 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Display Photometric Stereo
Jun 28, 2023



Photometric stereo leverages variations in illumination conditions to reconstruct per-pixel surface normals. The concept of display photometric stereo, which employs a conventional monitor as an illumination source, has the potential to overcome limitations often encountered in bulky and difficult-to-use conventional setups. In this paper, we introduce Differentiable Display Photometric Stereo (DDPS), a method designed to achieve high-fidelity normal reconstruction using an off-the-shelf monitor and camera. DDPS addresses a critical yet often neglected challenge in photometric stereo: the optimization of display patterns for enhanced normal reconstruction. We present a differentiable framework that couples basis-illumination image formation with a photometric-stereo reconstruction method. This facilitates the learning of display patterns that leads to high-quality normal reconstruction through automatic differentiation. Addressing the synthetic-real domain gap inherent in end-to-end optimization, we propose the use of a real-world photometric-stereo training dataset composed of 3D-printed objects. Moreover, to reduce the ill-posed nature of photometric stereo, we exploit the linearly polarized light emitted from the monitor to optically separate diffuse and specular reflections in the captured images. We demonstrate that DDPS allows for learning display patterns optimized for a target configuration and is robust to initialization. We assess DDPS on 3D-printed objects with ground-truth normals and diverse real-world objects, validating that DDPS enables effective photometric-stereo reconstruction.
Deep Deformable 3D Caricatures with Learned Shape Control
Jul 29, 2022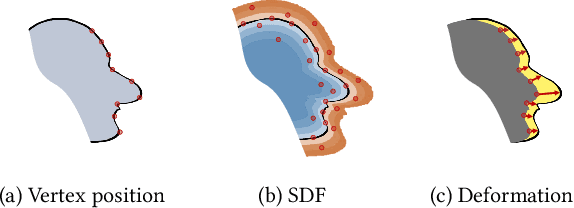
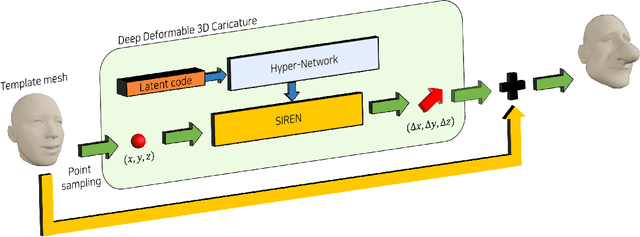


A 3D caricature is an exaggerated 3D depiction of a human face. The goal of this paper is to model the variations of 3D caricatures in a compact parameter space so that we can provide a useful data-driven toolkit for handling 3D caricature deformations. To achieve the goal, we propose an MLP-based framework for building a deformable surface model, which takes a latent code and produces a 3D surface. In the framework, a SIREN MLP models a function that takes a 3D position on a fixed template surface and returns a 3D displacement vector for the input position. We create variations of 3D surfaces by learning a hypernetwork that takes a latent code and produces the parameters of the MLP. Once learned, our deformable model provides a nice editing space for 3D caricatures, supporting label-based semantic editing and point-handle-based deformation, both of which produce highly exaggerated and natural 3D caricature shapes. We also demonstrate other applications of our deformable model, such as automatic 3D caricature creation.
