 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplicing ViT Features for Semantic Appearance Transfer
Jan 02, 2022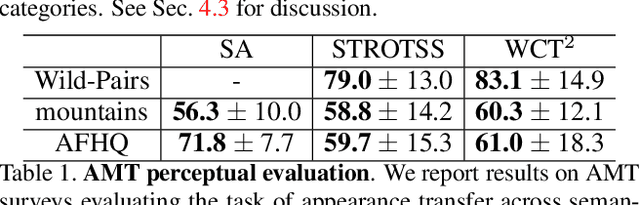
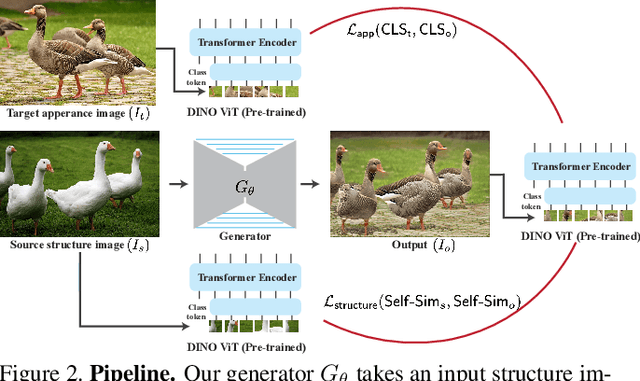


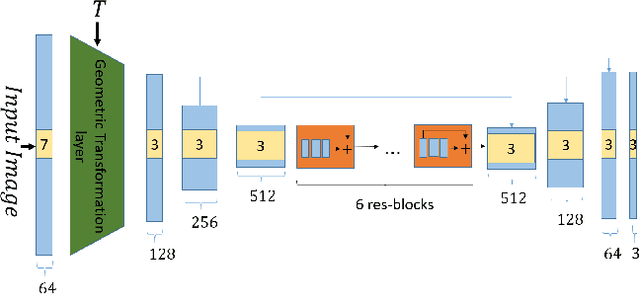
We present a method for semantically transferring the visual appearance of one natural image to another. Specifically, our goal is to generate an image in which objects in a source structure image are "painted" with the visual appearance of their semantically related objects in a target appearance image. Our method works by training a generator given only a single structure/appearance image pair as input. To integrate semantic information into our framework - a pivotal component in tackling this task - our key idea is to leverage a pre-trained and fixed Vision Transformer (ViT) model which serves as an external semantic prior. Specifically, we derive novel representations of structure and appearance extracted from deep ViT features, untwisting them from the learned self-attention modules. We then establish an objective function that splices the desired structure and appearance representations, interweaving them together in the space of ViT features. Our framework, which we term "Splice", does not involve adversarial training, nor does it require any additional input information such as semantic segmentation or correspondences, and can generate high-resolution results, e.g., work in HD. We demonstrate high quality results on a variety of in-the-wild image pairs, under significant variations in the number of objects, their pose and appearance.
