 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Estimate Labels Uncertainty for Quality Assurance
Sep 17, 2019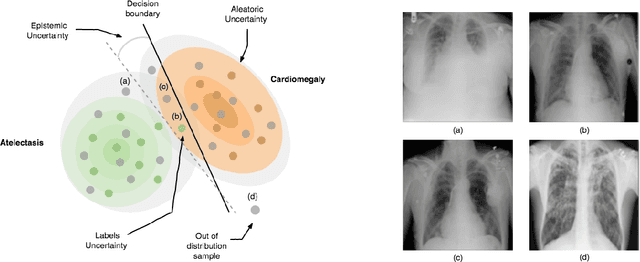


Deep Learning sets the state-of-the-art in many challenging tasks showing outstanding performance in a broad range of applications. Despite its success, it still lacks robustness hindering its adoption in medical applications. Modeling uncertainty, through Bayesian Inference and Monte-Carlo dropout, has been successfully introduced for better understanding the underlying deep learning models. Yet, another important source of uncertainty, coming from the inter-observer variability, has not been thoroughly addressed in the literature. In this paper, we introduce labels uncertainty which better suits medical applications and show that modeling such uncertainty together with epistemic uncertainty is of high interest for quality control and referral systems.
Learn to Segment Organs with a Few Bounding Boxes
Sep 17, 2019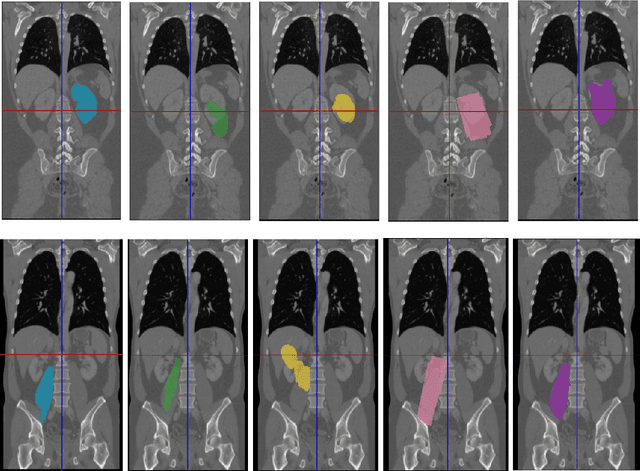
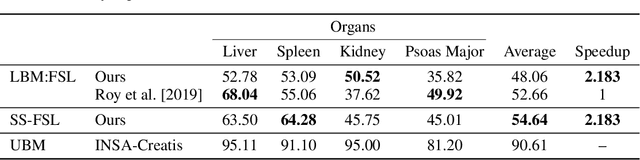
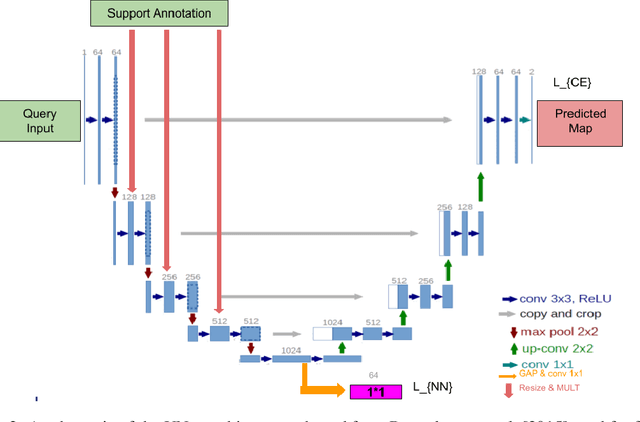
Semantic segmentation is an import task in the medical field to identify the exact extent and orientation of significant structures like organs and pathology. Deep neural networks can perform this task well by leveraging the information from a large well-labeled data-set. This paper aims to present a method that mitigates the necessity of an extensive well-labeled data-set. This method also addresses semi-supervision by enabling segmentation based on bounding box annotations, avoiding the need for full pixel-level annotations. The network presented consists of a single U-Net based unbranched architecture that generates a few-shot segmentation for an unseen human organ using just 4 example annotations of that specific organ. The network is trained by alternately minimizing the nearest neighbor loss for prototype learning and a weighted cross-entropy loss for segmentation learning to perform a fast 3D segmentation with a median score of 54.64%.
