 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Zero: on a Provable Method for Eliminating Roadway Accidents without Compromising Traffic Throughput
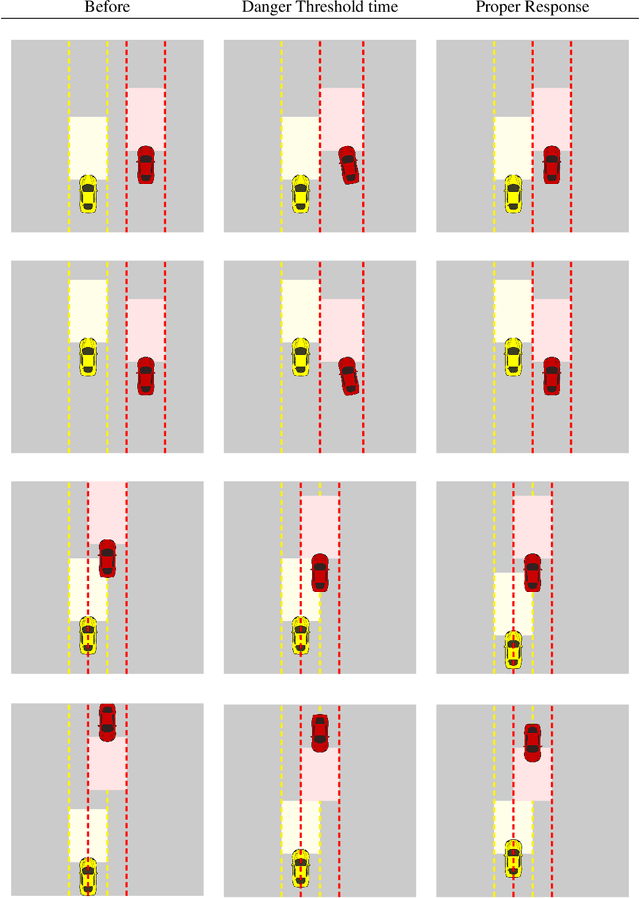
Jan 17, 2019We propose an economical, viable, approach to eliminate almost all car accidents. Our method relies on a mathematical model of safety and can be applied to all modern cars at a mild cost.
On a Formal Model of Safe and Scalable Self-driving Cars
Oct 27, 2018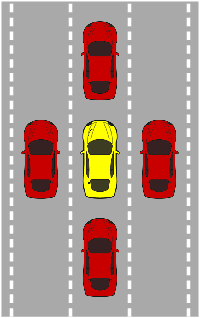
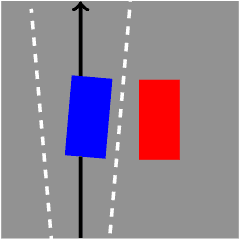

In recent years, car makers and tech companies have been racing towards self driving cars. It seems that the main parameter in this race is who will have the first car on the road. The goal of this paper is to add to the equation two additional crucial parameters. The first is standardization of safety assurance --- what are the minimal requirements that every self-driving car must satisfy, and how can we verify these requirements. The second parameter is scalability --- engineering solutions that lead to unleashed costs will not scale to millions of cars, which will push interest in this field into a niche academic corner, and drive the entire field into a "winter of autonomous driving". In the first part of the paper we propose a white-box, interpretable, mathematical model for safety assurance, which we call Responsibility-Sensitive Safety (RSS). In the second part we describe a design of a system that adheres to our safety assurance requirements and is scalable to millions of cars.
