 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimePoint: Accelerated Time Series Alignment via Self-Supervised Keypoint and Descriptor Learning
May 29, 2025Fast and scalable alignment of time series is a fundamental challenge in many domains. The standard solution, Dynamic Time Warping (DTW), struggles with poor scalability and sensitivity to noise. We introduce TimePoint, a self-supervised method that dramatically accelerates DTW-based alignment while typically improving alignment accuracy by learning keypoints and descriptors from synthetic data. Inspired by 2D keypoint detection but carefully adapted to the unique challenges of 1D signals, TimePoint leverages efficient 1D diffeomorphisms, which effectively model nonlinear time warping, to generate realistic training data. This approach, along with fully convolutional and wavelet convolutional architectures, enables the extraction of informative keypoints and descriptors. Applying DTW to these sparse representations yield major speedups and typically higher alignment accuracy than standard DTW applied to the full signals. TimePoint demonstrates strong generalization to real-world time series when trained solely on synthetic data, and further improves with fine-tuning on real data. Extensive experiments demonstrate that TimePoint consistently achieves faster and more accurate alignments than standard DTW, making it a scalable solution for time-series analysis. Our code is available at https://github.com/BGU-CS-VIL/TimePoint
Improving the Effective Receptive Field of Message-Passing Neural Networks
May 29, 2025Message-Passing Neural Networks (MPNNs) have become a cornerstone for processing and analyzing graph-structured data. However, their effectiveness is often hindered by phenomena such as over-squashing, where long-range dependencies or interactions are inadequately captured and expressed in the MPNN output. This limitation mirrors the challenges of the Effective Receptive Field (ERF) in Convolutional Neural Networks (CNNs), where the theoretical receptive field is underutilized in practice. In this work, we show and theoretically explain the limited ERF problem in MPNNs. Furthermore, inspired by recent advances in ERF augmentation for CNNs, we propose an Interleaved Multiscale Message-Passing Neural Networks (IM-MPNN) architecture to address these problems in MPNNs. Our method incorporates a hierarchical coarsening of the graph, enabling message-passing across multiscale representations and facilitating long-range interactions without excessive depth or parameterization. Through extensive evaluations on benchmarks such as the Long-Range Graph Benchmark (LRGB), we demonstrate substantial improvements over baseline MPNNs in capturing long-range dependencies while maintaining computational efficiency.
SpaceJAM: a Lightweight and Regularization-free Method for Fast Joint Alignment of Images
Jul 16, 2024



The unsupervised task of Joint Alignment (JA) of images is beset by challenges such as high complexity, geometric distortions, and convergence to poor local or even global optima. Although Vision Transformers (ViT) have recently provided valuable features for JA, they fall short of fully addressing these issues. Consequently, researchers frequently depend on expensive models and numerous regularization terms, resulting in long training times and challenging hyperparameter tuning. We introduce the Spatial Joint Alignment Model (SpaceJAM), a novel approach that addresses the JA task with efficiency and simplicity. SpaceJAM leverages a compact architecture with only 16K trainable parameters and uniquely operates without the need for regularization or atlas maintenance. Evaluations on SPair-71K and CUB datasets demonstrate that SpaceJAM matches the alignment capabilities of existing methods while significantly reducing computational demands and achieving at least a 10x speedup. SpaceJAM sets a new standard for rapid and effective image alignment, making the process more accessible and efficient. Our code is available at: https://bgu-cs-vil.github.io/SpaceJAM/.
Trainable Highly-expressive Activation Functions
Jul 11, 2024



Nonlinear activation functions are pivotal to the success of deep neural nets, and choosing the appropriate activation function can significantly affect their performance. Most networks use fixed activation functions (e.g., ReLU, GELU, etc.), and this choice might limit their expressiveness. Furthermore, different layers may benefit from diverse activation functions. Consequently, there has been a growing interest in trainable activation functions. In this paper, we introduce DiTAC, a trainable highly-expressive activation function based on an efficient diffeomorphic transformation (called CPAB). Despite introducing only a negligible number of trainable parameters, DiTAC enhances model expressiveness and performance, often yielding substantial improvements. It also outperforms existing activation functions (regardless whether the latter are fixed or trainable) in tasks such as semantic segmentation, image generation, regression problems, and image classification. Our code is available at https://github.com/BGU-CS-VIL/DiTAC.