Deep ViT Features as Dense Visual Descriptors
Dec 10, 2021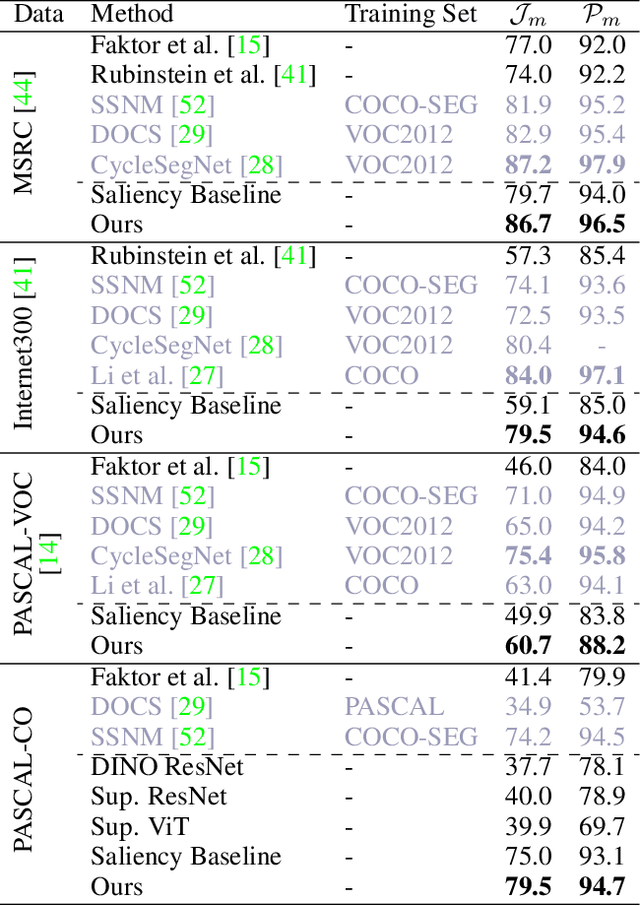
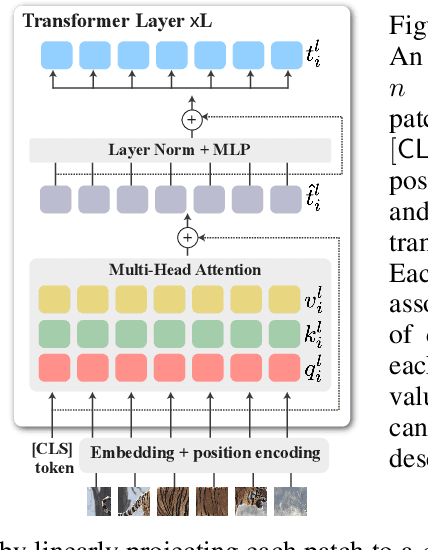
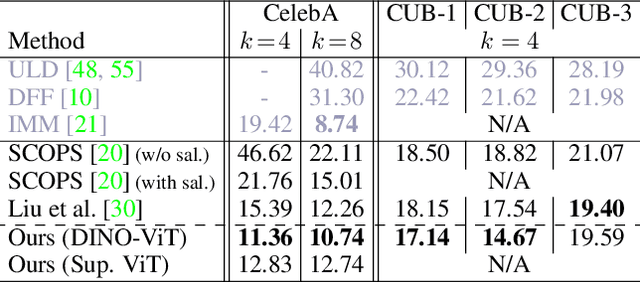
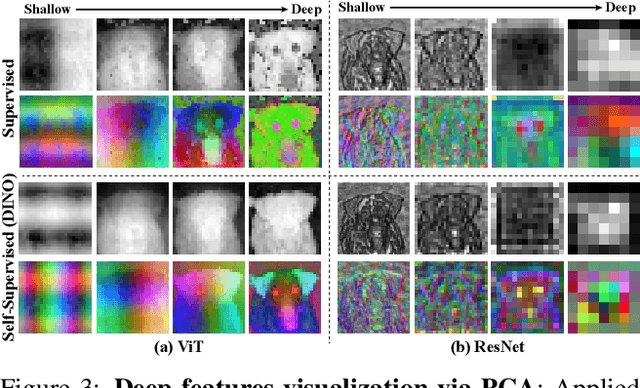
We leverage deep features extracted from a pre-trained Vision Transformer (ViT) as dense visual descriptors. We demonstrate that such features, when extracted from a self-supervised ViT model (DINO-ViT), exhibit several striking properties: (i) the features encode powerful high level information at high spatial resolution -- i.e., capture semantic object parts at fine spatial granularity, and (ii) the encoded semantic information is shared across related, yet different object categories (i.e. super-categories). These properties allow us to design powerful dense ViT descriptors that facilitate a variety of applications, including co-segmentation, part co-segmentation and correspondences -- all achieved by applying lightweight methodologies to deep ViT features (e.g., binning / clustering). We take these applications further to the realm of inter-class tasks -- demonstrating how objects from related categories can be commonly segmented into semantic parts, under significant pose and appearance changes. Our methods, extensively evaluated qualitatively and quantitatively, achieve state-of-the-art part co-segmentation results, and competitive results with recent supervised methods trained specifically for co-segmentation and correspondences.
