 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Skill Optimization for Text-to-SQL Ensembles
May 20, 2026Text-to-SQL ensembles improve over single-candidate generation by drawing multiple SQL candidates and selecting one, but their effectiveness is bounded by Pass@K, the probability that at least one of K candidates is correct. Existing methods source diversity heuristically through stochastic decoding or prompt variants, leaving candidate sets dominated by correlated failures. We present DivSkill-SQL, a residual skill optimization framework that builds complementary agentic Text-to-SQL ensembles without model fine-tuning: each new skill is optimized on examples the current skill ensemble fails on, provably targeting its marginal contribution to Pass@K. On Spider2-Lite, DivSkill-SQL improves selected accuracy by up to +11.1 points on Snowflake and +8.3 on BigQuery over the strongest ensemble baseline, with consistent gains across two base models (Opus-4.6 and GPT-5.4). Skills optimized on a single dialect transfer without retraining across dialects (Snowflake, BigQuery, SQLite) and to a different task formulation, such as BIRD-Critic (+2.6 pts). Error diagnostics show up to 3x fewer hallucinated schema references and function calls, indicating that gains come from genuinely reliable complementary skills rather than surface-form variation.
Towards Robust Offline Evaluation: A Causal and Information Theoretic Framework for Debiasing Ranking Systems
Apr 04, 2025Evaluating retrieval-ranking systems is crucial for developing high-performing models. While online A/B testing is the gold standard, its high cost and risks to user experience require effective offline methods. However, relying on historical interaction data introduces biases-such as selection, exposure, conformity, and position biases-that distort evaluation metrics, driven by the Missing-Not-At-Random (MNAR) nature of user interactions and favoring popular or frequently exposed items over true user preferences. We propose a novel framework for robust offline evaluation of retrieval-ranking systems, transforming MNAR data into Missing-At-Random (MAR) through reweighting combined with black-box optimization, guided by neural estimation of information-theoretic metrics. Our contributions include (1) a causal formulation for addressing offline evaluation biases, (2) a system-agnostic debiasing framework, and (3) empirical validation of its effectiveness. This framework enables more accurate, fair, and generalizable evaluations, enhancing model assessment before deployment.
Scalable Out-of-distribution Robustness in the Presence of Unobserved Confounders
Nov 29, 2024We consider the task of out-of-distribution (OOD) generalization, where the distribution shift is due to an unobserved confounder ($Z$) affecting both the covariates ($X$) and the labels ($Y$). In this setting, traditional assumptions of covariate and label shift are unsuitable due to the confounding, which introduces heterogeneity in the predictor, i.e., $\hat{Y} = f_Z(X)$. OOD generalization differs from traditional domain adaptation by not assuming access to the covariate distribution ($X^\text{te}$) of the test samples during training. These conditions create a challenging scenario for OOD robustness: (a) $Z^\text{tr}$ is an unobserved confounder during training, (b) $P^\text{te}{Z} \neq P^\text{tr}{Z}$, (c) $X^\text{te}$ is unavailable during training, and (d) the posterior predictive distribution depends on $P^\text{te}(Z)$, i.e., $\hat{Y} = E_{P^\text{te}(Z)}[f_Z(X)]$. In general, accurate predictions are unattainable in this scenario, and existing literature has proposed complex predictors based on identifiability assumptions that require multiple additional variables. Our work investigates a set of identifiability assumptions that tremendously simplify the predictor, whose resulting elegant simplicity outperforms existing approaches.
Graph Neural Network based Double Machine Learning Estimator of Network Causal Effects
Mar 17, 2024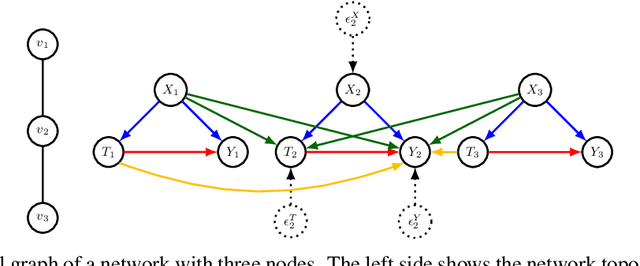
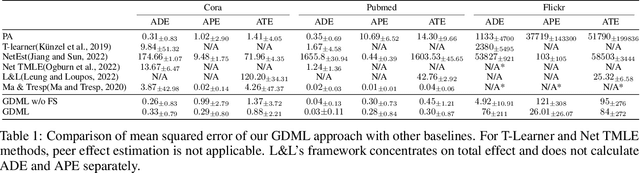
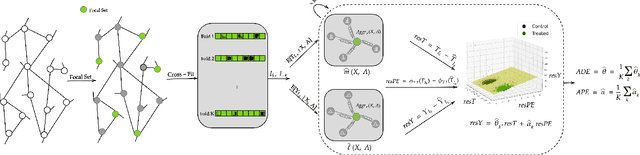

Our paper addresses the challenge of inferring causal effects in social network data, characterized by complex interdependencies among individuals resulting in challenges such as non-independence of units, interference (where a unit's outcome is affected by neighbors' treatments), and introduction of additional confounding factors from neighboring units. We propose a novel methodology combining graph neural networks and double machine learning, enabling accurate and efficient estimation of direct and peer effects using a single observational social network. Our approach utilizes graph isomorphism networks in conjunction with double machine learning to effectively adjust for network confounders and consistently estimate the desired causal effects. We demonstrate that our estimator is both asymptotically normal and semiparametrically efficient. A comprehensive evaluation against four state-of-the-art baseline methods using three semi-synthetic social network datasets reveals our method's on-par or superior efficacy in precise causal effect estimation. Further, we illustrate the practical application of our method through a case study that investigates the impact of Self-Help Group participation on financial risk tolerance. The results indicate a significant positive direct effect, underscoring the potential of our approach in social network analysis. Additionally, we explore the effects of network sparsity on estimation performance.