 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeq2Seq2Seq: Lossless Data Compression via Discrete Latent Transformers and Reinforcement Learning
Feb 12, 2026Efficient lossless compression is essential for minimizing storage costs and transmission overhead while preserving data integrity. Traditional compression techniques, such as dictionary-based and statistical methods, often struggle to optimally exploit the structure and redundancy in complex data formats. Recent advancements in deep learning have opened new avenues for compression; however, many existing approaches depend on dense vector representations that obscure the underlying token structure. To address these limitations, we propose a novel lossless compression method that leverages Reinforcement Learning applied to a T5 language model architecture. This approach enables the compression of data into sequences of tokens rather than traditional vector representations. Unlike auto-encoders, which typically encode information into continuous latent spaces, our method preserves the token-based structure, aligning more closely with the original data format. This preservation allows for higher compression ratios while maintaining semantic integrity. By training the model using an off-policy Reinforcement Learning algorithm, we optimize sequence length to minimize redundancy and enhance compression efficiency. Our method introduces an efficient and adaptive data compression system built upon advanced Reinforcement Learning techniques, functioning independently of external grammatical or world knowledge. This approach shows significant improvements in compression ratios compared to conventional methods. By leveraging the latent information within language models, our system effectively compresses data without requiring explicit content understanding, paving the way for more robust and practical compression solutions across various applications.
From Semantic Roles to Opinion Roles: SRL Data Extraction for Multi-Task and Transfer Learning in Low-Resource ORL
Nov 11, 2025



This report presents a detailed methodology for constructing a high-quality Semantic Role Labeling (SRL) dataset from the Wall Street Journal (WSJ) portion of the OntoNotes 5.0 corpus and adapting it for Opinion Role Labeling (ORL) tasks. Leveraging the PropBank annotation framework, we implement a reproducible extraction pipeline that aligns predicate-argument structures with surface text, converts syntactic tree pointers to coherent spans, and applies rigorous cleaning to ensure semantic fidelity. The resulting dataset comprises 97,169 predicate-argument instances with clearly defined Agent (ARG0), Predicate (REL), and Patient (ARG1) roles, mapped to ORL's Holder, Expression, and Target schema. We provide a detailed account of our extraction algorithms, discontinuous argument handling, annotation corrections, and statistical analysis of the resulting dataset. This work offers a reusable resource for researchers aiming to leverage SRL for enhancing ORL, especially in low-resource opinion mining scenarios.
Vision Transformers in Precision Agriculture: A Comprehensive Survey
Apr 30, 2025Detecting plant diseases is a crucial aspect of modern agriculture - it plays a key role in maintaining crop health and increasing overall yield. Traditional approaches, though still valuable, often rely on manual inspection or conventional machine learning techniques, both of which face limitations in scalability and accuracy. Recently, Vision Transformers (ViTs) have emerged as a promising alternative, offering benefits such as improved handling of long-range dependencies and better scalability for visual tasks. This survey explores the application of ViTs in precision agriculture, covering tasks from classification to detection and segmentation. We begin by introducing the foundational architecture of ViTs and discuss their transition from Natural Language Processing (NLP) to computer vision. The discussion includes the concept of inductive bias in traditional models like Convolutional Neural Networks (CNNs), and how ViTs mitigate these biases. We provide a comprehensive review of recent literature, focusing on key methodologies, datasets, and performance metrics. The survey also includes a comparative analysis of CNNs and ViTs, with a look at hybrid models and performance enhancements. Technical challenges - such as data requirements, computational demands, and model interpretability - are addressed alongside potential solutions. Finally, we outline potential research directions and technological advancements that could further support the integration of ViTs in real-world agricultural settings. Our goal with this study is to offer practitioners and researchers a deeper understanding of how ViTs are poised to transform smart and precision agriculture.
Active Few-Shot Learning for Text Classification
Feb 26, 2025The rise of Large Language Models (LLMs) has boosted the use of Few-Shot Learning (FSL) methods in natural language processing, achieving acceptable performance even when working with limited training data. The goal of FSL is to effectively utilize a small number of annotated samples in the learning process. However, the performance of FSL suffers when unsuitable support samples are chosen. This problem arises due to the heavy reliance on a limited number of support samples, which hampers consistent performance improvement even when more support samples are added. To address this challenge, we propose an active learning-based instance selection mechanism that identifies effective support instances from the unlabeled pool and can work with different LLMs. Our experiments on five tasks show that our method frequently improves the performance of FSL. We make our implementation available on GitHub.
The Impact of Quantization on the Robustness of Transformer-based Text Classifiers
Mar 08, 2024


