 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Understanding of Passenger-Vehicle Interactions in Autonomous Vehicles: Intent/Slot Recognition Utilizing Audio-Visual Data
Sep 20, 2019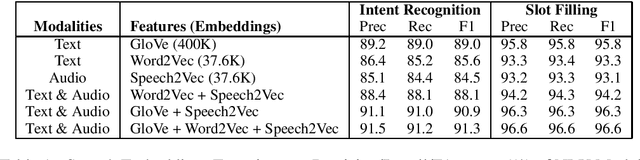

Understanding passenger intents from spoken interactions and car's vision (both inside and outside the vehicle) are important building blocks towards developing contextual dialog systems for natural interactions in autonomous vehicles (AV). In this study, we continued exploring AMIE (Automated-vehicle Multimodal In-cabin Experience), the in-cabin agent responsible for handling certain multimodal passenger-vehicle interactions. When the passengers give instructions to AMIE, the agent should parse such commands properly considering available three modalities (language/text, audio, video) and trigger the appropriate functionality of the AV system. We had collected a multimodal in-cabin dataset with multi-turn dialogues between the passengers and AMIE using a Wizard-of-Oz scheme via realistic scavenger hunt game. In our previous explorations, we experimented with various RNN-based models to detect utterance-level intents (set destination, change route, go faster, go slower, stop, park, pull over, drop off, open door, and others) along with intent keywords and relevant slots (location, position/direction, object, gesture/gaze, time-guidance, person) associated with the action to be performed in our AV scenarios. In this recent work, we propose to discuss the benefits of multimodal understanding of in-cabin utterances by incorporating verbal/language input (text and speech embeddings) together with the non-verbal/acoustic and visual input from inside and outside the vehicle (i.e., passenger gestures and gaze from in-cabin video stream, referred objects outside of the vehicle from the road view camera stream). Our experimental results outperformed text-only baselines and with multimodality, we achieved improved performances for utterance-level intent detection and slot filling.
* Presented as a short-paper at the 23rd Workshop on the Semantics and Pragmatics of Dialogue (SemDial 2019 - LondonLogue), Sep 4-6, 2019, London, UK
Natural Language Interactions in Autonomous Vehicles: Intent Detection and Slot Filling from Passenger Utterances
Apr 23, 2019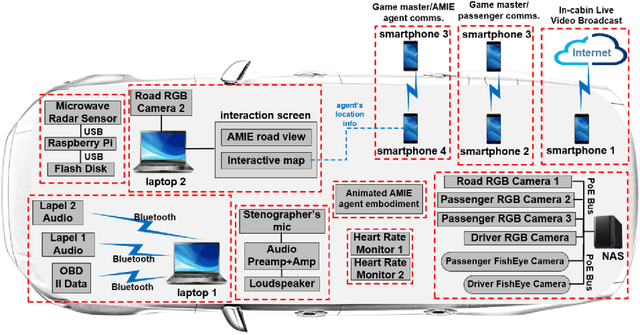
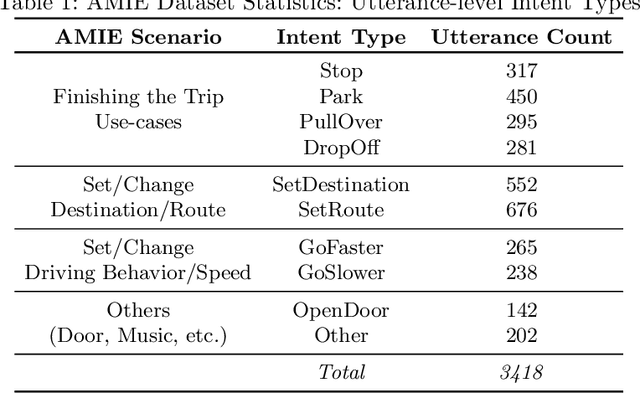

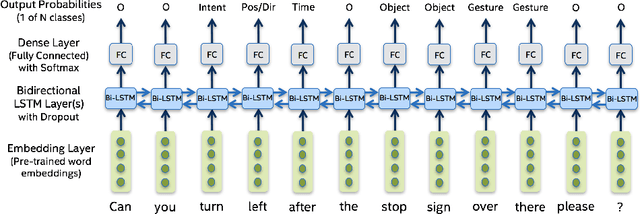
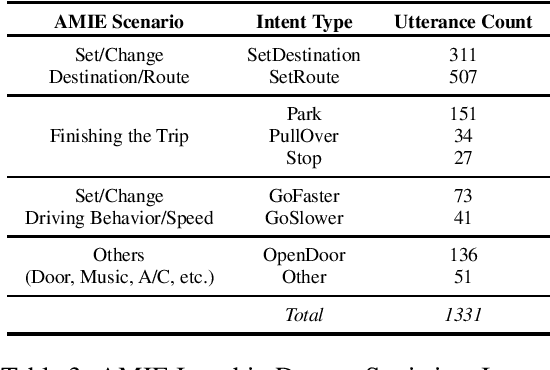
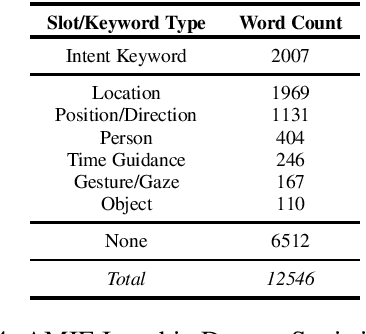