Diverse Generation from a Single Video Made Possible
Sep 17, 2021

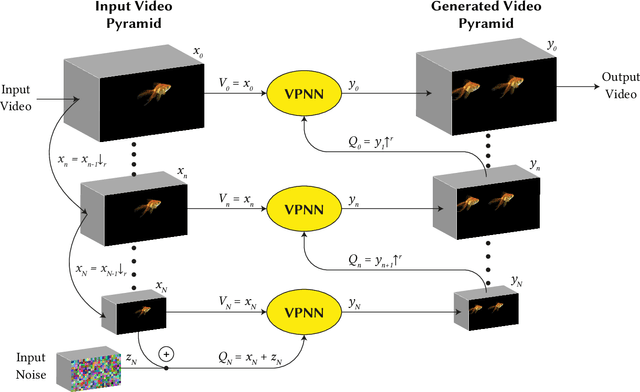
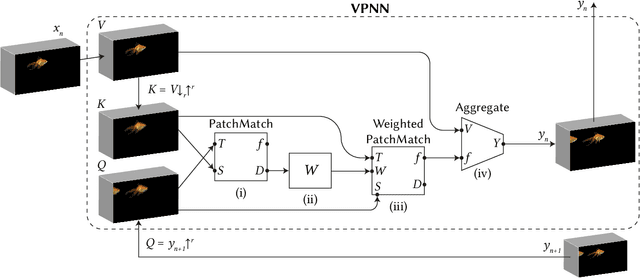
Most advanced video generation and manipulation methods train on a large collection of videos. As such, they are restricted to the types of video dynamics they train on. To overcome this limitation, GANs trained on a single video were recently proposed. While these provide more flexibility to a wide variety of video dynamics, they require days to train on a single tiny input video, rendering them impractical. In this paper we present a fast and practical method for video generation and manipulation from a single natural video, which generates diverse high-quality video outputs within seconds (for benchmark videos). Our method can be further applied to Full-HD video clips within minutes. Our approach is inspired by a recent advanced patch-nearest-neighbor based approach [Granot et al. 2021], which was shown to significantly outperform single-image GANs, both in run-time and in visual quality. Here we generalize this approach from images to videos, by casting classical space-time patch-based methods as a new generative video model. We adapt the generative image patch nearest neighbor approach to efficiently cope with the huge number of space-time patches in a single video. Our method generates more realistic and higher quality results than single-video GANs (confirmed by quantitative and qualitative evaluations). Moreover, it is disproportionally faster (runtime reduced from several days to seconds). Other than diverse video generation, we demonstrate several other challenging video applications, including spatio-temporal video retargeting, video structural analogies and conditional video-inpainting.
