 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireQ: Fast INT4-FP8 Kernel and RoPE-aware Quantization for LLM Inference Acceleration
May 28, 2025As large language models become increasingly prevalent, memory bandwidth constraints significantly limit inference throughput, motivating post-training quantization (PTQ). In this paper, we propose FireQ, a co-designed PTQ framework and an INT4-FP8 matrix multiplication kernel that accelerates LLM inference across all linear layers. Specifically, FireQ quantizes linear layer weights and key-values to INT4, and activations and queries to FP8, significantly enhancing throughput. Additionally, we introduce a three-stage pipelining for the prefill phase, which modifies the FlashAttention-3 kernel, effectively reducing time-to-first-token in the prefill phase. To minimize accuracy loss from quantization, we develop novel outlier smoothing techniques tailored separately for linear and attention layers. In linear layers, we explicitly use per-tensor scaling to prevent underflow caused by the FP8 quantization scaling factor of INT4 quantization, and channel-wise scaling to compensate for coarse granularity of INT4. In attention layers, we address quantization challenges posed by rotary positional embeddings (RoPE) by combining pre-RoPE and post-RoPE scaling strategies. FireQ significantly outperforms state-of-the-art methods, achieving 1.68x faster inference in feed-forward network layers on Llama2-7B and 1.26x faster prefill phase performance on Llama3-8B compared to QServe, with negligible accuracy loss.
ELIS: Efficient LLM Iterative Scheduling System with Response Length Predictor
May 14, 2025We propose ELIS, a serving system for Large Language Models (LLMs) featuring an Iterative Shortest Remaining Time First (ISRTF) scheduler designed to efficiently manage inference tasks with the shortest remaining tokens. Current LLM serving systems often employ a first-come-first-served scheduling strategy, which can lead to the "head-of-line blocking" problem. To overcome this limitation, it is necessary to predict LLM inference times and apply a shortest job first scheduling strategy. However, due to the auto-regressive nature of LLMs, predicting the inference latency is challenging. ELIS addresses this challenge by training a response length predictor for LLMs using the BGE model, an encoder-based state-of-the-art model. Additionally, we have devised the ISRTF scheduling strategy, an optimization of shortest remaining time first tailored to existing LLM iteration batching. To evaluate our work in an industrial setting, we simulate streams of requests based on our study of real-world user LLM serving trace records. Furthermore, we implemented ELIS as a cloud-native scheduler system on Kubernetes to evaluate its performance in production environments. Our experimental results demonstrate that ISRTF reduces the average job completion time by up to 19.6%.
Multi-model Machine Learning Inference Serving with GPU Spatial Partitioning
Sep 01, 2021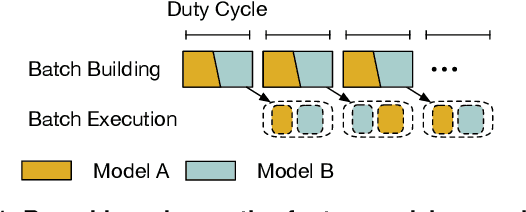

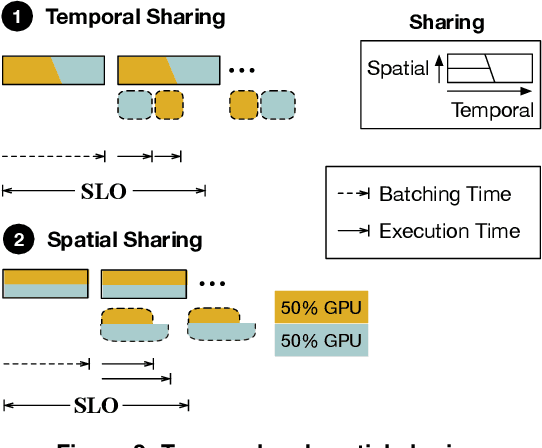
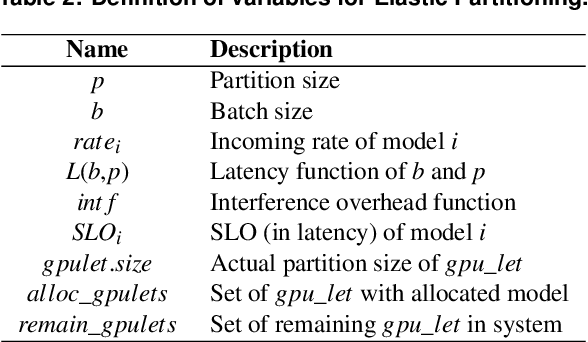
As machine learning techniques are applied to a widening range of applications, high throughput machine learning (ML) inference servers have become critical for online service applications. Such ML inference servers pose two challenges: first, they must provide a bounded latency for each request to support consistent service-level objective (SLO), and second, they can serve multiple heterogeneous ML models in a system as certain tasks involve invocation of multiple models and consolidating multiple models can improve system utilization. To address the two requirements of ML inference servers, this paper proposes a new ML inference scheduling framework for multi-model ML inference servers. The paper first shows that with SLO constraints, current GPUs are not fully utilized for ML inference tasks. To maximize the resource efficiency of inference servers, a key mechanism proposed in this paper is to exploit hardware support for spatial partitioning of GPU resources. With the partitioning mechanism, a new abstraction layer of GPU resources is created with configurable GPU resources. The scheduler assigns requests to virtual GPUs, called gpu-lets, with the most effective amount of resources. The paper also investigates a remedy for potential interference effects when two ML tasks are running concurrently in a GPU. Our prototype implementation proves that spatial partitioning enhances throughput by 102.6% on average while satisfying SLOs.