 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: A hierarchical multiscale approach for time series forecasting
Dec 31, 2025Forecasting is critical in areas such as finance, biology, and healthcare. Despite the progress in the field, making accurate forecasts remains challenging because real-world time series contain both global trends, local fine-grained structure, and features on multiple scales in between. Here, we present a new forecasting method, PRISM (Partitioned Representation for Iterative Sequence Modeling), that addresses this challenge through a learnable tree-based partitioning of the signal. At the root of the tree, a global representation captures coarse trends in the signal, while recursive splits reveal increasingly localized views of the signal. At each level of the tree, data are projected onto a time-frequency basis (e.g., wavelets or exponential moving averages) to extract scale-specific features, which are then aggregated across the hierarchy. This design allows the model to jointly capture global structure and local dynamics of the signal, enabling accurate forecasting. Experiments across benchmark datasets show that our method outperforms state-of-the-art methods for forecasting. Overall, these results demonstrate that our hierarchical approach provides a lightweight and flexible framework for forecasting multivariate time series. The code is available at https://github.com/nerdslab/prism.
DeepNose: An Equivariant Convolutional Neural Network Predictive Of Human Olfactory Percepts
Dec 11, 2024



The olfactory system employs responses of an ensemble of odorant receptors (ORs) to sense molecules and to generate olfactory percepts. Here we hypothesized that ORs can be viewed as 3D spatial filters that extract molecular features relevant to the olfactory system, similarly to the spatio-temporal filters found in other sensory modalities. To build these filters, we trained a convolutional neural network (CNN) to predict human olfactory percepts obtained from several semantic datasets. Our neural network, the DeepNose, produced responses that are approximately invariant to the molecules' orientation, due to its equivariant architecture. Our network offers high-fidelity perceptual predictions for different olfactory datasets. In addition, our approach