Real-Time Video Deblurring via Lightweight Motion Compensation
Jun 08, 2022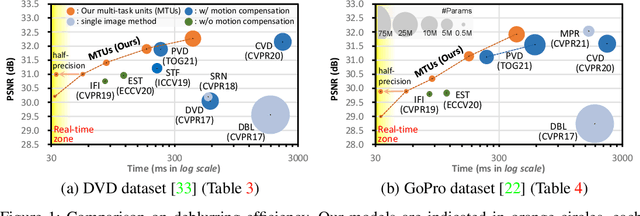

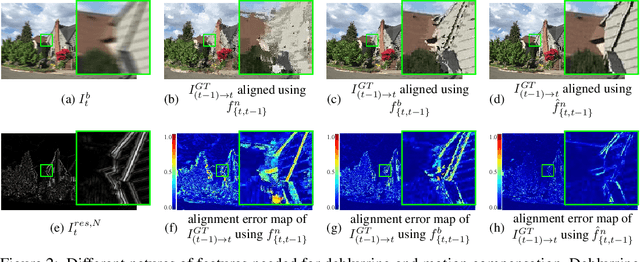
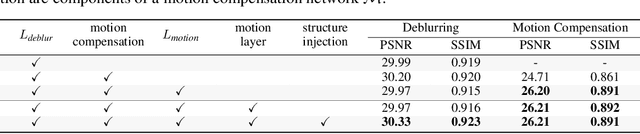
While motion compensation greatly improves video deblurring quality, separately performing motion compensation and video deblurring demands huge computational overhead. This paper proposes a real-time video deblurring framework consisting of a lightweight multi-task unit that supports both video deblurring and motion compensation in an efficient way. The multi-task unit is specifically designed to handle large portions of the two tasks using a single shared network, and consists of a multi-task detail network and simple networks for deblurring and motion compensation. The multi-task unit minimizes the cost of incorporating motion compensation into video deblurring and enables real-time deblurring. Moreover, by stacking multiple multi-task units, our framework provides flexible control between the cost and deblurring quality. We experimentally validate the state-of-the-art deblurring quality of our approach, which runs at a much faster speed compared to previous methods, and show practical real-time performance (30.99dB@30fps measured in the DVD dataset).
Reference-based Video Super-Resolution Using Multi-Camera Video Triplets
Mar 28, 2022
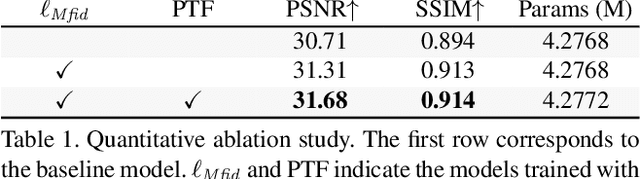
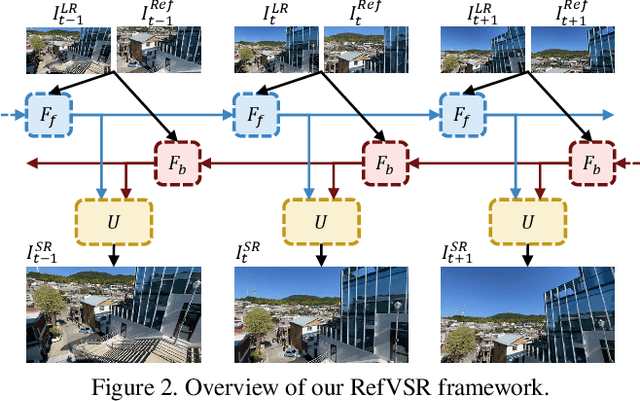
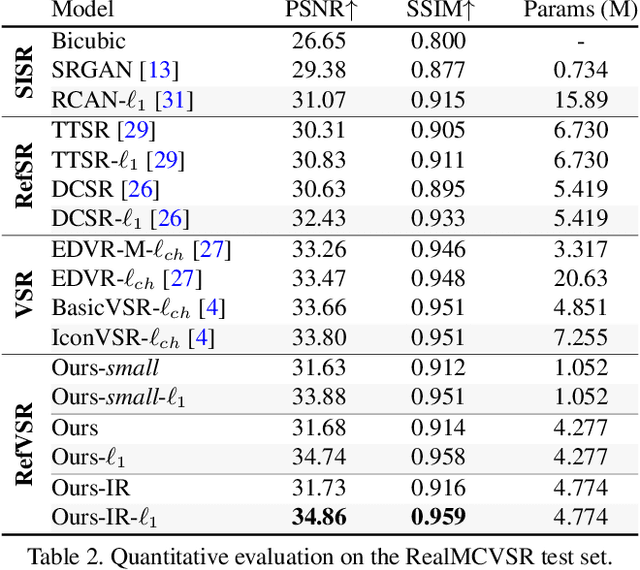
We propose the first reference-based video super-resolution (RefVSR) approach that utilizes reference videos for high-fidelity results. We focus on RefVSR in a triple-camera setting, where we aim at super-resolving a low-resolution ultra-wide video utilizing wide-angle and telephoto videos. We introduce the first RefVSR network that recurrently aligns and propagates temporal reference features fused with features extracted from low-resolution frames. To facilitate the fusion and propagation of temporal reference features, we propose a propagative temporal fusion module. For learning and evaluation of our network, we present the first RefVSR dataset consisting of triplets of ultra-wide, wide-angle, and telephoto videos concurrently taken from triple cameras of a smartphone. We also propose a two-stage training strategy fully utilizing video triplets in the proposed dataset for real-world 4x video super-resolution. We extensively evaluate our method, and the result shows the state-of-the-art performance in 4x super-resolution.
