 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Ethics of Building AI in a Responsible Manner
Mar 30, 2020The AI-alignment problem arises when there is a discrepancy between the goals that a human designer specifies to an AI learner and a potential catastrophic outcome that does not reflect what the human designer really wants. We argue that a formalism of AI alignment that does not distinguish between strategic and agnostic misalignments is not useful, as it deems all technology as un-safe. We propose a definition of a strategic-AI-alignment and prove that most machine learning algorithms that are being used in practice today do not suffer from the strategic-AI-alignment problem. However, without being careful, today's technology might lead to strategic misalignment.
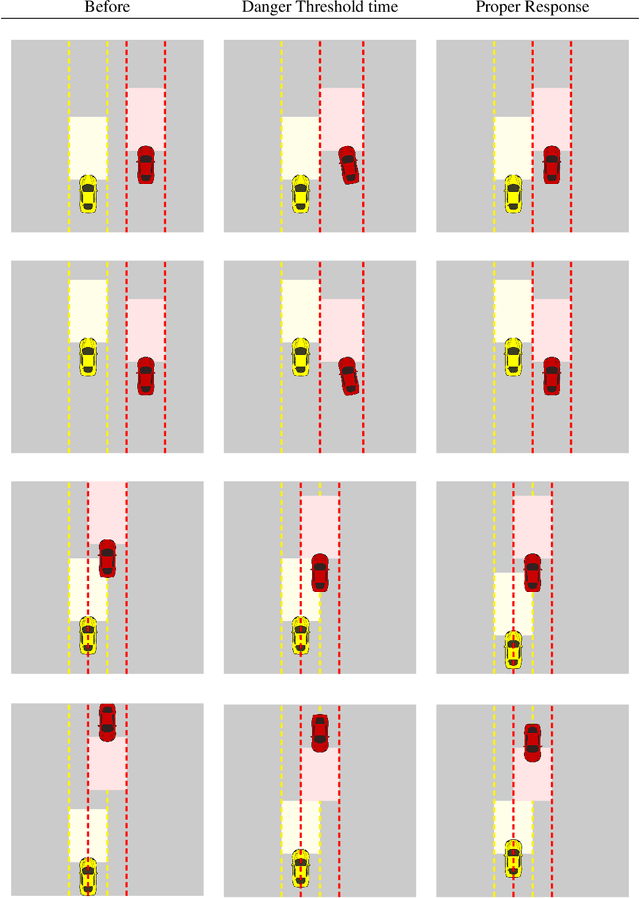
Vision Zero: on a Provable Method for Eliminating Roadway Accidents without Compromising Traffic Throughput
Jan 17, 2019We propose an economical, viable, approach to eliminate almost all car accidents. Our method relies on a mathematical model of safety and can be applied to all modern cars at a mild cost.
On a Formal Model of Safe and Scalable Self-driving Cars
Oct 27, 2018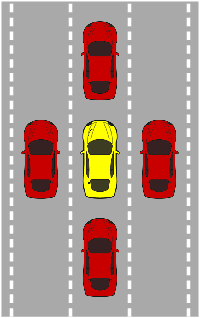
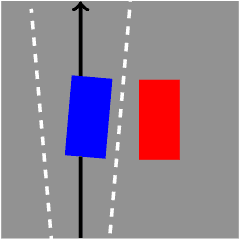

In recent years, car makers and tech companies have been racing towards self driving cars. It seems that the main parameter in this race is who will have the first car on the road. The goal of this paper is to add to the equation two additional crucial parameters. The first is standardization of safety assurance --- what are the minimal requirements that every self-driving car must satisfy, and how can we verify these requirements. The second parameter is scalability --- engineering solutions that lead to unleashed costs will not scale to millions of cars, which will push interest in this field into a niche academic corner, and drive the entire field into a "winter of autonomous driving". In the first part of the paper we propose a white-box, interpretable, mathematical model for safety assurance, which we call Responsibility-Sensitive Safety (RSS). In the second part we describe a design of a system that adheres to our safety assurance requirements and is scalable to millions of cars.
Weight Sharing is Crucial to Succesful Optimization
Jun 02, 2017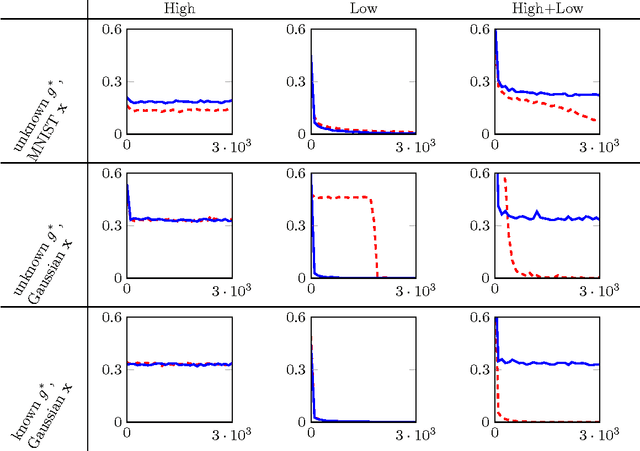
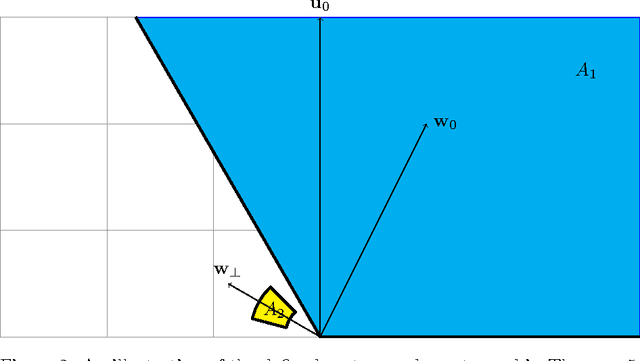
Exploiting the great expressive power of Deep Neural Network architectures, relies on the ability to train them. While current theoretical work provides, mostly, results showing the hardness of this task, empirical evidence usually differs from this line, with success stories in abundance. A strong position among empirically successful architectures is captured by networks where extensive weight sharing is used, either by Convolutional or Recurrent layers. Additionally, characterizing specific aspects of different tasks, making them "harder" or "easier", is an interesting direction explored both theoretically and empirically. We consider a family of ConvNet architectures, and prove that weight sharing can be crucial, from an optimization point of view. We explore different notions of the frequency, of the target function, proving necessity of the target function having some low frequency components. This necessity is not sufficient - only with weight sharing can it be exploited, thus theoretically separating architectures using it, from others which do not. Our theoretical results are aligned with empirical experiments in an even more general setting, suggesting viability of examination of the role played by interleaving those aspects in broader families of tasks.