Understanding passenger intents and extracting relevant slots are important building blocks towards developing contextual dialogue systems for natural interactions in autonomous vehicles (AV). In this work, we explored AMIE (Automated-vehicle Multi-modal In-cabin Experience), the in-cabin agent responsible for handling certain passenger-vehicle interactions. When the passengers give instructions to AMIE, the agent should parse such commands properly and trigger the appropriate functionality of the AV system. In our current explorations, we focused on AMIE scenarios describing usages around setting or changing the destination and route, updating driving behavior or speed, finishing the trip and other use-cases to support various natural commands. We collected a multi-modal in-cabin dataset with multi-turn dialogues between the passengers and AMIE using a Wizard-of-Oz scheme via a realistic scavenger hunt game activity. After exploring various recent Recurrent Neural Networks (RNN) based techniques, we introduced our own hierarchical joint models to recognize passenger intents along with relevant slots associated with the action to be performed in AV scenarios. Our experimental results outperformed certain competitive baselines and achieved overall F1 scores of 0.91 for utterance-level intent detection and 0.96 for slot filling tasks. In addition, we conducted initial speech-to-text explorations by comparing intent/slot models trained and tested on human transcriptions versus noisy Automatic Speech Recognition (ASR) outputs. Finally, we compared the results with single passenger rides versus the rides with multiple passengers.
* Accepted and presented as a full paper at 20th International Conference on Computational Linguistics and Intelligent Text Processing (CICLing 2019), April 7-13, 2019, La Rochelle, France
Context, Attention and Audio Feature Explorations for Audio Visual Scene-Aware Dialog
Dec 20, 2018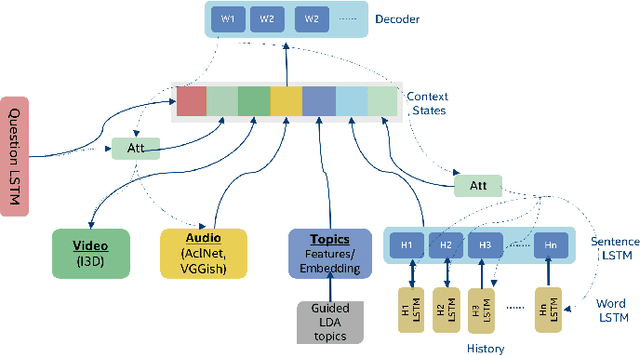

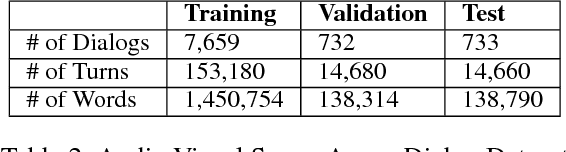
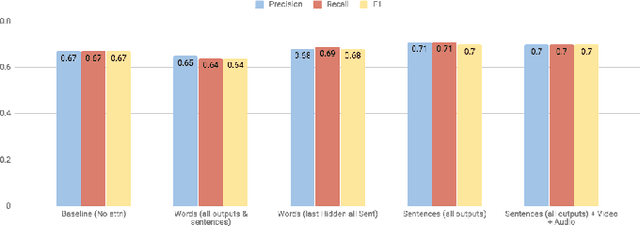
With the recent advancements in AI, Intelligent Virtual Assistants (IVA) have become a ubiquitous part of every home. Going forward, we are witnessing a confluence of vision, speech and dialog system technologies that are enabling the IVAs to learn audio-visual groundings of utterances and have conversations with users about the objects, activities and events surrounding them. As a part of the 7th Dialog System Technology Challenges (DSTC7), for Audio Visual Scene-Aware Dialog (AVSD) track, We explore `topics' of the dialog as an important contextual feature into the architecture along with explorations around multimodal Attention. We also incorporate an end-to-end audio classification ConvNet, AclNet, into our models. We present detailed analysis of the experiments and show that some of our model variations outperform the baseline system presented for this task.