Drop the GAN: In Defense of Patches Nearest Neighbors as Single Image Generative Models
Mar 29, 2021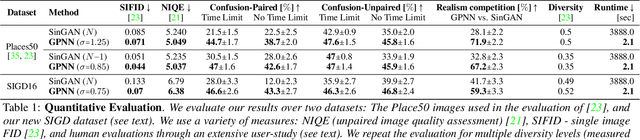
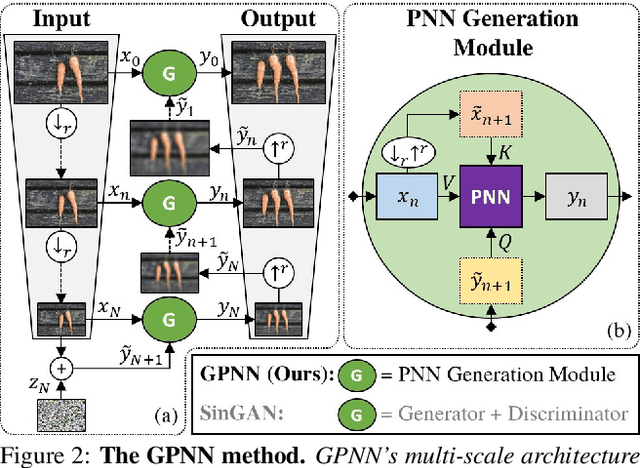
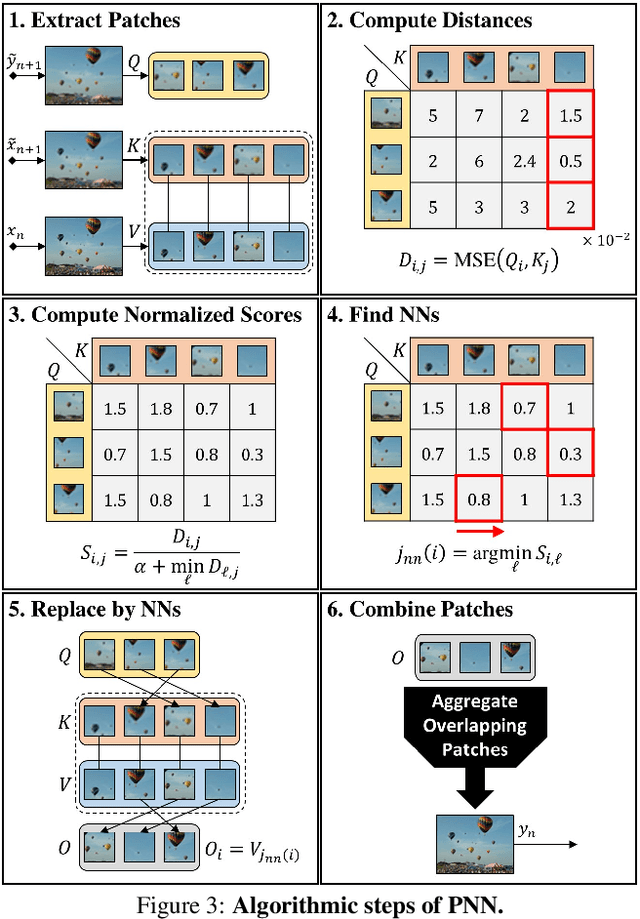

Single image generative models perform synthesis and manipulation tasks by capturing the distribution of patches within a single image. The classical (pre Deep Learning) prevailing approaches for these tasks are based on an optimization process that maximizes patch similarity between the input and generated output. Recently, however, Single Image GANs were introduced both as a superior solution for such manipulation tasks, but also for remarkable novel generative tasks. Despite their impressiveness, single image GANs require long training time (usually hours) for each image and each task. They often suffer from artifacts and are prone to optimization issues such as mode collapse. In this paper, we show that all of these tasks can be performed without any training, within several seconds, in a unified, surprisingly simple framework. We revisit and cast the "good-old" patch-based methods into a novel optimization-free framework. We start with an initial coarse guess, and then simply refine the details coarse-to-fine using patch-nearest-neighbor search. This allows generating random novel images better and much faster than GANs. We further demonstrate a wide range of applications, such as image editing and reshuffling, retargeting to different sizes, structural analogies, image collage and a newly introduced task of conditional inpainting. Not only is our method faster ($\times 10^3$-$\times 10^4$ than a GAN), it produces superior results (confirmed by quantitative and qualitative evaluation), less artifacts and more realistic global structure than any of the previous approaches (whether GAN-based or classical patch-based).