A Provably Correct Algorithm for Deep Learning that Actually Works
Jun 24, 2018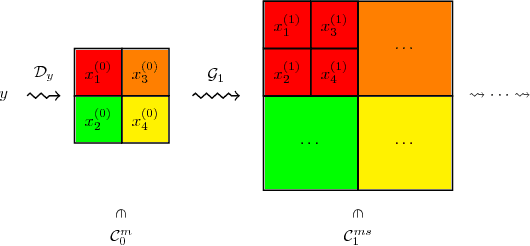
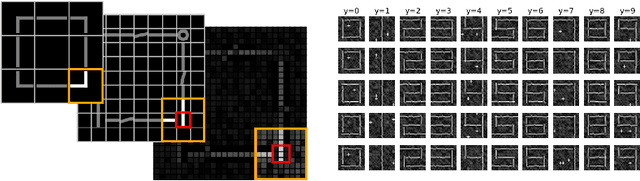

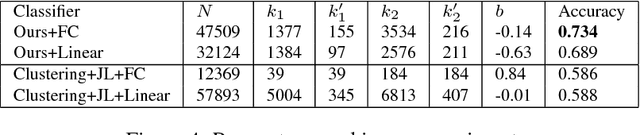
We describe a layer-by-layer algorithm for training deep convolutional networks, where each step involves gradient updates for a two layer network followed by a simple clustering algorithm. Our algorithm stems from a deep generative model that generates mages level by level, where lower resolution images correspond to latent semantic classes. We analyze the convergence rate of our algorithm assuming that the data is indeed generated according to this model (as well as additional assumptions). While we do not pretend to claim that the assumptions are realistic for natural images, we do believe that they capture some true properties of real data. Furthermore, we show that our algorithm actually works in practice (on the CIFAR dataset), achieving results in the same ballpark as that of vanilla convolutional neural networks that are being trained by stochastic gradient descent. Finally, our proof techniques may be of independent interest.
Decoupling "when to update" from "how to update"
Mar 26, 2018
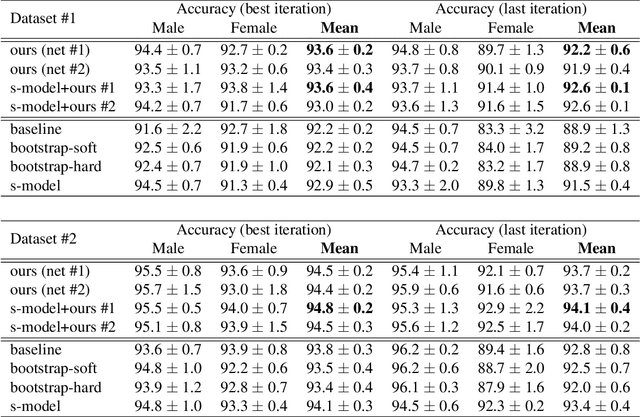
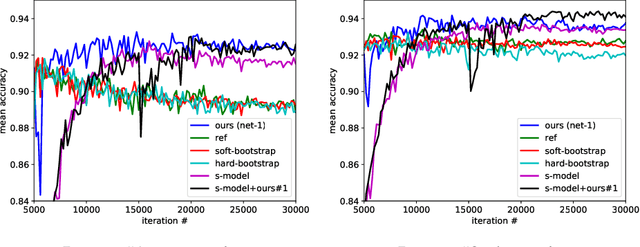
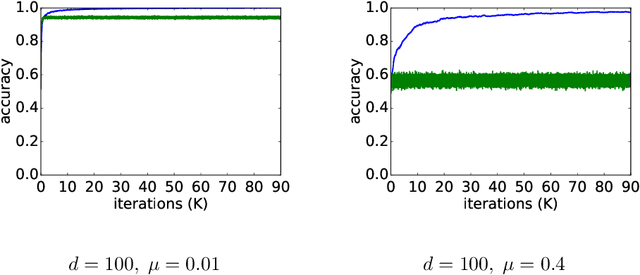
Deep learning requires data. A useful approach to obtain data is to be creative and mine data from various sources, that were created for different purposes. Unfortunately, this approach often leads to noisy labels. In this paper, we propose a meta algorithm for tackling the noisy labels problem. The key idea is to decouple "when to update" from "how to update". We demonstrate the effectiveness of our algorithm by mining data for gender classification by combining the Labeled Faces in the Wild (LFW) face recognition dataset with a textual genderizing service, which leads to a noisy dataset. While our approach is very simple to implement, it leads to state-of-the-art results. We analyze some convergence properties of the proposed algorithm.
