 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowette: Flow Matching with Graphette Priors for Graph Generation
Feb 27, 2026We study generative modeling of graphs with recurring subgraph motifs. We propose Flowette, a continuous flow matching framework, that employs a graph neural network based transformer to learn a velocity field defined over graph representations with node and edge attributes. Our model preserves topology through optimal transport based coupling, and long-range structural dependencies through regularisation. To incorporate domain driven structural priors, we introduce graphettes, a new probabilistic family of graph structure models that generalize graphons via controlled structural edits for motifs like rings, stars and trees. We theoretically analyze the coupling, invariance, and structural properties of the proposed framework, and empirically evaluate it on synthetic and small-molecule graph generation tasks. Flowette demonstrates consistent improvements, highlighting the effectiveness of combining structural priors with flow-based training for modeling complex graph distributions.
Revisiting Pre-processing Group Fairness: A Modular Benchmarking Framework
Aug 21, 2025As machine learning systems become increasingly integrated into high-stakes decision-making processes, ensuring fairness in algorithmic outcomes has become a critical concern. Methods to mitigate bias typically fall into three categories: pre-processing, in-processing, and post-processing. While significant attention has been devoted to the latter two, pre-processing methods, which operate at the data level and offer advantages such as model-agnosticism and improved privacy compliance, have received comparatively less focus and lack standardised evaluation tools. In this work, we introduce FairPrep, an extensible and modular benchmarking framework designed to evaluate fairness-aware pre-processing techniques on tabular datasets. Built on the AIF360 platform, FairPrep allows seamless integration of datasets, fairness interventions, and predictive models. It features a batch-processing interface that enables efficient experimentation and automatic reporting of fairness and utility metrics. By offering standardised pipelines and supporting reproducible evaluations, FairPrep fills a critical gap in the fairness benchmarking landscape and provides a practical foundation for advancing data-level fairness research.
Graphon Mixtures
May 20, 2025Social networks have a small number of large hubs, and a large number of small dense communities. We propose a generative model that captures both hub and dense structures. Based on recent results about graphons on line graphs, our model is a graphon mixture, enabling us to generate sequences of graphs where each graph is a combination of sparse and dense graphs. We propose a new condition on sparse graphs (the max-degree), which enables us to identify hubs. We show theoretically that we can estimate the normalized degree of the hubs, as well as estimate the graphon corresponding to sparse components of graph mixtures. We illustrate our approach on synthetic data, citation graphs, and social networks, showing the benefits of explicitly modeling sparse graphs.
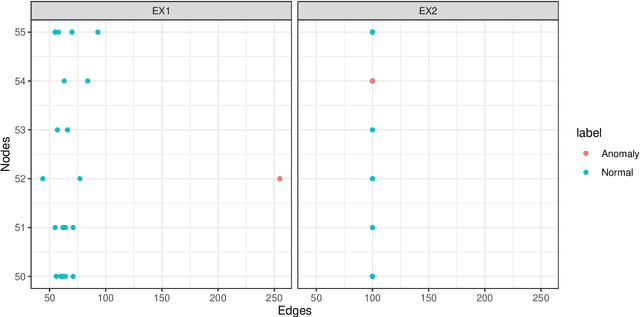
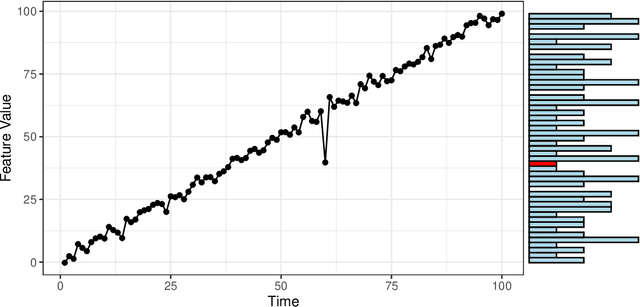
Extreme Value Modelling of Feature Residuals for Anomaly Detection in Dynamic Graphs
Oct 08, 2024Detecting anomalies in a temporal sequence of graphs can be applied is areas such as the detection of accidents in transport networks and cyber attacks in computer networks. Existing methods for detecting abnormal graphs can suffer from multiple limitations, such as high false positive rates as well as difficulties with handling variable-sized graphs and non-trivial temporal dynamics. To address this, we propose a technique where temporal dependencies are explicitly modelled via time series analysis of a large set of pertinent graph features, followed by using residuals to remove the dependencies. Extreme Value Theory is then used to robustly model and classify any remaining extremes, aiming to produce low false positives rates. Comparative evaluations on a multitude of graph instances show that the proposed approach obtains considerably better accuracy than TensorSplat and Laplacian Anomaly Detection.
Graphons of Line Graphs
Sep 03, 2024



A graphon is the limit of a converging graph sequence. Graphons of dense graphs are useful as they can act as a blueprint and generate graphs of arbitrary size with similar properties. But for sparse graphs this is not the case. Sparse graphs converge to the zero graphon, making the generated graphs empty or edgeless. Thus, the classical graphon definition fails for sparse graphs. Several methods have been proposed to overcome this limitation and to understand sparse graphs more deeply. However, the fragile nature of sparse graphs makes these methods mathematically complex. In this paper we show a simple method that can shed light on a certain subset of sparse graphs. The method involves mapping the original graphs to their line graphs. Line graphs map edges to vertices and connects edges when edges in the original graph share a vertex. We show that graphs satisfying a particular property, which we call the square-degree property are sparse, but give rise to dense line graphs. In particular, star graphs satisfy the square-degree property resulting in dense line graphs and non-zero graphons of line graphs. Similarly, superlinear preferential attachment graphs give rise to dense line graphs almost surely. In contrast, dense graphs, including Erdos-Renyi graphs make the line graphs sparse, resulting in the zero graphon.
An Item Response Theory-based R Module for Algorithm Portfolio Analysis
Aug 27, 2024