Wavelet Convolutions for Large Receptive Fields
Jul 08, 2024In recent years, there have been attempts to increase the kernel size of Convolutional Neural Nets (CNNs) to mimic the global receptive field of Vision Transformers' (ViTs) self-attention blocks. That approach, however, quickly hit an upper bound and saturated way before achieving a global receptive field. In this work, we demonstrate that by leveraging the Wavelet Transform (WT), it is, in fact, possible to obtain very large receptive fields without suffering from over-parameterization, e.g., for a $k \times k$ receptive field, the number of trainable parameters in the proposed method grows only logarithmically with $k$. The proposed layer, named WTConv, can be used as a drop-in replacement in existing architectures, results in an effective multi-frequency response, and scales gracefully with the size of the receptive field. We demonstrate the effectiveness of the WTConv layer within ConvNeXt and MobileNetV2 architectures for image classification, as well as backbones for downstream tasks, and show it yields additional properties such as robustness to image corruption and an increased response to shapes over textures. Our code is available at https://github.com/BGU-CS-VIL/WTConv.
Wavelet Feature Maps Compression for Image-to-Image CNNs
May 27, 2022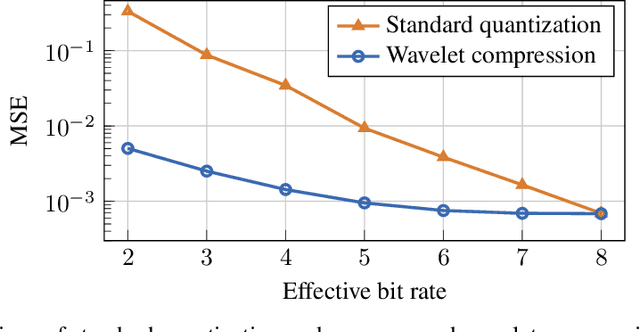
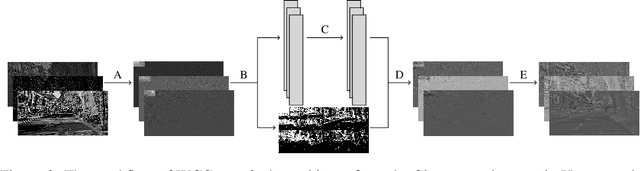
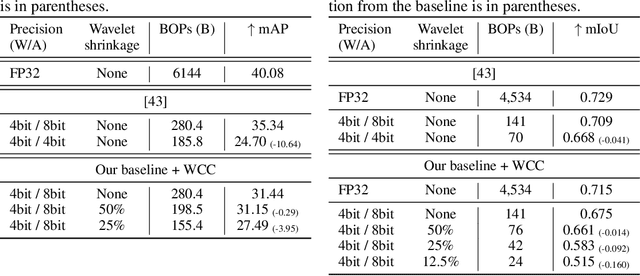

Convolutional Neural Networks (CNNs) are known for requiring extensive computational resources, and quantization is among the best and most common methods for compressing them. While aggressive quantization (i.e., less than 4-bits) performs well for classification, it may cause severe performance degradation in image-to-image tasks such as semantic segmentation and depth estimation. In this paper, we propose Wavelet Compressed Convolution (WCC) -- a novel approach for high-resolution activation maps compression integrated with point-wise convolutions, which are the main computational cost of modern architectures. To this end, we use an efficient and hardware-friendly Haar-wavelet transform, known for its effectiveness in image compression, and define the convolution on the compressed activation map. We experiment on various tasks, that benefit from high-resolution input, and by combining WCC with light quantization, we achieve compression rates equivalent to 1-4bit activation quantization with relatively small and much more graceful degradation in performance.