Image to Images Translation for Multi-Task Organ Segmentation and Bone Suppression in Chest X-Ray Radiography
Jun 24, 2019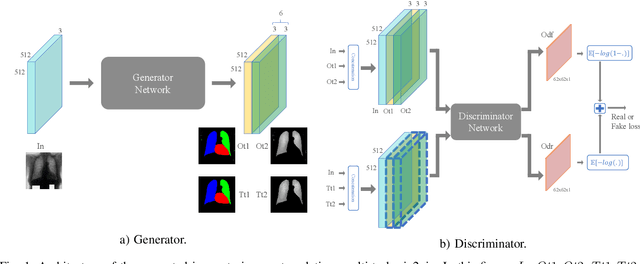


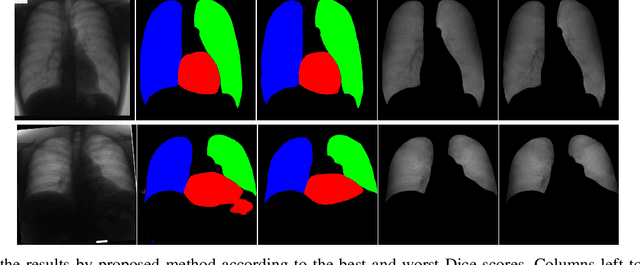
Chest X-ray radiography is one of the earliest medical imaging technologies and remains one of the most widely-used for the diagnosis, screening and treatment follow up of diseases related to lungs and heart. The literature in this field of research reports many interesting studies dealing with the challenging tasks of bone suppression and organ segmentation but performed separately, limiting any learning that comes with the consolidation of parameters that could optimize both processes. Although image processing could facilitate computer aided diagnosis, machine learning seems more amenable in dealing with the many parameters one would have to contend with to yield an near optimal classification or decision-making process. This study, and for the first time, introduces a multitask deep learning model that generates simultaneously the bone-suppressed image and the organ segmented image, minimizing as a consequence the number of parameters the model has to deal with and optimizing the processing time as well; while at the same time exploiting the interplay in these parameters so as to benefit the performance of both tasks. The design architecture of this model, which relies on a conditional generative adversarial network, reveals the process on how we managed to modify the well-established pix2pix network to fit the need for multitasking and hence extending the standard image-to-image network to the new image-to-images architecture. Dilated convolutions are also used to improve the results through a more effective receptive field assessment. A comparison of the proposed approach to state-of-the-art algorithms is provided to gauge the merits of the proposed approach.
Perceptual Embedding Consistency for Seamless Reconstruction of Tilewise Style Transfer
Jun 03, 2019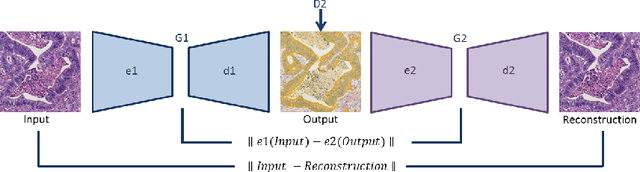


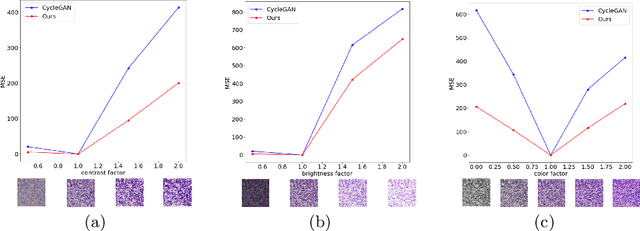
Style transfer is a field with growing interest and use cases in deep learning. Recent work has shown Generative Adversarial Networks(GANs) can be used to create realistic images of virtually stained slide images in digital pathology with clinically validated interpretability. Digital pathology images are typically of extremely high resolution, making tilewise analysis necessary for deep learning applications. It has been shown that image generators with instance normalization can cause a tiling artifact when a large image is reconstructed from the tilewise analysis. We introduce a novel perceptual embedding consistency loss significantly reducing the tiling artifact created in the reconstructed whole slide image (WSI). We validate our results by comparing virtually stained slide images with consecutive real stained tissue slide images. We also demonstrate that our model is more robust to contrast, color and brightness perturbations by running comparative sensitivity analysis tests.