SGD Learns Over-parameterized Networks that Provably Generalize on Linearly Separable Data
Oct 27, 2017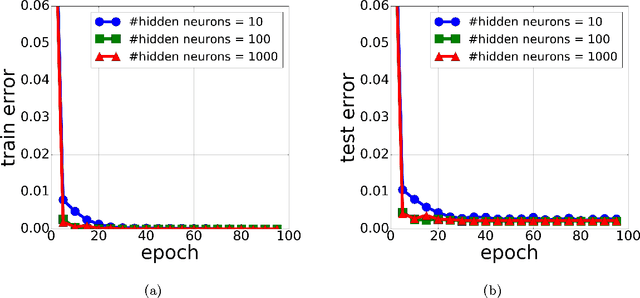
Neural networks exhibit good generalization behavior in the over-parameterized regime, where the number of network parameters exceeds the number of observations. Nonetheless, current generalization bounds for neural networks fail to explain this phenomenon. In an attempt to bridge this gap, we study the problem of learning a two-layer over-parameterized neural network, when the data is generated by a linearly separable function. In the case where the network has Leaky ReLU activations, we provide both optimization and generalization guarantees for over-parameterized networks. Specifically, we prove convergence rates of SGD to a global minimum and provide generalization guarantees for this global minimum that are independent of the network size. Therefore, our result clearly shows that the use of SGD for optimization both finds a global minimum, and avoids overfitting despite the high capacity of the model. This is the first theoretical demonstration that SGD can avoid overfitting, when learning over-specified neural network classifiers.
Fast Rates for Empirical Risk Minimization of Strict Saddle Problems
Jun 04, 2017We derive bounds on the sample complexity of empirical risk minimization (ERM) in the context of minimizing non-convex risks that admit the strict saddle property. Recent progress in non-convex optimization has yielded efficient algorithms for minimizing such functions. Our results imply that these efficient algorithms are statistically stable and also generalize well. In particular, we derive fast rates which resemble the bounds that are often attained in the strongly convex setting. We specify our bounds to Principal Component Analysis and Independent Component Analysis. Our results and techniques may pave the way for statistical analyses of additional strict saddle problems.
Weight Sharing is Crucial to Succesful Optimization
Jun 02, 2017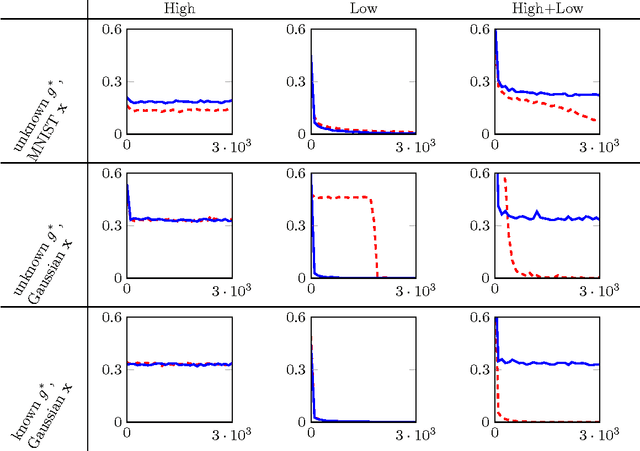
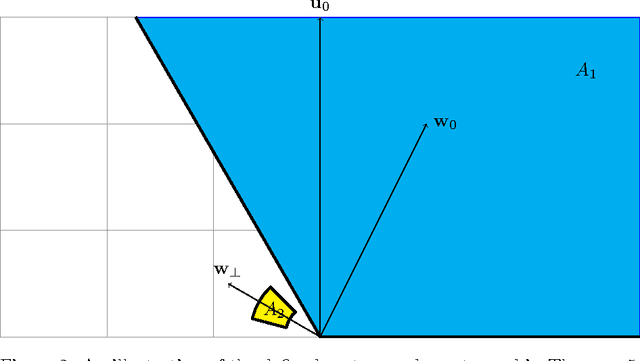
Exploiting the great expressive power of Deep Neural Network architectures, relies on the ability to train them. While current theoretical work provides, mostly, results showing the hardness of this task, empirical evidence usually differs from this line, with success stories in abundance. A strong position among empirically successful architectures is captured by networks where extensive weight sharing is used, either by Convolutional or Recurrent layers. Additionally, characterizing specific aspects of different tasks, making them "harder" or "easier", is an interesting direction explored both theoretically and empirically. We consider a family of ConvNet architectures, and prove that weight sharing can be crucial, from an optimization point of view. We explore different notions of the frequency, of the target function, proving necessity of the target function having some low frequency components. This necessity is not sufficient - only with weight sharing can it be exploited, thus theoretically separating architectures using it, from others which do not. Our theoretical results are aligned with empirical experiments in an even more general setting, suggesting viability of examination of the role played by interleaving those aspects in broader families of tasks.