MSSNet: Multi-Scale-Stage Network for Single Image Deblurring
Feb 19, 2022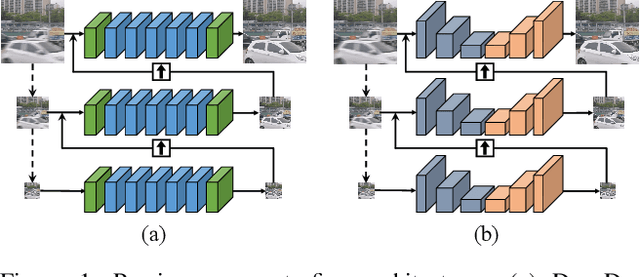
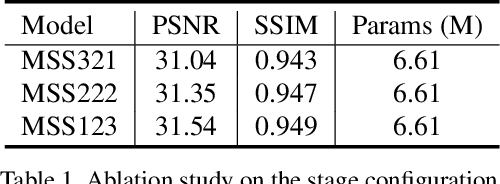
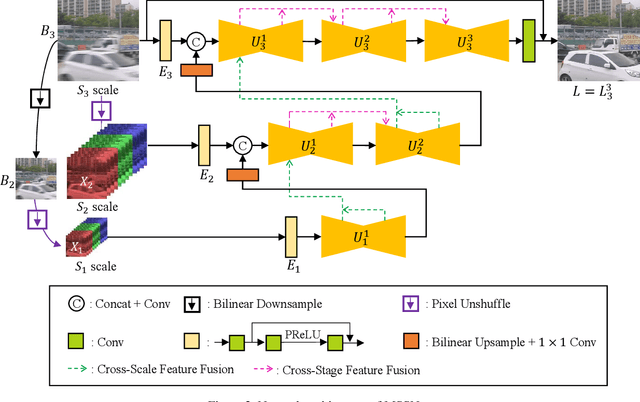
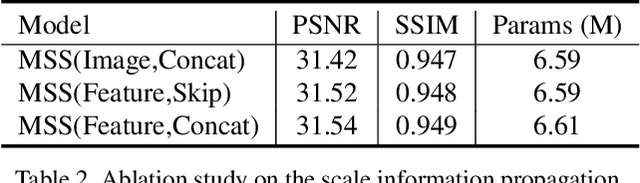
Most of traditional single image deblurring methods before deep learning adopt a coarse-to-fine scheme that estimates a sharp image at a coarse scale and progressively refines it at finer scales. While this scheme has also been adopted to several deep learning-based approaches, recently a number of single-scale approaches have been introduced showing superior performance to previous coarse-to-fine approaches both in quality and computation time, making the traditional coarse-to-fine scheme seemingly obsolete. In this paper, we revisit the coarse-to-fine scheme, and analyze defects of previous coarse-to-fine approaches that degrade their performance. Based on the analysis, we propose Multi-Scale-Stage Network (MSSNet), a novel deep learning-based approach to single image deblurring that adopts our remedies to the defects. Specifically, MSSNet adopts three novel technical components: stage configuration reflecting blur scales, an inter-scale information propagation scheme, and a pixel-shuffle-based multi-scale scheme. Our experiments show that MSSNet achieves the state-of-the-art performance in terms of quality, network size, and computation time.
