 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediocrity is the key for LLM as a Judge Anchor Selection
Mar 17, 2026The ``LLM-as-a-judge'' paradigm has become a standard method for evaluating open-ended generation. To address the quadratic scalability costs of pairwise comparisons, popular benchmarks like Arena-Hard and AlpacaEval compare all models against a single anchor. However, despite its widespread use, the impact of anchor selection on the reliability of the results remains largely unexplored. In this work, we systematically investigate the effect of anchor selection by evaluating 22 different anchors on the Arena-Hard-v2.0 dataset. We find that the choice of anchor is critical: a poor anchor can dramatically reduce correlation with human rankings. We identify that common anchor choices (best-performing and worst-performing models) make poor anchors. Because these extreme anchors are consistently better or worse than all other models, they are seldom indicative of the relative ranking of the models. We further quantify the effect size of anchor selection, showing it is comparable to the selection of a judge model. We conclude with actionable recommendations. First, we conduct a power analysis, and compute sufficient benchmark sizes for anchor-based evaluation, finding that standard benchmark sizes are insufficient for pairwise evaluation and fail to distinguish between competitive models reliably. Second, we provide guidelines for selecting informative anchors to ensure reliable and efficient evaluation practices.
The ShareLM Collection and Plugin: Contributing Human-Model Chats for the Benefit of the Community
Aug 15, 2024


Human-model conversations provide a window into users' real-world scenarios, behavior, and needs, and thus are a valuable resource for model development and research. While for-profit companies collect user data through the APIs of their models, using it internally to improve their own models, the open source and research community lags behind. We introduce the ShareLM collection, a unified set of human conversations with large language models, and its accompanying plugin, a Web extension for voluntarily contributing user-model conversations. Where few platforms share their chats, the ShareLM plugin adds this functionality, thus, allowing users to share conversations from most platforms. The plugin allows the user to rate their conversations, both at the conversation and the response levels, and delete conversations they prefer to keep private before they ever leave the user's local storage. We release the plugin conversations as part of the ShareLM collection, and call for more community effort in the field of open human-model data. The code, plugin, and data are available.
Learning from Naturally Occurring Feedback
Jul 15, 2024Human feedback data is a critical component in developing language models. However, collecting this feedback is costly and ultimately not scalable. We propose a scalable method for extracting feedback that users naturally include when interacting with chat models, and leveraging it for model training. We are further motivated by previous work that showed there are also qualitative advantages to using naturalistic (rather than auto-generated) feedback, such as less hallucinations and biases. We manually annotated conversation data to confirm the presence of naturally occurring feedback in a standard corpus, finding that as much as 30% of the chats include explicit feedback. We apply our method to over 1M conversations to obtain hundreds of thousands of feedback samples. Training with the extracted feedback shows significant performance improvements over baseline models, demonstrating the efficacy of our approach in enhancing model alignment to human preferences.
Human Learning by Model Feedback: The Dynamics of Iterative Prompting with Midjourney
Nov 20, 2023



Generating images with a Text-to-Image model often requires multiple trials, where human users iteratively update their prompt based on feedback, namely the output image. Taking inspiration from cognitive work on reference games and dialogue alignment, this paper analyzes the dynamics of the user prompts along such iterations. We compile a dataset of iterative interactions of human users with Midjourney. Our analysis then reveals that prompts predictably converge toward specific traits along these iterations. We further study whether this convergence is due to human users, realizing they missed important details, or due to adaptation to the model's ``preferences'', producing better images for a specific language style. We show initial evidence that both possibilities are at play. The possibility that users adapt to the model's preference raises concerns about reusing user data for further training. The prompts may be biased towards the preferences of a specific model, rather than align with human intentions and natural manner of expression.
ColD Fusion: Collaborative Descent for Distributed Multitask Finetuning
Dec 02, 2022Pretraining has been shown to scale well with compute, data size and data diversity. Multitask learning trains on a mixture of supervised datasets and produces improved performance compared to self-supervised pretraining. Until now, massively multitask learning required simultaneous access to all datasets in the mixture and heavy compute resources that are only available to well-resourced teams. In this paper, we propose ColD Fusion, a method that provides the benefits of multitask learning but leverages distributed computation and requires limited communication and no sharing of data. Consequentially, ColD Fusion can create a synergistic loop, where finetuned models can be recycled to continually improve the pretrained model they are based on. We show that ColD Fusion yields comparable benefits to multitask pretraining by producing a model that (a) attains strong performance on all of the datasets it was multitask trained on and (b) is a better starting point for finetuning on unseen datasets. We find ColD Fusion outperforms RoBERTa and even previous multitask models. Specifically, when training and testing on 35 diverse datasets, ColD Fusion-based model outperforms RoBERTa by 2.45 points in average without any changes to the architecture.
