 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePGT-I: Scaling Spatiotemporal GNNs with Memory-Efficient Distributed Training
Jul 15, 2025Spatiotemporal graph neural networks (ST-GNNs) are powerful tools for modeling spatial and temporal data dependencies. However, their applications have been limited primarily to small-scale datasets because of memory constraints. While distributed training offers a solution, current frameworks lack support for spatiotemporal models and overlook the properties of spatiotemporal data. Informed by a scaling study on a large-scale workload, we present PyTorch Geometric Temporal Index (PGT-I), an extension to PyTorch Geometric Temporal that integrates distributed data parallel training and two novel strategies: index-batching and distributed-index-batching. Our index techniques exploit spatiotemporal structure to construct snapshots dynamically at runtime, significantly reducing memory overhead, while distributed-index-batching extends this approach by enabling scalable processing across multiple GPUs. Our techniques enable the first-ever training of an ST-GNN on the entire PeMS dataset without graph partitioning, reducing peak memory usage by up to 89\% and achieving up to a 13.1x speedup over standard DDP with 128 GPUs.
A Case for Dataset Specific Profiling
Aug 01, 2022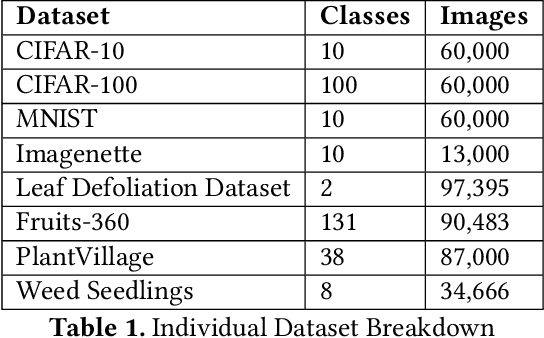
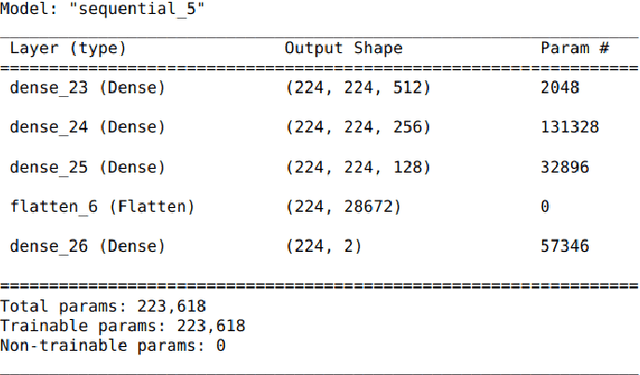
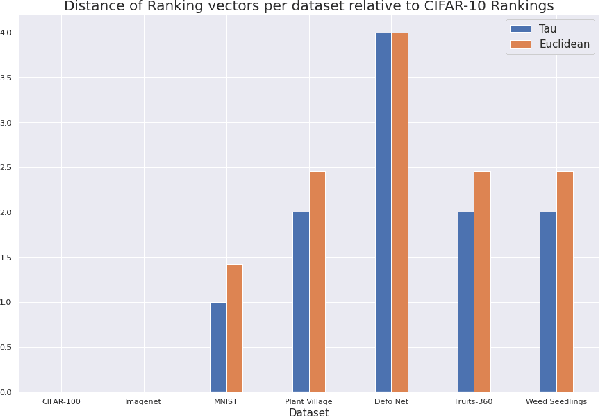
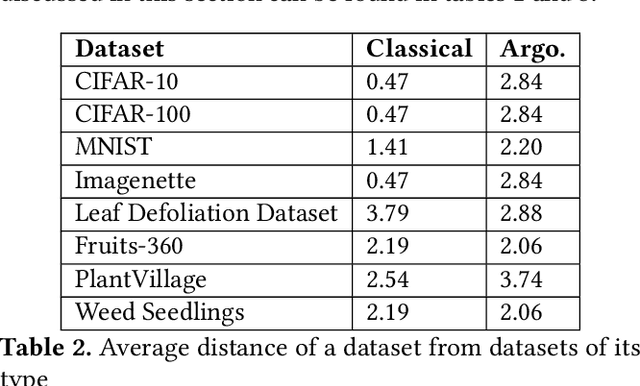
Data-driven science is an emerging paradigm where scientific discoveries depend on the execution of computational AI models against rich, discipline-specific datasets. With modern machine learning frameworks, anyone can develop and execute computational models that reveal concepts hidden in the data that could enable scientific applications. For important and widely used datasets, computing the performance of every computational model that can run against a dataset is cost prohibitive in terms of cloud resources. Benchmarking approaches used in practice use representative datasets to infer performance without actually executing models. While practicable, these approaches limit extensive dataset profiling to a few datasets and introduce bias that favors models suited for representative datasets. As a result, each dataset's unique characteristics are left unexplored and subpar models are selected based on inference from generalized datasets. This necessitates a new paradigm that introduces dataset profiling into the model selection process. To demonstrate the need for dataset-specific profiling, we answer two questions:(1) Can scientific datasets significantly permute the rank order of computational models compared to widely used representative datasets? (2) If so, could lightweight model execution improve benchmarking accuracy? Taken together, the answers to these questions lay the foundation for a new dataset-aware benchmarking paradigm.