Realistic Blur Synthesis for Learning Image Deblurring
Feb 17, 2022
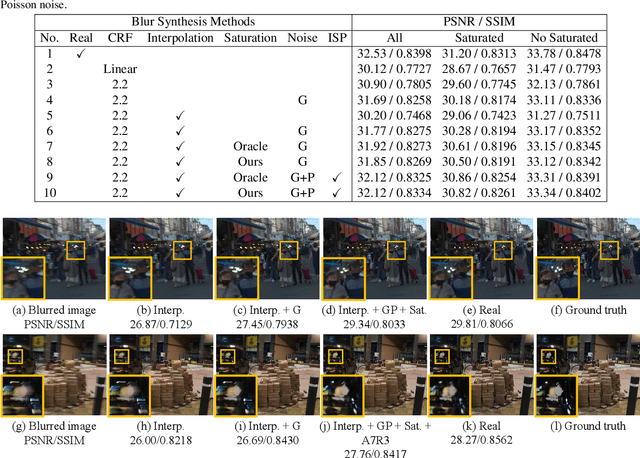
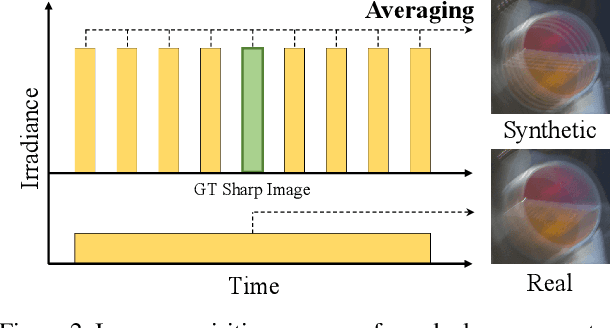

Training learning-based deblurring methods demands a significant amount of blurred and sharp image pairs. Unfortunately, existing synthetic datasets are not realistic enough, and existing real-world blur datasets provide limited diversity of scenes and camera settings. As a result, deblurring models trained on them still suffer from the lack of generalization ability for handling real blurred images. In this paper, we analyze various factors that introduce differences between real and synthetic blurred images, and present a novel blur synthesis pipeline that can synthesize more realistic blur. We also present RSBlur, a novel dataset that contains real blurred images and the corresponding sequences of sharp images. The RSBlur dataset can be used for generating synthetic blurred images to enable detailed analysis on the differences between real and synthetic blur. With our blur synthesis pipeline and RSBlur dataset, we reveal the effects of different factors in the blur synthesis. We also show that our synthesis method can improve the deblurring performance on real blurred images.
Iterative Filter Adaptive Network for Single Image Defocus Deblurring
Aug 31, 2021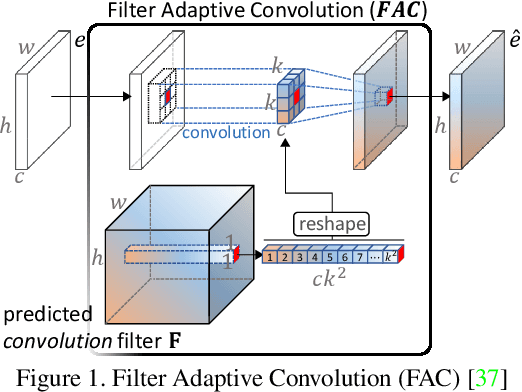
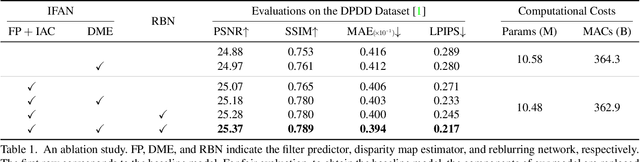
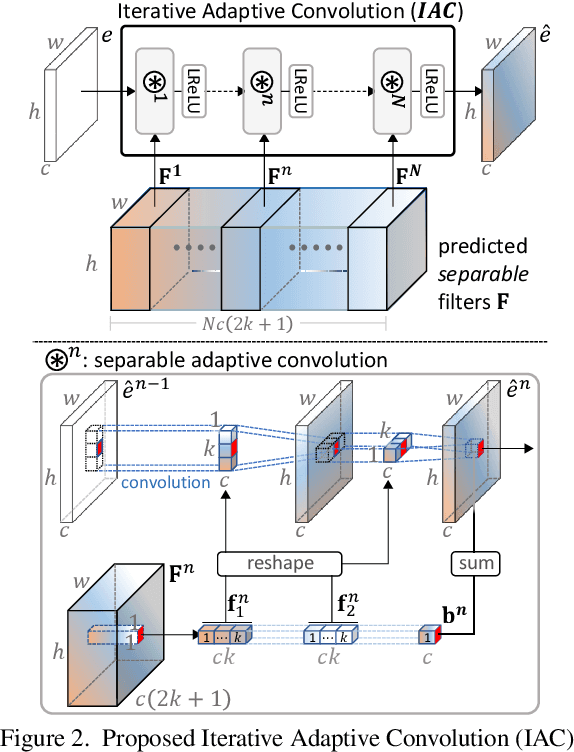
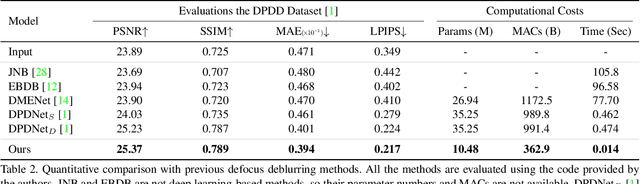
We propose a novel end-to-end learning-based approach for single image defocus deblurring. The proposed approach is equipped with a novel Iterative Filter Adaptive Network (IFAN) that is specifically designed to handle spatially-varying and large defocus blur. For adaptively handling spatially-varying blur, IFAN predicts pixel-wise deblurring filters, which are applied to defocused features of an input image to generate deblurred features. For effectively managing large blur, IFAN models deblurring filters as stacks of small-sized separable filters. Predicted separable deblurring