Learning Interpretable Features via Adversarially Robust Optimization
May 09, 2019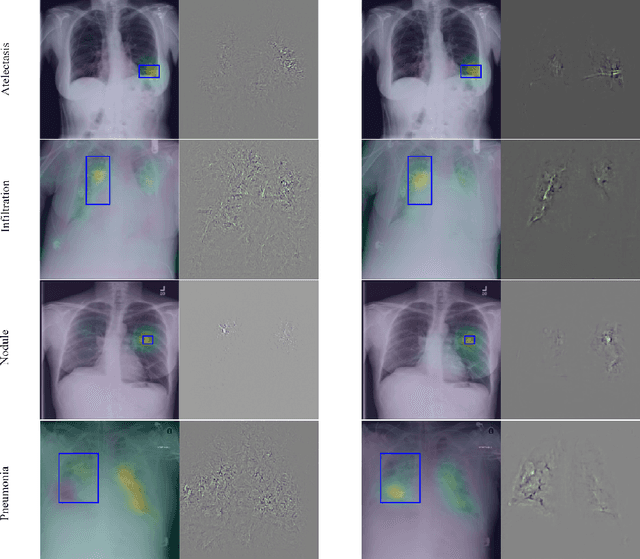
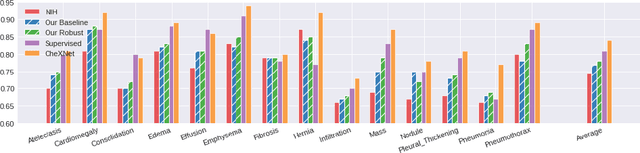
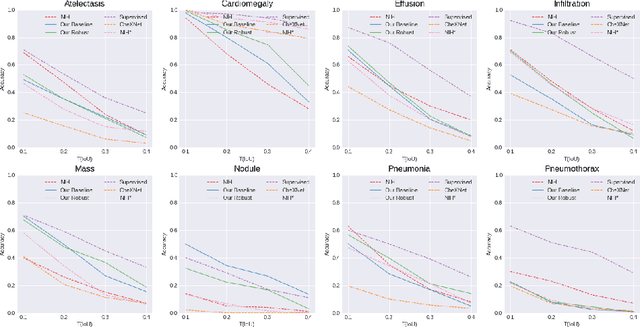

Neural networks are proven to be remarkably successful for classification and diagnosis in medical applications. However, the ambiguity in the decision-making process and the interpretability of the learned features is a matter of concern. In this work, we propose a method for improving the feature interpretability of neural network classifiers. Initially, we propose a baseline convolutional neural network with state of the art performance in terms of accuracy and weakly supervised localization. Subsequently, the loss is modified to integrate robustness to adversarial examples into the training process. In this work, feature interpretability is quantified via evaluating the weakly supervised localization using the ground truth bounding boxes. Interpretability is also visually assessed using class activation maps and saliency maps. The method is applied to NIH ChestX-ray14, the largest publicly available chest x-rays dataset. We demonstrate that the adversarially robust optimization paradigm improves feature interpretability both quantitatively and visually.
Adaptive image-feature learning for disease classification using inductive graph networks
May 08, 2019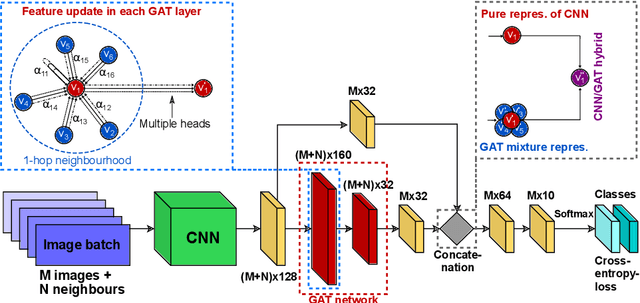
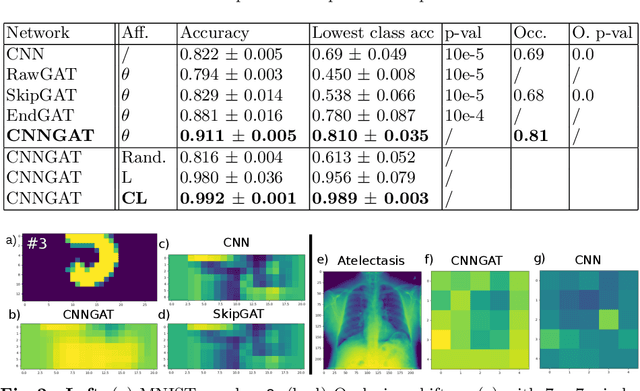

Recently, Geometric Deep Learning (GDL) has been introduced as a novel and versatile framework for computer-aided disease classification. GDL uses patient meta-information such as age and gender to model patient cohort relations in a graph structure. Concepts from graph signal processing are leveraged to learn the optimal mapping of multi-modal features, e.g. from images to disease classes. Related studies so far have considered image features that are extracted in a pre-processing step. We hypothesize that such an approach prevents the network from optimizing feature representations towards achieving the best performance in the graph network. We propose a new network architecture that exploits an inductive end-to-end learning approach for disease classification, where filters from both the CNN and the graph are trained jointly. We validate this architecture against state-of-the-art inductive graph networks and demonstrate significantly improved classification scores on a modified MNIST toy dataset, as well as comparable classification results with higher stability on a chest X-ray image dataset. Additionally, we explain how the structural information of the graph affects both the image filters and the feature learning.