Segmenting Microcalcifications in Mammograms and its Applications
Feb 01, 2021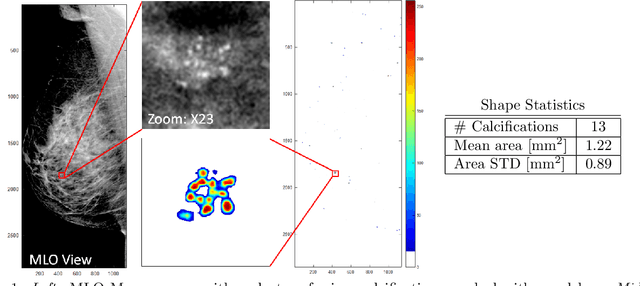
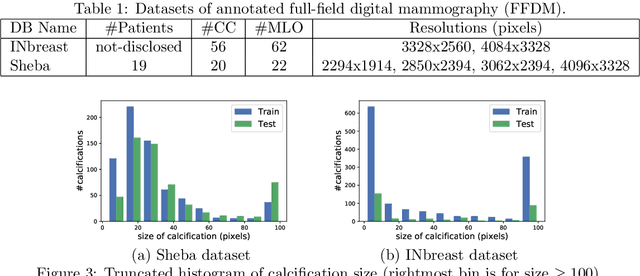
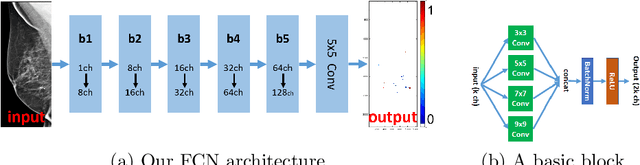

Microcalcifications are small deposits of calcium that appear in mammograms as bright white specks on the soft tissue background of the breast. Microcalcifications may be a unique indication for Ductal Carcinoma in Situ breast cancer, and therefore their accurate detection is crucial for diagnosis and screening. Manual detection of these tiny calcium residues in mammograms is both time-consuming and error-prone, even for expert radiologists, since these microcalcifications are small and can be easily missed. Existing computerized algorithms for detecting and segmenting microcalcifications tend to suffer from a high false-positive rate, hindering their widespread use. In this paper, we propose an accurate calcification segmentation method using deep learning. We specifically address the challenge of keeping the false positive rate low by suggesting a strategy for focusing the hard pixels in the training phase. Furthermore, our accurate segmentation enables extracting meaningful statistics on clusters of microcalcifications.
Point of Care Image Analysis for COVID-19
Nov 10, 2020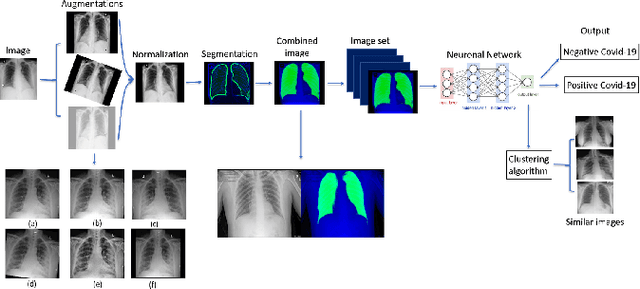
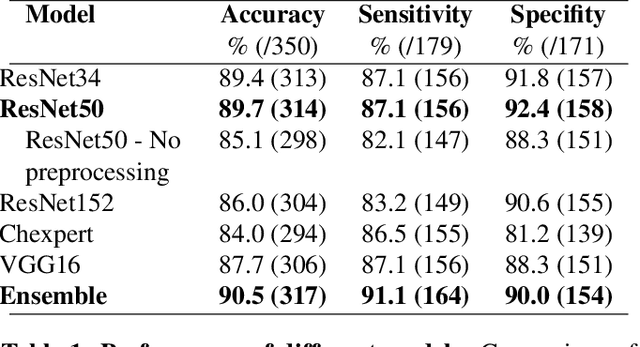
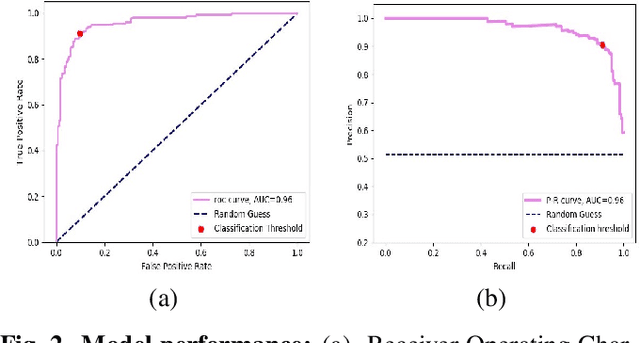
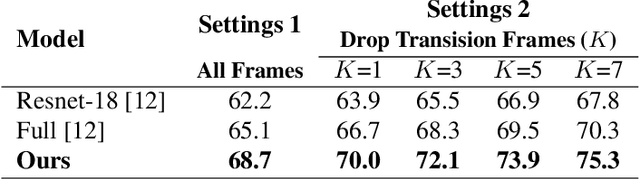
Early detection of COVID-19 is key in containing the pandemic. Disease detection and evaluation based on imaging is fast and cheap and therefore plays an important role in COVID-19 handling. COVID-19 is easier to detect in chest CT, however, it is expensive, non-portable, and difficult to disinfect, making it unfit as a point-of-care (POC) modality. On the other hand, chest X-ray (CXR) and lung ultrasound (LUS) are widely used, yet, COVID-19 findings in these modalities are not always very clear. Here we train deep neural networks to significantly enhance the capability to detect, grade and monitor COVID-19 patients using CXRs and LUS. Collaborating with several hospitals in Israel we collect a large dataset of CXRs and use this dataset to train a neural network obtaining above 90% detection rate for COVID-19. In addition, in collaboration with ULTRa (Ultrasound Laboratory Trento, Italy) and hospitals in Italy we obtained POC ultrasound data with annotations of the severity of disease and trained a deep network for automatic severity grading.
Across Scales \& Across Dimensions: Temporal Super-Resolution using Deep Internal Learning