DeepDPM: Deep Clustering With an Unknown Number of Clusters
Mar 27, 2022Deep Learning (DL) has shown great promise in the unsupervised task of clustering. That said, while in classical (i.e., non-deep) clustering the benefits of the nonparametric approach are well known, most deep-clustering methods are parametric: namely, they require a predefined and fixed number of clusters, denoted by K. When K is unknown, however, using model-selection criteria to choose its optimal value might become computationally expensive, especially in DL as the training process would have to be repeated numerous times. In this work, we bridge this gap by introducing an effective deep-clustering method that does not require knowing the value of K as it infers it during the learning. Using a split/merge framework, a dynamic architecture that adapts to the changing K, and a novel loss, our proposed method outperforms existing nonparametric methods (both classical and deep ones). While the very few existing deep nonparametric methods lack scalability, we demonstrate ours by being the first to report the performance of such a method on ImageNet. We also demonstrate the importance of inferring K by showing how methods that fix it deteriorate in performance when their assumed K value gets further from the ground-truth one, especially on imbalanced datasets. Our code is available at https://github.com/BGU-CS-VIL/DeepDPM.
Effective Learning of a GMRF Mixture Model
May 20, 2020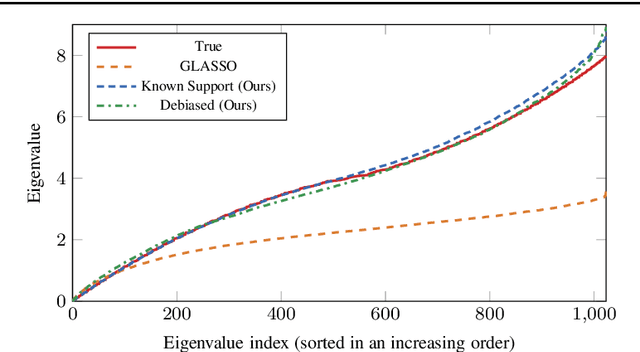

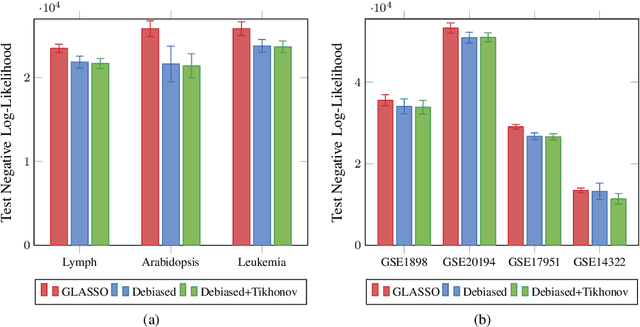
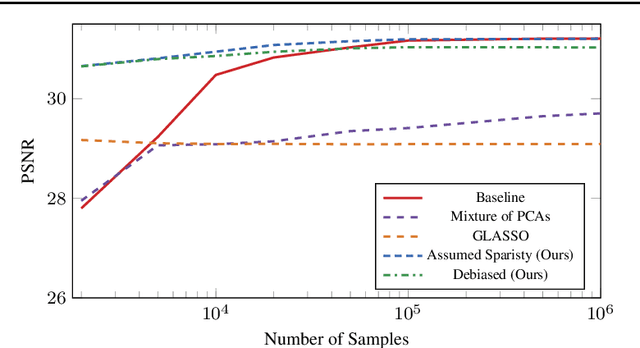
Learning a Gaussian Mixture Model (GMM) is hard when the number of parameters is too large given the amount of available data. As a remedy, we propose restricting the GMM to a Gaussian Markov Random Field Mixture Model (GMRF-MM), as well as a new method for estimating the latter's sparse precision (i.e., inverse covariance) matrices. When the sparsity pattern of each matrix is known, we propose an efficient optimization method for the Maximum Likelihood Estimate (MLE) of that matrix. When it is unknown, we utilize the popular Graphical LASSO (GLASSO) to estimate that pattern. However, we show that even for a single Gaussian, when GLASSO is tuned to successfully estimate the sparsity pattern, it does so at the price of a substantial bias of the values of the nonzero entries of the matrix, and we show that this problem only worsens in a mixture setting. To overcome this, we discard the non-zero values estimated by GLASSO, keep only its pattern estimate and use it within the proposed MLE method. This yields an effective two-step procedure that removes the bias. We show that our "debiasing" approach outperforms GLASSO in both the single-GMRF and the GMRF-MM cases. We also show that when learning priors for image patches, our method outperforms GLASSO even if we merely use an educated guess about the sparsity pattern, and that our GMRF-MM outperforms the baseline GMM on real and synthetic high-dimensional datasets. Our code is available at \url{https://github.com/shahaffind/GMRF-MM}.