filters are applied to defocused features using a novel Iterative Adaptive Convolution (IAC) layer. We also propose a training scheme based on defocus disparity estimation and reblurring, which significantly boosts the deblurring quality. We demonstrate that our method achieves state-of-the-art performance both quantitatively and qualitatively on real-world images.
* CVPR 2021
Recurrent Video Deblurring with Blur-Invariant Motion Estimation and Pixel Volumes
Aug 23, 2021
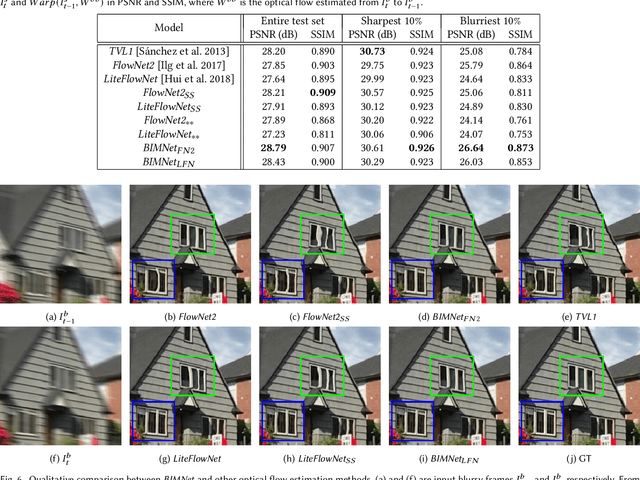
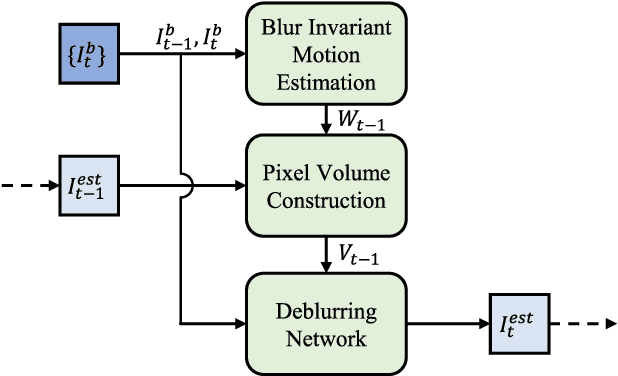
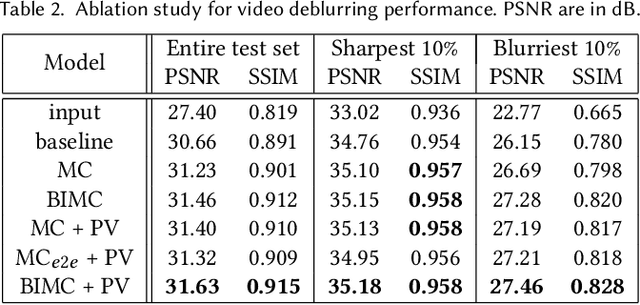
For the success of video deblurring, it is essential to utilize information from neighboring frames. Most state-of-the-art video deblurring methods adopt motion compensation between video frames to aggregate information from multiple frames that can help deblur a target frame. However, the motion compensation methods adopted by previous deblurring methods are not blur-invariant, and consequently, their accuracy is limited for blurry frames with different blur amounts. To alleviate this problem, we propose two novel approaches to deblur videos by effectively aggregating information from multiple video frames. First, we present blur-invariant motion estimation learning to improve motion estimation accuracy between blurry frames. Second, for motion compensation, instead of aligning frames by warping with estimated motions, we use a pixel volume that contains candidate sharp pixels to resolve motion estimation errors. We combine these two processes to propose an effective recurrent video deblurring network that fully exploits deblurred previous frames. Experiments show that our method achieves the state-of-the-art performance both quantitatively and qualitatively compared to recent methods that use deep learning.
Single Image Defocus Deblurring Using Kernel-Sharing Parallel Atrous Convolutions
Aug 20, 2021
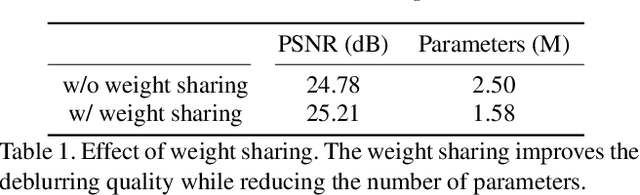

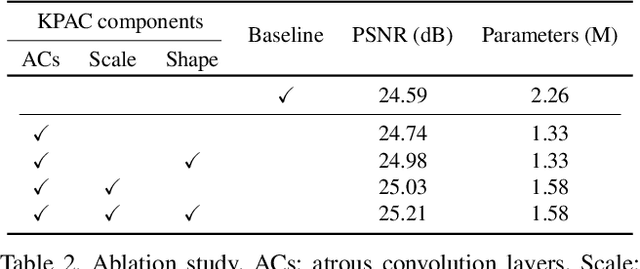
