 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Zero-Shot Detection of LLM-Generated Code via Approximated Task Conditioning
Jun 06, 2025Detecting Large Language Model (LLM)-generated code is a growing challenge with implications for security, intellectual property, and academic integrity. We investigate the role of conditional probability distributions in improving zero-shot LLM-generated code detection, when considering both the code and the corresponding task prompt that generated it. Our key insight is that when evaluating the probability distribution of code tokens using an LLM, there is little difference between LLM-generated and human-written code. However, conditioning on the task reveals notable differences. This contrasts with natural language text, where differences exist even in the unconditional distributions. Leveraging this, we propose a novel zero-shot detection approach that approximates the original task used to generate a given code snippet and then evaluates token-level entropy under the approximated task conditioning (ATC). We further provide a mathematical intuition, contextualizing our method relative to previous approaches. ATC requires neither access to the generator LLM nor the original task prompts, making it practical for real-world applications. To the best of our knowledge, it achieves state-of-the-art results across benchmarks and generalizes across programming languages, including Python, CPP, and Java. Our findings highlight the importance of task-level conditioning for LLM-generated code detection. The supplementary materials and code are available at https://github.com/maorash/ATC, including the dataset gathering implementation, to foster further research in this area.
A New Dataset and Methodology for Malicious URL Classification
Dec 31, 2024Malicious URL (Uniform Resource Locator) classification is a pivotal aspect of Cybersecurity, offering defense against web-based threats. Despite deep learning's promise in this area, its advancement is hindered by two main challenges: the scarcity of comprehensive, open-source datasets and the limitations of existing models, which either lack real-time capabilities or exhibit suboptimal performance. In order to address these gaps, we introduce a novel, multi-class dataset for malicious URL classification, distinguishing between benign, phishing and malicious URLs, named DeepURLBench. The data has been rigorously cleansed and structured, providing a superior alternative to existing datasets. Notably, the multi-class approach enhances the performance of deep learning models, as compared to a standard binary classification approach. Additionally, we propose improvements to string-based URL classifiers, applying these enhancements to URLNet. Key among these is the integration of DNS-derived features, which enrich the model's capabilities and lead to notable performance gains while preserving real-time runtime efficiency-achieving an effective balance for cybersecurity applications.
Towards Croppable Implicit Neural Representations
Sep 28, 2024



Implicit Neural Representations (INRs) have peaked interest in recent years due to their ability to encode natural signals using neural networks. While INRs allow for useful applications such as interpolating new coordinates and signal compression, their black-box nature makes it difficult to modify them post-training. In this paper we explore the idea of editable INRs, and specifically focus on the widely used cropping operation. To this end, we present Local-Global SIRENs -- a novel INR architecture that supports cropping by design. Local-Global SIRENs are based on combining local and global feature extraction for signal encoding. What makes their design unique is the ability to effortlessly remove specific portions of an encoded signal, with a proportional weight decrease. This is achieved by eliminating the corresponding weights from the network, without the need for retraining. We further show how this architecture can be used to support the straightforward extension of previously encoded signals. Beyond signal editing, we examine how the Local-Global approach can accelerate training, enhance encoding of various signals, improve downstream performance, and be applied to modern INRs such as INCODE, highlighting its potential and flexibility. Code is available at https://github.com/maorash/Local-Global-INRs.
NeRN -- Learning Neural Representations for Neural Networks
Dec 27, 2022Neural Representations have recently been shown to effectively reconstruct a wide range of signals from 3D meshes and shapes to images and videos. We show that, when adapted correctly, neural representations can be used to directly represent the weights of a pre-trained convolutional neural network, resulting in a Neural Representation for Neural Networks (NeRN). Inspired by coordinate inputs of previous neural representation methods, we assign a coordinate to each convolutional kernel in our network based on its position in the architecture, and optimize a predictor network to map coordinates to their corresponding weights. Similarly to the spatial smoothness of visual scenes, we show that incorporating a smoothness constraint over the original network's weights aids NeRN towards a better reconstruction. In addition, since slight perturbations in pre-trained model weights can result in a considerable accuracy loss, we employ techniques from the field of knowledge distillation to stabilize the learning process. We demonstrate the effectiveness of NeRN in reconstructing widely used architectures on CIFAR-10, CIFAR-100, and ImageNet. Finally, we present two applications using NeRN, demonstrating the capabilities of the learned representations.
Wavelet Feature Maps Compression for Image-to-Image CNNs
May 27, 2022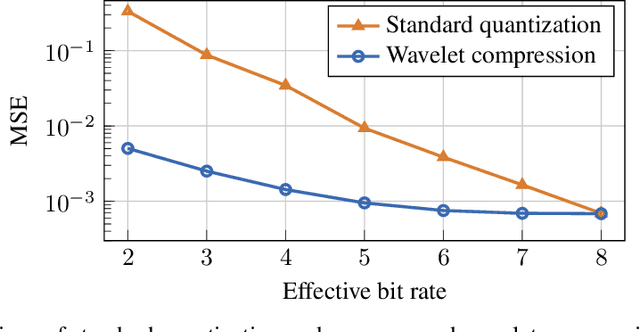
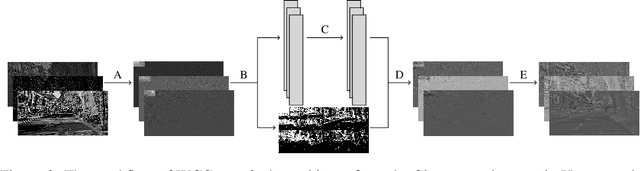
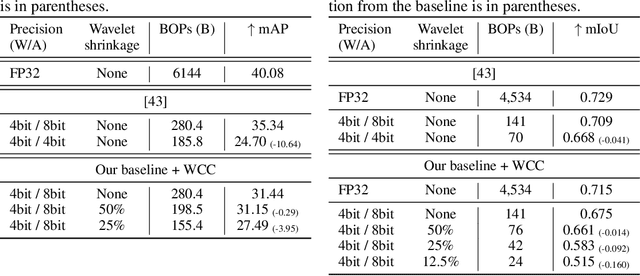

Convolutional Neural Networks (CNNs) are known for requiring extensive computational resources, and quantization is among the best and most common methods for compressing them. While aggressive quantization (i.e., less than 4-bits) performs well for classification, it may cause severe performance degradation in image-to-image tasks such as semantic segmentation and depth estimation. In this paper, we propose Wavelet Compressed Convolution (WCC) -- a novel approach for high-resolution activation maps compression integrated with point-wise convolutions, which are the main computational cost of modern architectures. To this end, we use an efficient and hardware-friendly Haar-wavelet transform, known for its effectiveness in image compression, and define the convolution on the compressed activation map. We experiment on various tasks, that benefit from high-resolution input, and by combining WCC with light quantization, we achieve compression rates equivalent to 1-4bit activation quantization with relatively small and much more graceful degradation in performance.