allows us to identify molecular features that contribute to specific perceptual descriptors. Because the DeepNose network is designed to be aligned with the biological system, our approach predicts distinct perceptual qualities for different stereoisomers. The architecture of the DeepNose relying on the processing of several molecules at the same time permits inferring the perceptual quality of odor mixtures. We propose that the DeepNose network can use 3D molecular shapes to generate high-quality predictions for human olfactory percepts and help identify molecular features responsible for odor quality.
Representations of Sound in Deep Learning of Audio Features from Music
Dec 08, 2017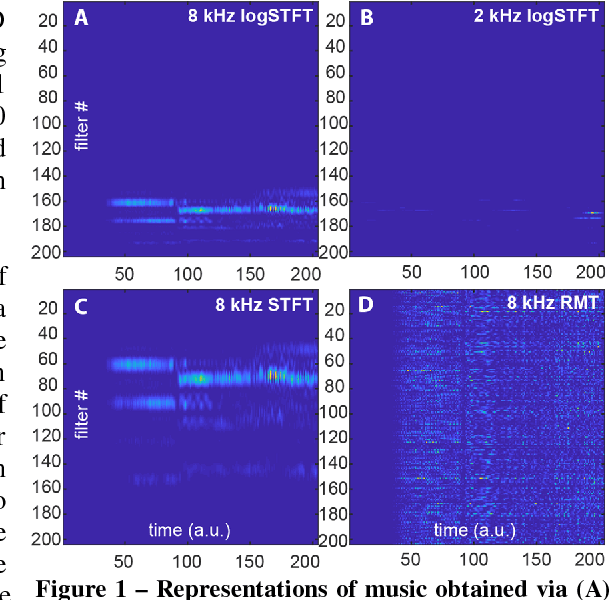
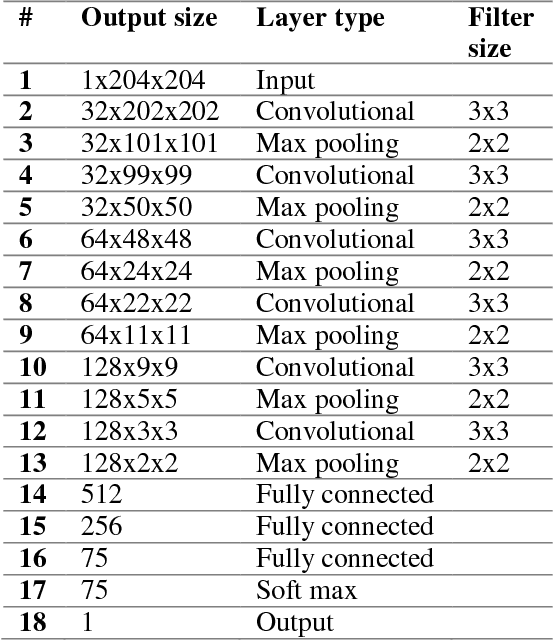
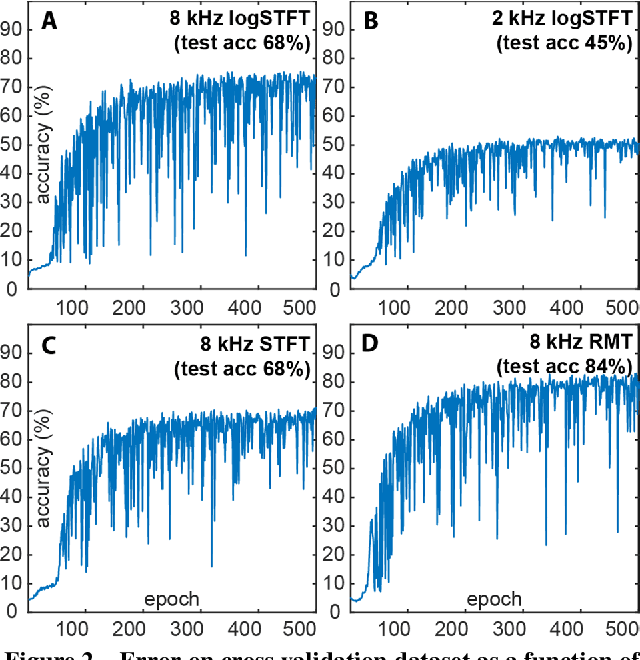
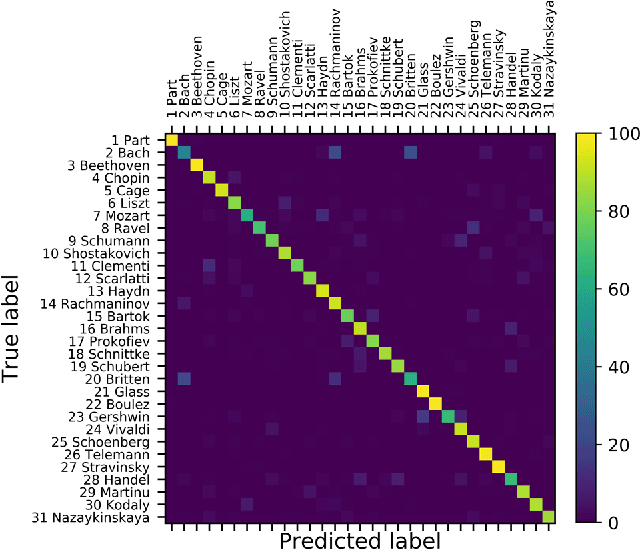
The work of a single musician, group or composer can vary widely in terms of musical style. Indeed, different stylistic elements, from performance medium and rhythm to harmony and texture, are typically exploited and developed across an artist's lifetime. Yet, there is often a discernable character to the work of, for instance, individual composers at the perceptual level - an experienced listener can often pick up on subtle clues in the music to identify the composer or performer. Here we suggest that a convolutional network may learn these subtle clues or features given an appropriate representation of the music. In this paper, we apply a deep convolutional neural network to a large audio dataset and empirically evaluate its performance on audio classification tasks. Our trained network demonstrates accurate performance on such classification tasks when presented with 5 s examples of music obtained by simple transformations of the raw audio waveform. A particularly interesting example is the spectral representation of music obtained by application of a logarithmically spaced filter bank, mirroring the early stages of auditory signal transduction in mammals. The most successful representation of music to facilitate discrimination was obtained via a random matrix transform (RMT). Networks based on logarithmic filter banks and RMT were able to correctly guess the one composer out of 31 possibilities in 68 and 84 percent of cases respectively.