Multi-scale Microaneurysms Segmentation Using Embedding Triplet Loss
Apr 18, 2019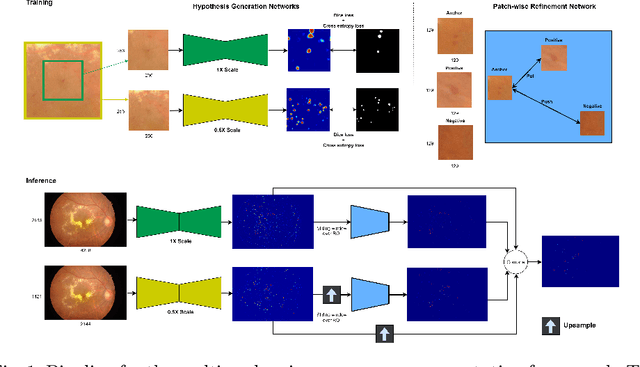
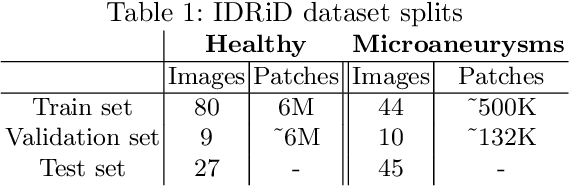
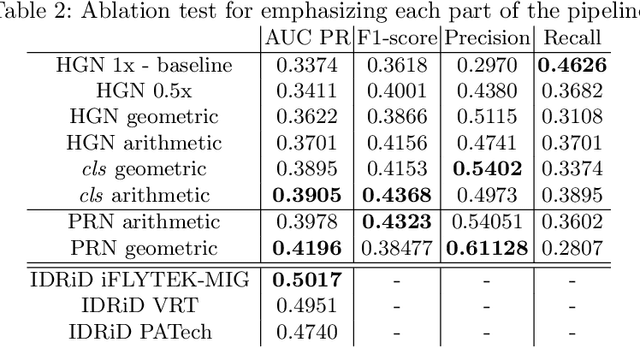
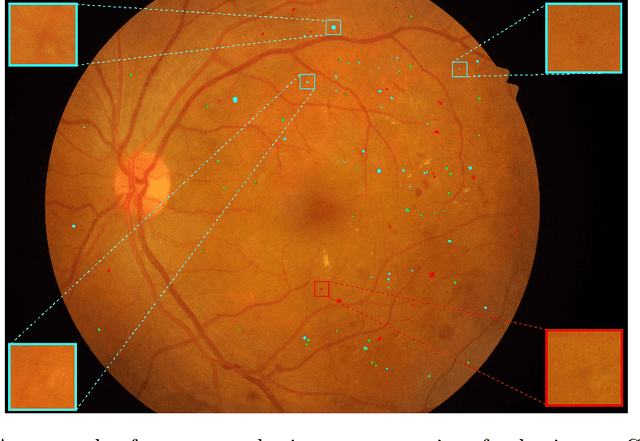
Deep learning techniques are recently being used in fundus image analysis and diabetic retinopathy detection. Microaneurysms are an important indicator of diabetic retinopathy progression. We introduce a two-stage deep learning approach for microaneurysms segmentation using multiple scales of the input with selective sampling and embedding triplet loss. The model first segments on two scales and then the segmentations are refined with a classification model. To enhance the discriminative power of the classification model, we incorporate triplet embedding loss with a selective sampling routine. The model is evaluated quantitatively to assess the segmentation performance and qualitatively to analyze the model predictions. This approach introduces a 30.29% relative improvement over the fully convolutional neural network.
Learning Interpretable Disentangled Representations using Adversarial VAEs
Apr 17, 2019
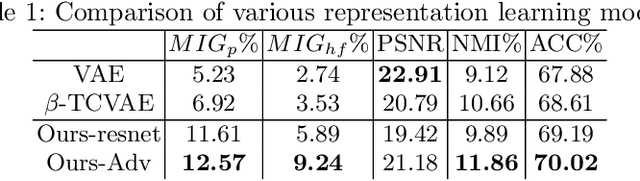
Learning Interpretable representation in medical applications is becoming essential for adopting data-driven models into clinical practice. It has been recently shown that learning a disentangled feature representation is important for a more compact and explainable representation of the data. In this paper, we introduce a novel adversarial variational autoencoder with a total correlation constraint to enforce independence on the latent representation while preserving the reconstruction fidelity. Our proposed method is validated on a publicly available dataset showing that the learned disentangled representation is not only interpretable, but also superior to the state-of-the-art methods. We report a relative improvement of 81.50% in terms of disentanglement, 11.60% in clustering, and 2% in supervised classification with a few amounts of labeled data.