Failures of Gradient-Based Deep Learning
Apr 26, 2017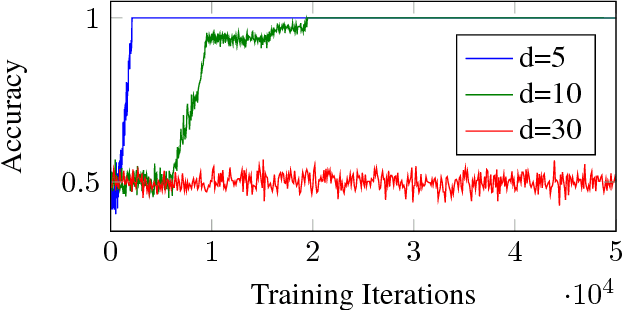

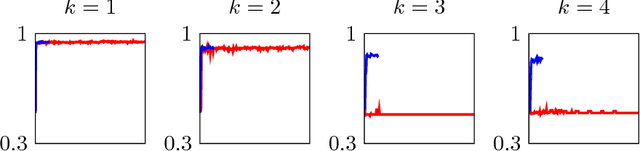
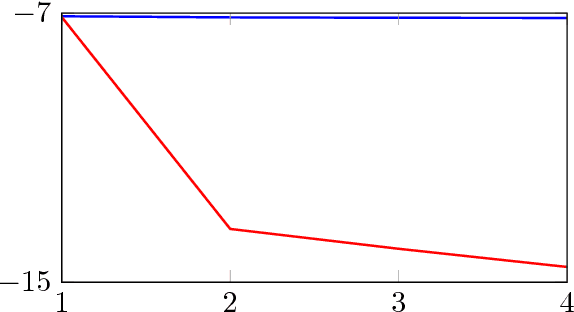
In recent years, Deep Learning has become the go-to solution for a broad range of applications, often outperforming state-of-the-art. However, it is important, for both theoreticians and practitioners, to gain a deeper understanding of the difficulties and limitations associated with common approaches and algorithms. We describe four types of simple problems, for which the gradient-based algorithms commonly used in deep learning either fail or suffer from significant difficulties. We illustrate the failures through practical experiments, and provide theoretical insights explaining their source, and how they might be remedied.
Safe, Multi-Agent, Reinforcement Learning for Autonomous Driving
Oct 11, 2016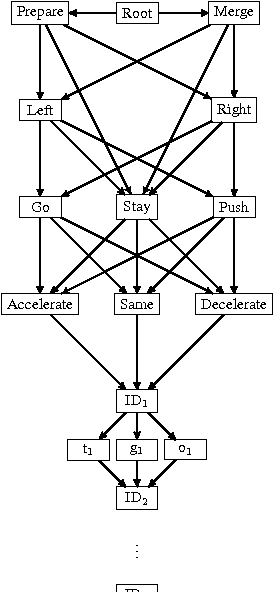
Autonomous driving is a multi-agent setting where the host vehicle must apply sophisticated negotiation skills with other road users when overtaking, giving way, merging, taking left and right turns and while pushing ahead in unstructured urban roadways. Since there are many possible scenarios, manually tackling all possible cases will likely yield a too simplistic policy. Moreover, one must balance between unexpected behavior of other drivers/pedestrians and at the same time not to be too defensive so that normal traffic flow is maintained. In this paper we apply deep reinforcement learning to the problem of forming long term driving strategies. We note that there are two major challenges that make autonomous driving different from other robotic tasks. First, is the necessity for ensuring functional safety - something that machine learning has difficulty with given that performance is optimized at the level of an expectation over many instances. Second, the Markov Decision Process model often used in robotics is problematic in our case because of unpredictable behavior of other agents in this multi-agent scenario. We make three contributions in our work. First, we show how policy gradient iterations can be used without Markovian assumptions. Second, we decompose the problem into a composition of a Policy for Desires (which is to be learned) and trajectory planning with hard constraints (which is not learned). The goal of Desires is to enable comfort of driving, while hard constraints guarantees the safety of driving. Third, we introduce a hierarchical temporal abstraction we call an "Option Graph" with a gating mechanism that significantly reduces the effective horizon and thereby reducing the variance of the gradient estimation even further.