Mar 19, 2020When a very fast dynamic event is recorded with a low-framerate camera, the resulting video suffers from severe motion blur (due to exposure time) and motion aliasing (due to low sampling rate in time). True Temporal Super-Resolution (TSR) is more than just Temporal-Interpolation (increasing framerate). It can also recover new high temporal frequencies beyond the temporal Nyquist limit of the input video, thus resolving both motion-blur and motion-aliasing effects that temporal frame interpolation (as sophisticated as it maybe) cannot undo. In this paper we propose a "Deep Internal Learning" approach for true TSR. We train a video-specific CNN on examples extracted directly from the low-framerate input video. Our method exploits the strong recurrence of small space-time patches inside a single video sequence, both within and across different spatio-temporal scales of the video. We further observe (for the first time) that small space-time patches recur also across-dimensions of the video sequence - i.e., by swapping the spatial and temporal dimensions. In particular, the higher spatial resolution of video frames provides strong examples as to how to increase the temporal resolution of that video. Such internal video-specific examples give rise to strong self-supervision, requiring no data but the input video itself. This results in Zero-Shot Temporal-SR of complex videos, which removes both motion blur and motion aliasing, outperforming previous supervised methods trained on external video datasets.
Internal Distribution Matching for Natural Image Retargeting
Dec 01, 2018
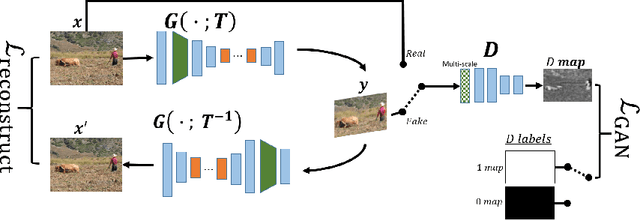
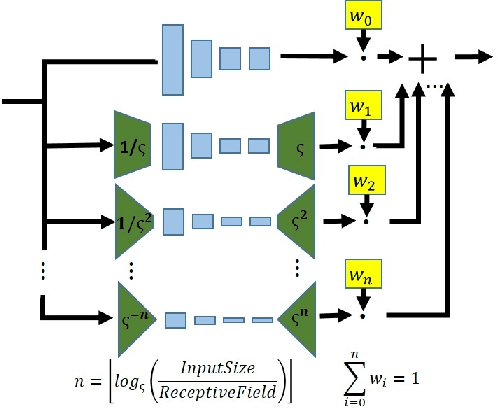
Good Visual Retargeting changes the global size and aspect ratio of a natural image, while preserving the size and aspect ratio of all its local elements. We propose formulating this principle by requiring that the distribution of patches in the input matches the distribution of patches in the output. We introduce a Deep-Learning approach for retargeting, based on an "Internal GAN" (InGAN). InGAN is an image-specific GAN. It incorporates the Internal statistics of a single natural image in a GAN. It is trained on a single input image and learns the distribution of its patches. It is then able to synthesize natural looking target images composed from the input image patch-distribution. InGAN is totally unsupervised, and requires no additional data other than the input image itself. Moreover, once trained on the input image, it can generate target images of any specified size or aspect ratio in real-time.