Adversarial Joint Image and Pose Distribution Learning for Camera Pose Regression and Refinement
Mar 26, 2019

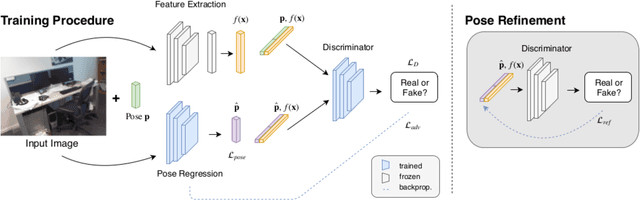
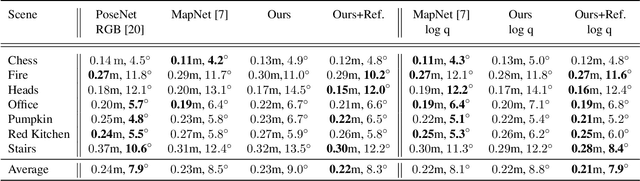
Despite recent advances on the topic of direct camera pose regression using neural networks, accurately estimating the camera pose of a single RGB image still remains a challenging task. To address this problem, we introduce a novel framework based, in its core, on the idea of modeling the joint distribution of RGB images and their corresponding camera poses using adversarial learning. Our method allows not only to regress the camera pose from a single image, however, also offers a solely RGB-based solution for camera pose refinement using the discriminator network. Further, we show that our method can effectively be used to optimize the predicted camera poses and thus improve the localization accuracy. To this end, we validate our proposed method on the publicly available 7-Scenes dataset improving upon the results of current state-of-the-art direct camera pose regression methods.
InceptionGCN: Receptive Field Aware Graph Convolutional Network for Disease Prediction
Mar 11, 2019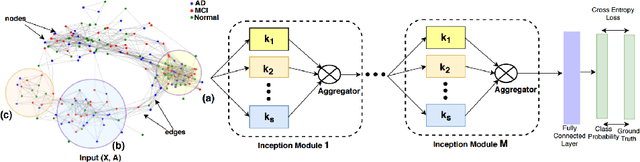
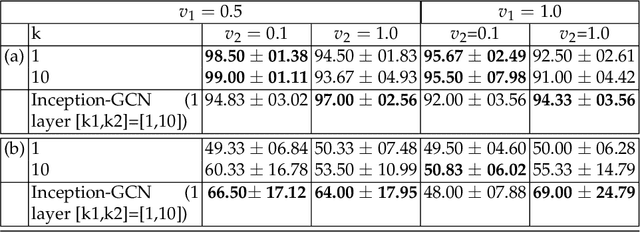
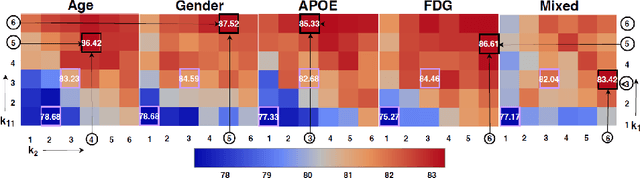
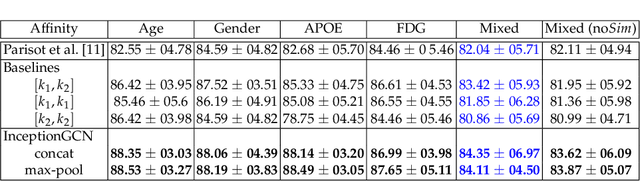
Geometric deep learning provides a principled and versatile manner for the integration of imaging and non-imaging modalities in the medical domain. Graph Convolutional Networks (GCNs) in particular have been explored on a wide variety of problems such as disease prediction, segmentation, and matrix completion by leveraging large, multimodal datasets. In this paper, we introduce a new spectral domain architecture for deep learning on graphs for disease prediction. The novelty lies in defining geometric 'inception modules' which are capable of capturing intra- and inter-graph structural heterogeneity during convolutions. We design filters with different kernel sizes to build our architecture. We show our disease prediction results on two publicly available datasets. Further, we provide insights on the behaviour of regular GCNs and our proposed model under varying input scenarios on simulated data.