Transformer-based models have made remarkable advancements in various NLP areas. Nevertheless, these models often exhibit vulnerabilities when confronted with adversarial attacks. In this paper, we explore the effect of quantization on the robustness of Transformer-based models. Quantization usually involves mapping a high-precision real number to a lower-precision value, aiming at reducing the size of the model at hand. To the best of our knowledge, this work is the first application of quantization on the robustness of NLP models. In our experiments, we evaluate the impact of quantization on BERT and DistilBERT models in text classification using SST-2, Emotion, and MR datasets. We also evaluate the performance of these models against TextFooler, PWWS, and PSO adversarial attacks. Our findings show that quantization significantly improves (by an average of 18.68%) the adversarial accuracy of the models. Furthermore, we compare the effect of quantization versus that of the adversarial training approach on robustness. Our experiments indicate that quantization increases the robustness of the model by 18.80% on average compared to adversarial training without imposing any extra computational overhead during training. Therefore, our results highlight the effectiveness of quantization in improving the robustness of NLP models.
Views Are My Own, But Also Yours: Benchmarking Theory of Mind using Common Ground
Mar 04, 2024



Evaluating the theory of mind (ToM) capabilities of language models (LMs) has recently received much attention. However, many existing benchmarks rely on synthetic data which risks misaligning the resulting experiments with human behavior. We introduce the first ToM dataset based on naturally occurring spoken dialogs, Common-ToM, and show that LMs struggle to demonstrate ToM. We then show that integrating a simple, explicit representation of beliefs improves LM performance on Common-ToM.
Finding Common Ground: Annotating and Predicting Common Ground in Spoken Conversations
Nov 02, 2023



When we communicate with other humans, we do not simply generate a sequence of words. Rather, we use our cognitive state (beliefs, desires, intentions) and our model of the audience's cognitive state to create utterances that affect the audience's cognitive state in the intended manner. An important part of cognitive state is the common ground, which is the content the speaker believes, and the speaker believes the audience believes, and so on. While much attention has been paid to common ground in cognitive science, there has not been much work in natural language processing. In this paper, we introduce a new annotation and corpus to capture common ground. We then describe some initial experiments extracting propositions from dialog and tracking their status in the common ground from the perspective of each speaker.
Prose2Poem: The Blessing of Transformers in Translating Prose to Persian Poetry
Oct 01, 2021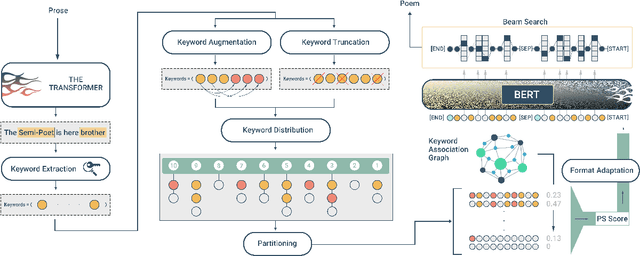

Persian Poetry has consistently expressed its philosophy, wisdom, speech, and rationale on the basis of its couplets, making it an enigmatic language on its own to both native and non-native speakers. Nevertheless, the notice able gap between Persian prose and poem has left the two pieces of literature medium-less. Having curated a parallel corpus of prose and their equivalent poems, we introduce a novel Neural Machine Translation (NMT) approach to translate prose to ancient Persian poetry using transformer-based Language Models in an extremely low-resource setting. More specifically, we trained a Transformer model from scratch to obtain initial translations and pretrained different variations of BERT to obtain final translations. To address the challenge of using masked language modelling under poeticness criteria, we heuristically joined the two models and generated valid poems in terms of automatic and human assessments. Final results demonstrate the eligibility and creativity of our novel heuristically aided approach among Literature professionals and non-professionals in generating novel Persian poems.
Improving Question Answering Performance Using Knowledge Distillation and Active Learning
Sep 26, 2021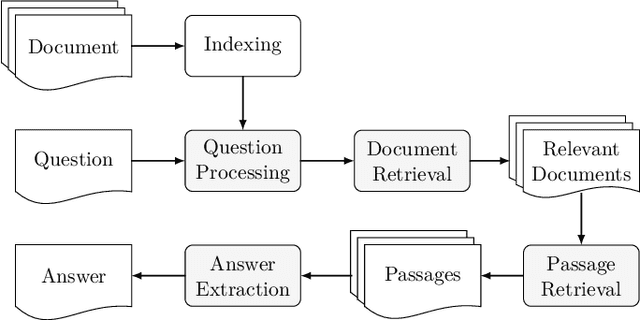