Conversational Intent Understanding for Passengers in Autonomous Vehicles
Dec 14, 2018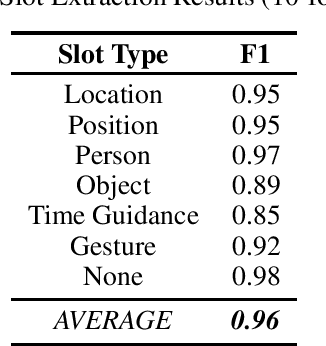
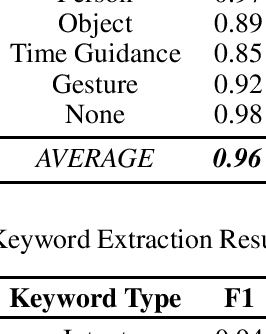


Understanding passenger intents and extracting relevant slots are important building blocks towards developing a contextual dialogue system responsible for handling certain vehicle-passenger interactions in autonomous vehicles (AV). When the passengers give instructions to AMIE (Automated-vehicle Multimodal In-cabin Experience), the agent should parse such commands properly and trigger the appropriate functionality of the AV system. In our AMIE scenarios, we describe usages and support various natural commands for interacting with the vehicle. We collected a multimodal in-cabin data-set with multi-turn dialogues between the passengers and AMIE using a Wizard-of-Oz scheme. We explored various recent Recurrent Neural Networks (RNN) based techniques and built our own hierarchical models to recognize passenger intents along with relevant slots associated with the action to be performed in AV scenarios. Our experimental results achieved F1-score of 0.91 on utterance-level intent recognition and 0.96 on slot extraction models.
Multimodal Relational Tensor Network for Sentiment and Emotion Classification
Jun 07, 2018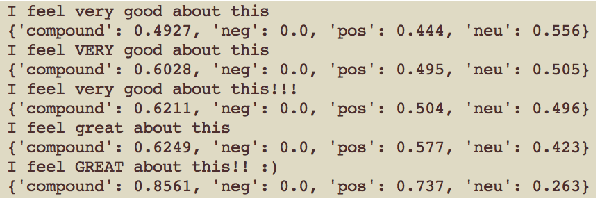
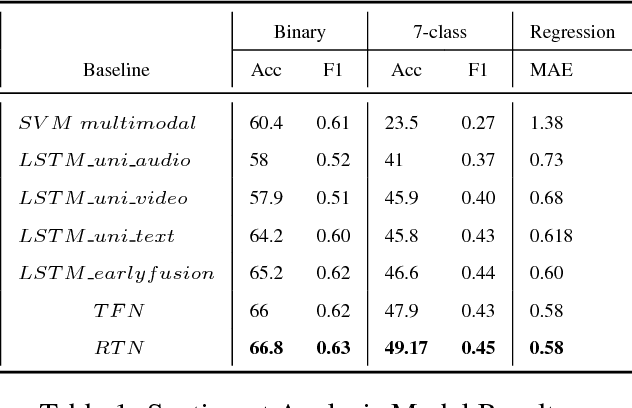
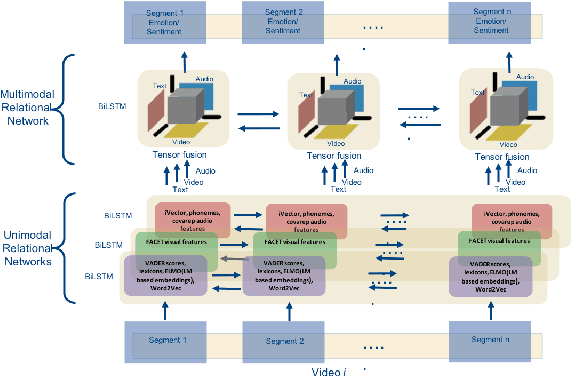
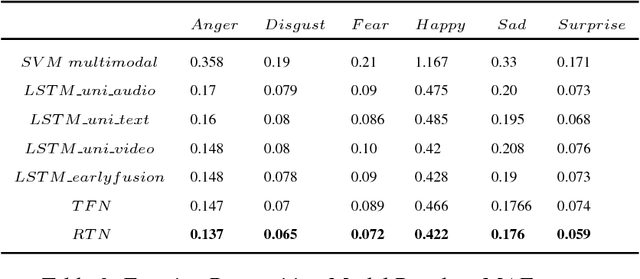
Understanding Affect from video segments has brought researchers from the language, audio and video domains together. Most of the current multimodal research in this area deals with various techniques to fuse the modalities, and mostly treat the segments of a video independently. Motivated by the work of (Zadeh et al., 2017) and (Poria et al., 2017), we present our architecture, Relational Tensor Network, where we use the inter-modal interactions within a segment (intra-segment) and also consider the sequence of segments in a video to model the inter-segment inter-modal interactions. We also generate rich representations of text and audio modalities by leveraging richer audio and linguistic context alongwith fusing fine-grained knowledge based polarity scores from text. We present the results of our model on CMU-MOSEI dataset and show that our model outperforms many baselines and state of the art methods for sentiment classification and emotion recognition.