Option Graph" with a gating mechanism that significantly reduces the effective horizon and thereby reducing the variance of the gradient estimation even further.
Subspace Learning with Partial Information
May 26, 2016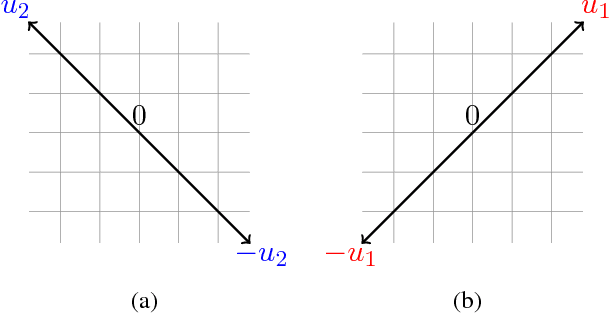
The goal of subspace learning is to find a $k$-dimensional subspace of $\mathbb{R}^d$, such that the expected squared distance between instance vectors and the subspace is as small as possible. In this paper we study subspace learning in a partial information setting, in which the learner can only observe $r \le d$ attributes from each instance vector. We propose several efficient algorithms for this task, and analyze their sample complexity
Solving Ridge Regression using Sketched Preconditioned SVRG
May 26, 2016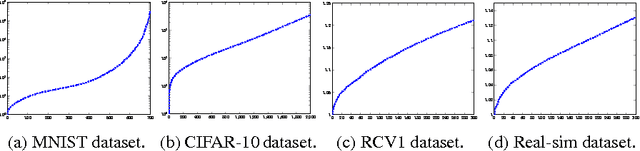
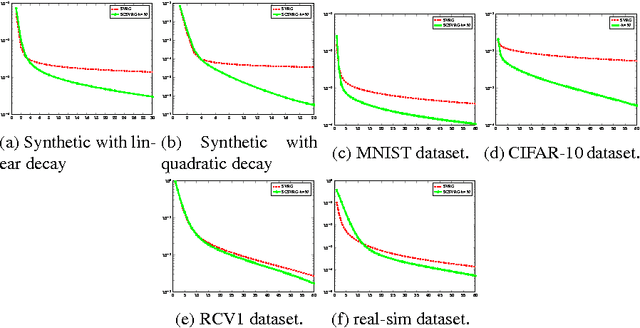
We develop a novel preconditioning method for ridge regression, based on recent linear sketching methods. By equipping Stochastic Variance Reduced Gradient (SVRG) with this preconditioning process, we obtain a significant speed-up relative to fast stochastic methods such as SVRG, SDCA and SAG.
Learning a Metric Embedding for Face Recognition using the Multibatch Method
May 24, 2016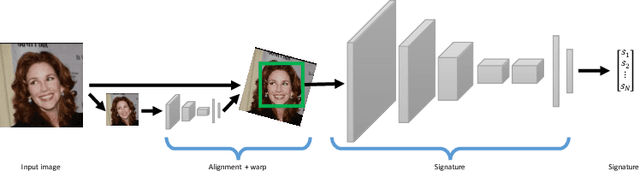

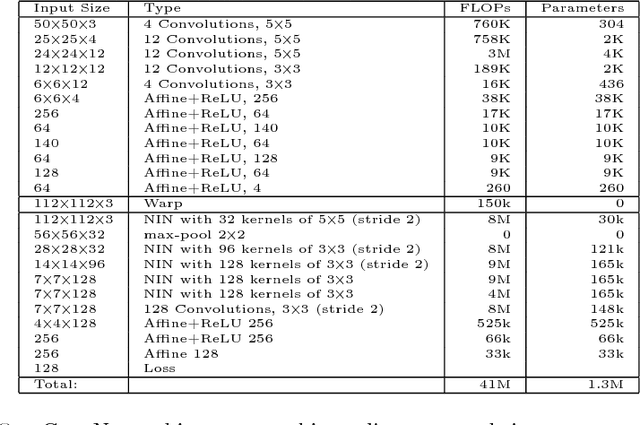

This work is motivated by the engineering task of achieving a near state-of-the-art face recognition on a minimal computing budget running on an embedded system. Our main technical contribution centers around a novel training method, called Multibatch, for similarity learning, i.e., for the task of generating an invariant "face signature" through training pairs of "same" and "not-same" face images. The Multibatch method first generates signatures for a mini-batch of $k$ face images and then constructs an unbiased estimate of the full gradient by relying on all $k^2-k$ pairs from the mini-batch. We prove that the variance of the Multibatch estimator is bounded by $O(1/k^2)$, under some mild conditions. In contrast, the standard gradient estimator that relies on random $k/2$ pairs has a variance of order $1/k$. The smaller variance of the Multibatch estimator significantly speeds up the convergence rate of stochastic gradient descent. Using the Multibatch method we train a deep convolutional neural network that achieves an accuracy of $98.2\%$ on the LFW benchmark, while its prediction runtime takes only $30$msec on a single ARM Cortex A9 core. Furthermore, the entire training process took only 12 hours on a single Titan X GPU.