Experimental evaluation is crucial in AI research, especially for assessing algorithms across diverse tasks. Many studies often evaluate a limited set of algorithms, failing to fully understand their strengths and weaknesses within a comprehensive portfolio. This paper introduces an Item Response Theory (IRT) based analysis tool for algorithm portfolio evaluation called AIRT-Module. Traditionally used in educational psychometrics, IRT models test question difficulty and student ability using responses to test questions. Adapting IRT to algorithm evaluation, the AIRT-Module contains a Shiny web application and the R package airt. AIRT-Module uses algorithm performance measures to compute anomalousness, consistency, and difficulty limits for an algorithm and the difficulty of test instances. The strengths and weaknesses of algorithms are visualised using the difficulty spectrum of the test instances. AIRT-Module offers a detailed understanding of algorithm capabilities across varied test instances, thus enhancing comprehensive AI method assessment. It is available at https://sevvandi.shinyapps.io/AIRT/ .
Predicting the structure of dynamic graphs
Jan 08, 2024



Dynamic graph embeddings, inductive and incremental learning facilitate predictive tasks such as node classification and link prediction. However, predicting the structure of a graph at a future time step from a time series of graphs, allowing for new nodes has not gained much attention. In this paper, we present such an approach. We use time series methods to predict the node degree at future time points and combine it with flux balance analysis -- a linear programming method used in biochemistry -- to obtain the structure of future graphs. Furthermore, we explore the predictive graph distribution for different parameter values. We evaluate this method using synthetic and real datasets and demonstrate its utility and applicability.
DEFT: A new distance-based feature set for keystroke dynamics
Oct 06, 2023



Keystroke dynamics is a behavioural biometric utilised for user identification and authentication. We propose a new set of features based on the distance between keys on the keyboard, a concept that has not been considered before in keystroke dynamics. We combine flight times, a popular metric, with the distance between keys on the keyboard and call them as Distance Enhanced Flight Time features (DEFT). This novel approach provides comprehensive insights into a person's typing behaviour, surpassing typing velocity alone. We build a DEFT model by combining DEFT features with other previously used keystroke dynamic features. The DEFT model is designed to be device-agnostic, allowing us to evaluate its effectiveness across three commonly used devices: desktop, mobile, and tablet. The DEFT model outperforms the existing state-of-the-art methods when we evaluate its effectiveness across two datasets. We obtain accuracy rates exceeding 99% and equal error rates below 10% on all three devices.
Comprehensive Algorithm Portfolio Evaluation using Item Response Theory
Jul 29, 2023



Item Response Theory (IRT) has been proposed within the field of Educational Psychometrics to assess student ability as well as test question difficulty and discrimination power. More recently, IRT has been applied to evaluate machine learning algorithm performance on a single classification dataset, where the student is now an algorithm, and the test question is an observation to be classified by the algorithm. In this paper we present a modified IRT-based framework for evaluating a portfolio of algorithms across a repository of datasets, while simultaneously eliciting a richer suite of characteristics - such as algorithm consistency and anomalousness - that describe important aspects of algorithm performance. These characteristics arise from a novel inversion and reinterpretation of the traditional IRT model without requiring additional dataset feature computations. We test this framework on algorithm portfolios for a wide range of applications, demonstrating the broad applicability of this method as an insightful algorithm evaluation tool. Furthermore, the explainable nature of IRT parameters yield an increased understanding of algorithm portfolios.
Anomaly detection in dynamic networks
Oct 13, 2022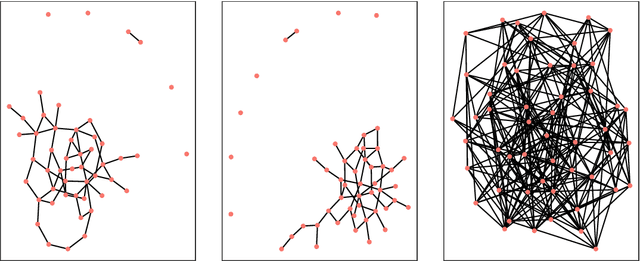
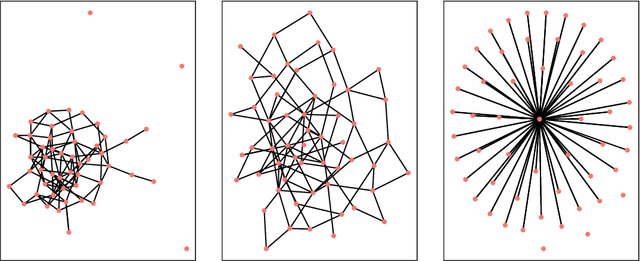
Detecting anomalies from a series of temporal networks has many applications, including road accidents in transport networks and suspicious events in social networks. While there are many methods for network anomaly detection, statistical methods are under utilised in this space even though they have a long history and proven capability in handling temporal dependencies. In this paper, we introduce \textit{oddnet}, a feature-based network anomaly detection method that uses time series methods to model temporal dependencies. We demonstrate the effectiveness of oddnet on synthetic and real-world datasets. The R package oddnet implements this algorithm.