This paper proposes a novel deep learning approach for single image defocus deblurring based on inverse kernels. In a defocused image, the blur shapes are similar among pixels although the blur sizes can spatially vary. To utilize the property with inverse kernels, we exploit the observation that when only the size of a defocus blur changes while keeping the shape, the shape of the corresponding inverse kernel remains the same and only the scale changes. Based on the observation, we propose a kernel-sharing parallel atrous convolutional (KPAC) block specifically designed by incorporating the property of inverse kernels for single image defocus deblurring. To effectively simulate the invariant shapes of inverse kernels with different scales, KPAC shares the same convolutional weights among multiple atrous convolution layers. To efficiently simulate the varying scales of inverse kernels, KPAC consists of only a few atrous convolution layers with different dilations and learns per-pixel scale attentions to aggregate the outputs of the layers. KPAC also utilizes the shape attention to combine the outputs of multiple convolution filters in each atrous convolution layer, to deal with defocus blur with a slightly varying shape. We demonstrate that our approach achieves state-of-the-art performance with a much smaller number of parameters than previous methods.
Spatiotemporal Texture Reconstruction for Dynamic Objects Using a Single RGB-D Camera
Aug 20, 2021This paper presents an effective method for generating a spatiotemporal (time-varying) texture map for a dynamic object using a single RGB-D camera. The input of our framework is a 3D template model and an RGB-D image sequence. Since there are invisible areas of the object at a frame in a single-camera setup, textures of such areas need to be borrowed from other frames. We formulate the problem as an MRF optimization and define cost functions to reconstruct a plausible spatiotemporal texture for a dynamic object. Experimental results demonstrate that our spatiotemporal textures can reproduce the active appearances of captured objects better than approaches using a single texture map.