PreQuEL: Quality Estimation of Machine Translation Outputs in Advance
May 18, 2022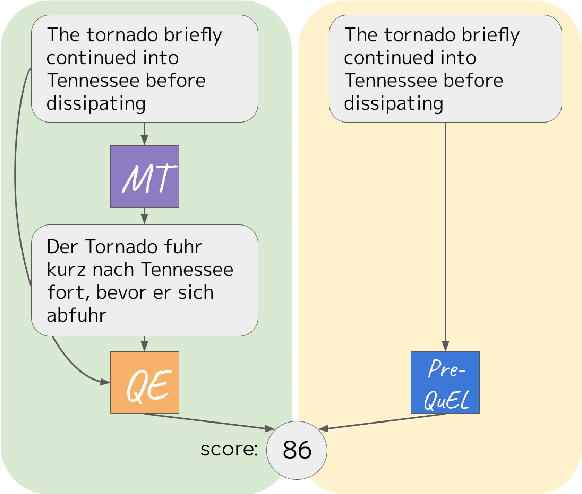
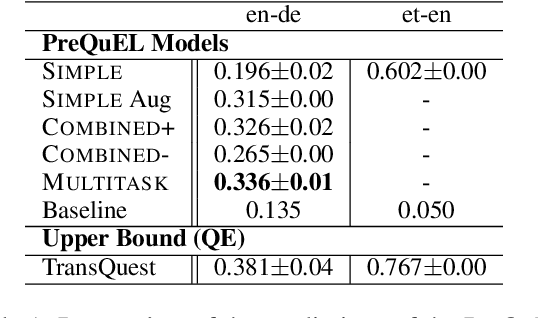
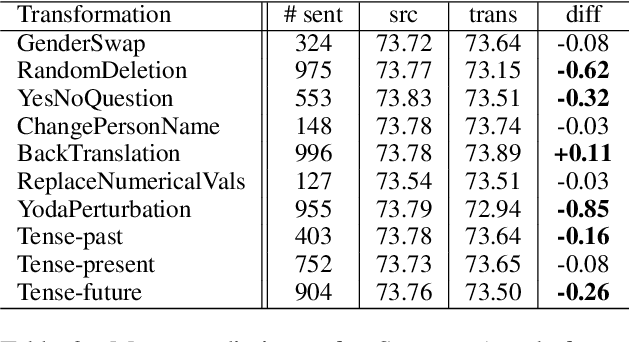
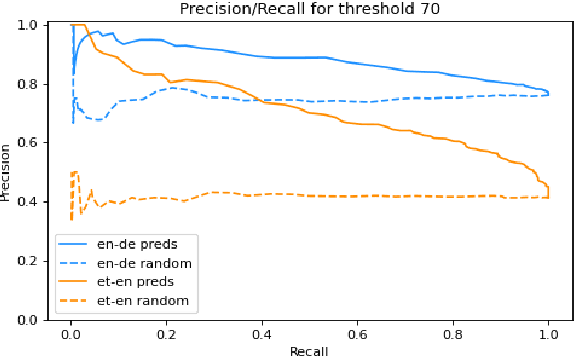
We present the task of PreQuEL, Pre-(Quality-Estimation) Learning. A PreQuEL system predicts how well a given sentence will be translated, without recourse to the actual translation, thus eschewing unnecessary resource allocation when translation quality is bound to be low. PreQuEL can be defined relative to a given MT system (e.g., some industry service) or generally relative to the state-of-the-art. From a theoretical perspective, PreQuEL places the focus on the source text, tracing properties, possibly linguistic features, that make a sentence harder to machine translate. We develop a baseline model for the task and analyze its performance. We also develop a data augmentation method (from parallel corpora), that improves results substantially. We show that this augmentation method can improve the performance of the Quality-Estimation task as well. We investigate the properties of the input text that our model is sensitive to, by testing it on challenge sets and different languages. We conclude that it is aware of syntactic and semantic distinctions, and correlates and even over-emphasizes the importance of standard NLP features.