Failures of Gradient-Based Deep Learning
Apr 26, 2017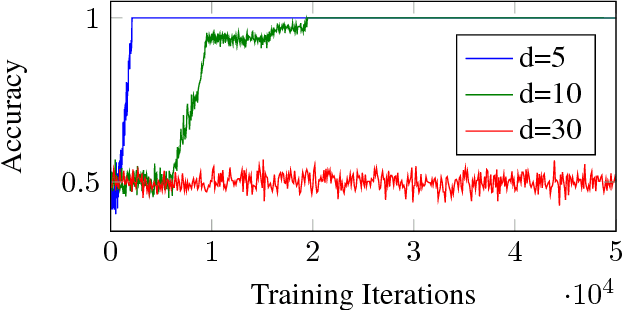

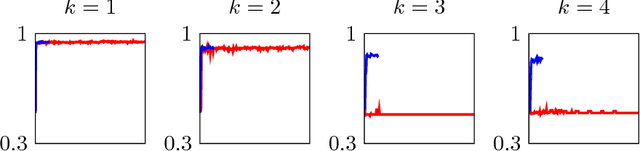
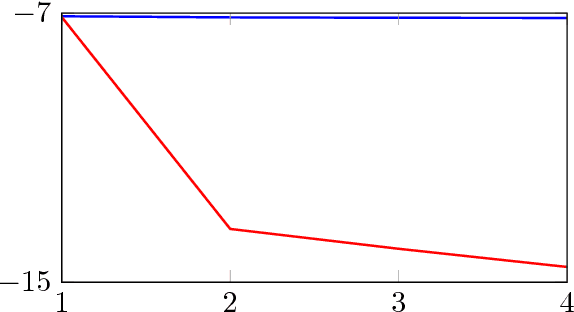
In recent years, Deep Learning has become the go-to solution for a broad range of applications, often outperforming state-of-the-art. However, it is important, for both theoreticians and practitioners, to gain a deeper understanding of the difficulties and limitations associated with common approaches and algorithms. We describe four types of simple problems, for which the gradient-based algorithms commonly used in deep learning either fail or suffer from significant difficulties. We illustrate the failures through practical experiments, and provide theoretical insights explaining their source, and how they might be remedied.
Average Stability is Invariant to Data Preconditioning. Implications to Exp-concave Empirical Risk Minimization
Apr 16, 2017We show that the average stability notion introduced by \cite{kearns1999algorithmic, bousquet2002stability} is invariant to data preconditioning, for a wide class of generalized linear models that includes most of the known exp-concave losses. In other words, when analyzing the stability rate of a given algorithm, we may assume the optimal preconditioning of the data. This implies that, at least from a statistical perspective, explicit regularization is not required in order to compensate for ill-conditioned data, which stands in contrast to a widely common approach that includes a regularization for analyzing the sample complexity of generalized linear models. Several important implications of our findings include: a) We demonstrate that the excess risk of empirical risk minimization (ERM) is controlled by the preconditioned stability rate. This immediately yields a relatively short and elegant proof for the fast rates attained by ERM in our context. b) We strengthen the recent bounds of \cite{hardt2015train} on the stability rate of the Stochastic Gradient Descent algorithm.
SelfieBoost: A Boosting Algorithm for Deep Learning
Apr 08, 2017We describe and analyze a new boosting algorithm for deep learning called SelfieBoost. Unlike other boosting algorithms, like AdaBoost, which construct ensembles of classifiers, SelfieBoost boosts the accuracy of a single network. We prove a $\log(1/\epsilon)$ convergence rate for SelfieBoost under some "SGD success" assumption which seems to hold in practice.