Minimizing the Maximal Loss: How and Why?
May 22, 2016
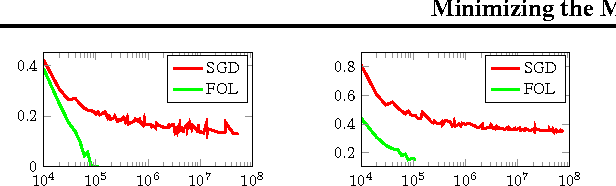
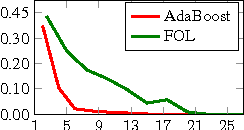
A commonly used learning rule is to approximately minimize the \emph{average} loss over the training set. Other learning algorithms, such as AdaBoost and hard-SVM, aim at minimizing the \emph{maximal} loss over the training set. The average loss is more popular, particularly in deep learning, due to three main reasons. First, it can be conveniently minimized using online algorithms, that process few examples at each iteration. Second, it is often argued that there is no sense to minimize the loss on the training set too much, as it will not be reflected in the generalization loss. Last, the maximal loss is not robust to outliers. In this paper we describe and analyze an algorithm that can convert any online algorithm to a minimizer of the maximal loss. We prove that in some situations better accuracy on the training set is crucial to obtain good performance on unseen examples. Last, we propose robust versions of the approach that can handle outliers.
SDCA without Duality, Regularization, and Individual Convexity
May 21, 2016Stochastic Dual Coordinate Ascent is a popular method for solving regularized loss minimization for the case of convex losses. We describe variants of SDCA that do not require explicit regularization and do not rely on duality. We prove linear convergence rates even if individual loss functions are non-convex, as long as the expected loss is strongly convex.
On the Sample Complexity of End-to-end Training vs. Semantic Abstraction Training
Apr 23, 2016
We compare the end-to-end training approach to a modular approach in which a system is decomposed into semantically meaningful components. We focus on the sample complexity aspect, in the regime where an extremely high accuracy is necessary, as is the case in autonomous driving applications. We demonstrate cases in which the number of training examples required by the end-to-end approach is exponentially larger than the number of examples required by the semantic abstraction approach.
Learning Sparse Low-Threshold Linear Classifiers
Apr 18, 2016We consider the problem of learning a non-negative linear classifier with a $1$-norm of at most $k$, and a fixed threshold, under the hinge-loss. This problem generalizes the problem of learning a $k$-monotone disjunction. We prove that we can learn efficiently in this setting, at a rate which is linear in both $k$ and the size of the threshold, and that this is the best possible rate. We provide an efficient online learning algorithm that achieves the optimal rate, and show that in the batch case, empirical risk minimization achieves this rate as well. The rates we show are tighter than the uniform convergence rate, which grows with $k^2$.
Distribution Free Learning with Local Queries
Mar 11, 2016The model of learning with \emph{local membership queries} interpolates between the PAC model and the membership queries model by allowing the learner to query the label of any example that is similar to an example in the training set. This model, recently proposed and studied by Awasthi, Feldman and Kanade, aims to facilitate practical use of membership queries. We continue this line of work, proving both positive and negative results in the {\em distribution free} setting. We restrict to the boolean cube $\{-1, 1\}^n$, and say that a query is $q$-local if it is of a hamming distance $\le q$ from some training example. On the positive side, we show that $1$-local queries already give an additional strength, and allow to learn a certain type of DNF formulas. On the negative side, we show that even $\left(n^{0.99}\right)$-local queries cannot help to learn various classes including Automata, DNFs and more. Likewise, $q$-local queries for any constant $q$ cannot help to learn Juntas, Decision Trees, Sparse Polynomials and more. Moreover, for these classes, an algorithm that uses $\left(\log^{0.99}(n)\right)$-local queries would lead to a breakthrough in the best known running times.
Long-term Planning by Short-term Prediction
Feb 04, 2016
We consider planning problems, that often arise in autonomous driving applications, in which an agent should decide on immediate actions so as to optimize a long term objective. For example, when a car tries to merge in a roundabout it should decide on an immediate acceleration/braking command, while the long term effect of the command is the success/failure of the merge. Such problems are characterized by continuous state and action spaces, and by interaction with multiple agents, whose behavior can be adversarial. We argue that dual versions of the MDP framework (that depend on the value function and the $Q$ function) are problematic for autonomous driving applications due to the non Markovian of the natural state space representation, and due to the continuous state and action spaces. We propose to tackle the planning task by decomposing the problem into two phases: First, we apply supervised learning for predicting the near future based on the present. We require that the predictor will be differentiable with respect to the representation of the present. Second, we model a full trajectory of the agent using a recurrent neural network, where unexplained factors are modeled as (additive) input nodes. This allows us to solve the long-term planning problem using supervised learning techniques and direct optimization over the recurrent neural network. Our approach enables us to learn robust policies by incorporating adversarial elements to the environment.