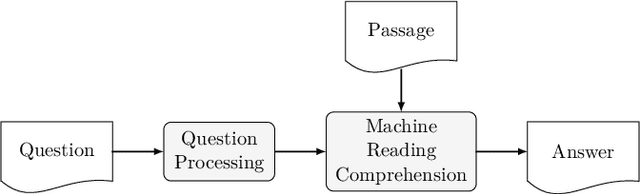
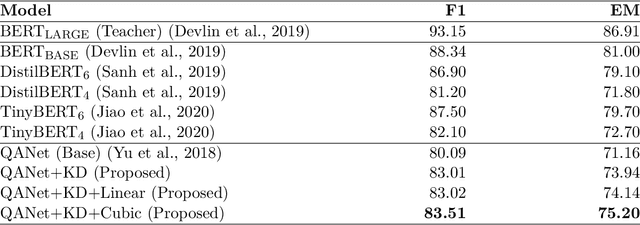
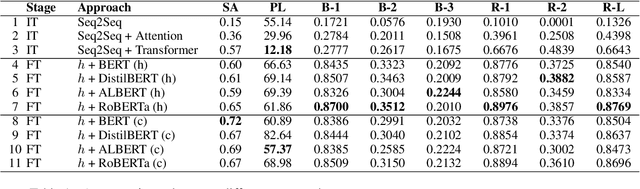
Contemporary question answering (QA) systems, including transformer-based architectures, suffer from increasing computational and model complexity which render them inefficient for real-world applications with limited resources. Further, training or even fine-tuning such models requires a vast amount of labeled data which is often not available for the task at hand. In this manuscript, we conduct a comprehensive analysis of the mentioned challenges and introduce suitable countermeasures. We propose a novel knowledge distillation (KD) approach to reduce the parameter and model complexity of a pre-trained BERT system and utilize multiple active learning (AL) strategies for immense reduction in annotation efforts. In particular, we demonstrate that our model achieves the performance of a 6-layer TinyBERT and DistilBERT, whilst using only 2% of their total parameters. Finally, by the integration of our AL approaches into the BERT framework, we show that state-of-the-art results on the SQuAD dataset can be achieved when we only use 20% of the training data.
Defeating Author Gender Identification with Text Style Transfer
Sep 02, 2020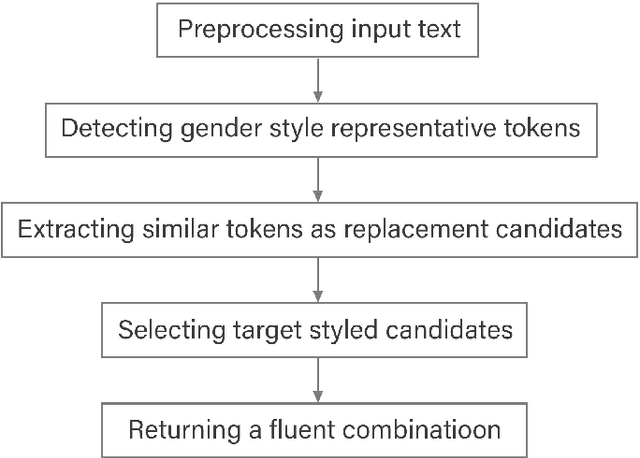
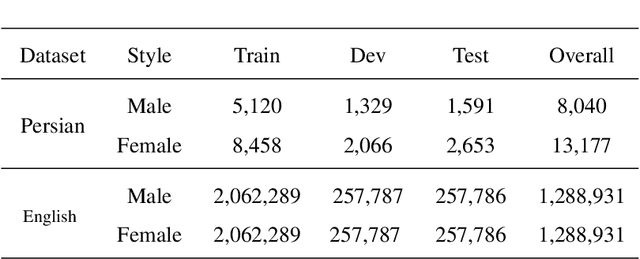
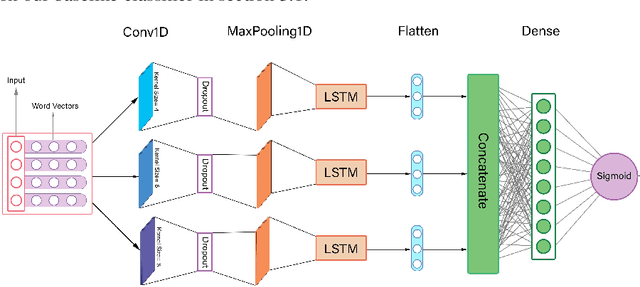
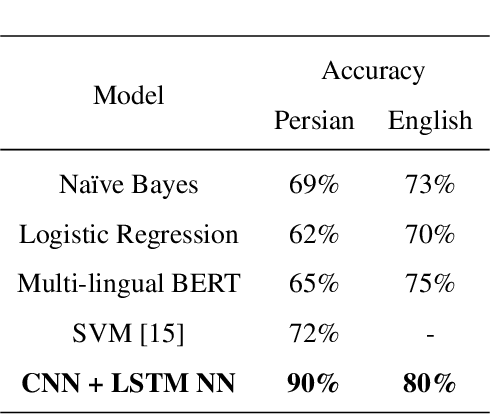
Text Style Transfer can be named as one of the most important Natural Language Processing tasks. Up until now, there have been several approaches and methods experimented for this purpose. In this work, we introduce PGST, a novel polyglot text style transfer approach in gender domain composed of different building blocks. If they become fulfilled with required elements, our method can be applied in multiple languages. We have proceeded with a pre-trained word embedding for token replacement purposes, a character-based token classifier for gender exchange purposes, and the beam search algorithm for extracting the most fluent combination among all suggestions. Since different approaches are introduced in our research, we determine a trade-off value for evaluating different models' success in faking our gender identification model with transferred text. To demonstrate our method's multilingual applicability, we applied our method on both English and Persian corpora and finally ended up defeating our proposed gender identification model by 45.6% and 39.2%, respectively, and obtained highly competitive evaluation results in an analogy among English state of the art methods.