Discrete Energy Minimization, beyond Submodularity: Applications and Approximations
Nov 07, 2012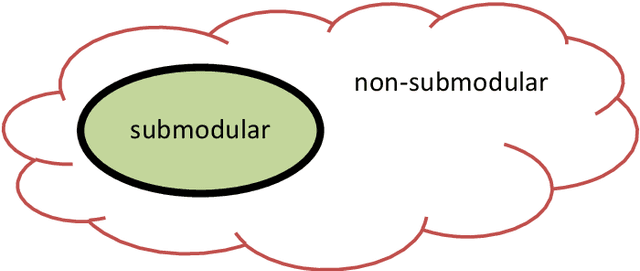

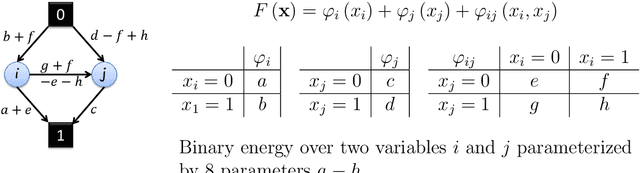
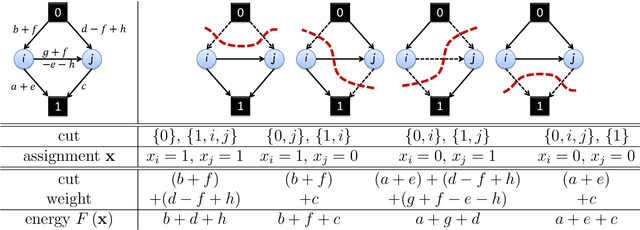
In this thesis I explore challenging discrete energy minimization problems that arise mainly in the context of computer vision tasks. This work motivates the use of such "hard-to-optimize" non-submodular functionals, and proposes methods and algorithms to cope with the NP-hardness of their optimization. Consequently, this thesis revolves around two axes: applications and approximations. The applications axis motivates the use of such "hard-to-optimize" energies by introducing new tasks. As the energies become less constrained and structured one gains more expressive power for the objective function achieving more accurate models. Results show how challenging, hard-to-optimize, energies are more adequate for certain computer vision applications. To overcome the resulting challenging optimization tasks the second axis of this thesis proposes approximation algorithms to cope with the NP-hardness of the optimization. Experiments show that these new methods yield good results for representative challenging problems.
A Multiscale Framework for Challenging Discrete Optimization
Nov 02, 2012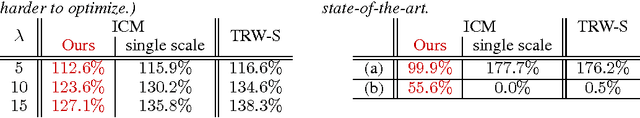
Current state-of-the-art discrete optimization methods struggle behind when it comes to challenging contrast-enhancing discrete energies (i.e., favoring different labels for neighboring variables). This work suggests a multiscale approach for these challenging problems. Deriving an algebraic representation allows us to coarsen any pair-wise energy using any interpolation in a principled algebraic manner. Furthermore, we propose an energy-aware interpolation operator that efficiently exposes the multiscale landscape of the energy yielding an effective coarse-to-fine optimization scheme. Results on challenging contrast-enhancing energies show significant improvement over state-of-the-art methods.