 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: We Need An Algorithmic Understanding of Generative AI
Jul 10, 2025



What algorithms do LLMs actually learn and use to solve problems? Studies addressing this question are sparse, as research priorities are focused on improving performance through scale, leaving a theoretical and empirical gap in understanding emergent algorithms. This position paper proposes AlgEval: a framework for systematic research into the algorithms that LLMs learn and use. AlgEval aims to uncover algorithmic primitives, reflected in latent representations, attention, and inference-time compute, and their algorithmic composition to solve task-specific problems. We highlight potential methodological paths and a case study toward this goal, focusing on emergent search algorithms. Our case study illustrates both the formation of top-down hypotheses about candidate algorithms, and bottom-up tests of these hypotheses via circuit-level analysis of attention patterns and hidden states. The rigorous, systematic evaluation of how LLMs actually solve tasks provides an alternative to resource-intensive scaling, reorienting the field toward a principled understanding of underlying computations. Such algorithmic explanations offer a pathway to human-understandable interpretability, enabling comprehension of the model's internal reasoning performance measures. This can in turn lead to more sample-efficient methods for training and improving performance, as well as novel architectures for end-to-end and multi-agent systems.
Representations of Sound in Deep Learning of Audio Features from Music
Dec 08, 2017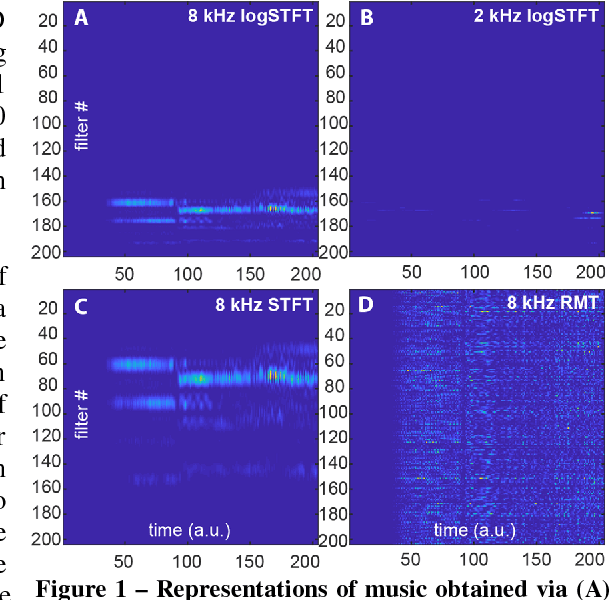
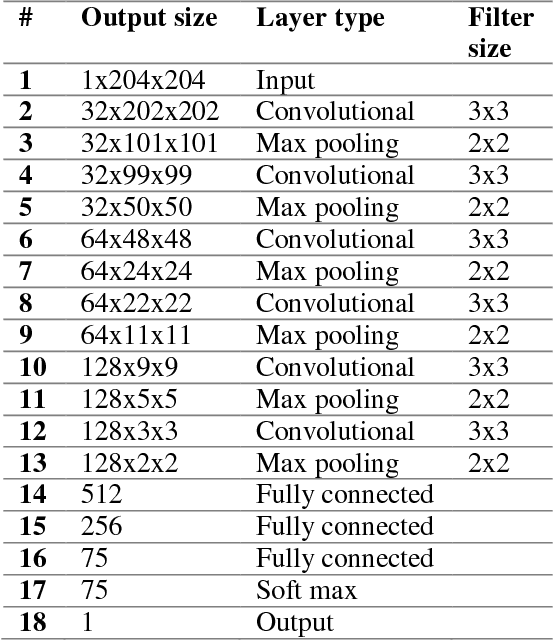
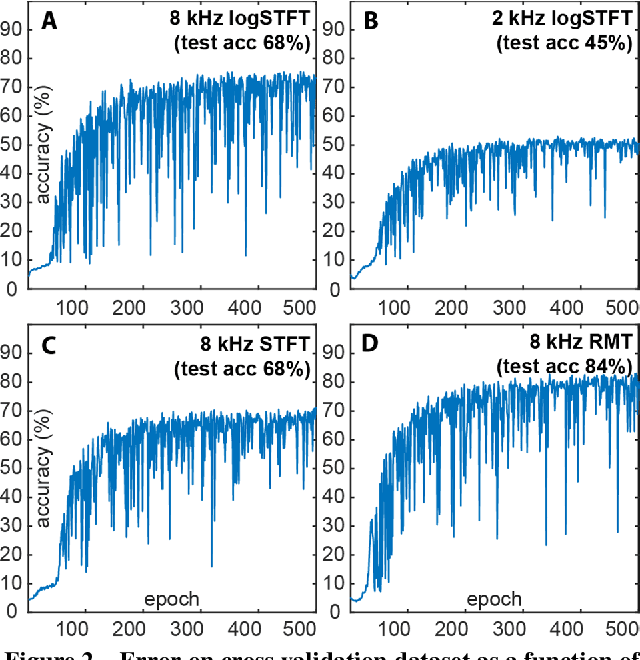
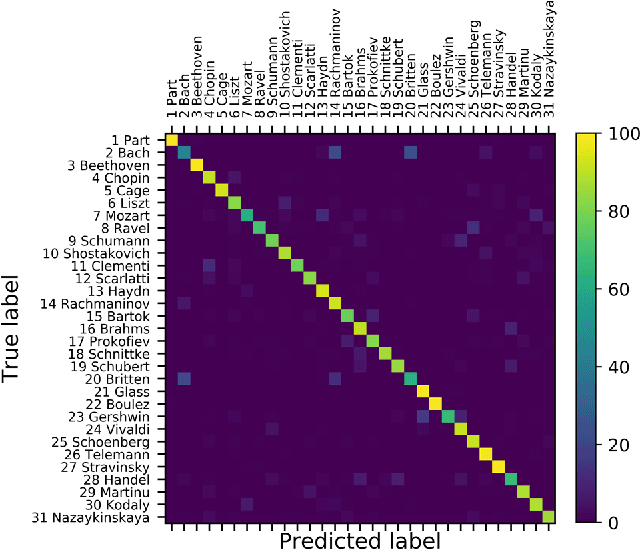
The work of a single musician, group or composer can vary widely in terms of musical style. Indeed, different stylistic elements, from performance medium and rhythm to harmony and texture, are typically exploited and developed across an artist's lifetime. Yet, there is often a discernable character to the work of, for instance, individual composers at the perceptual level - an experienced listener can often pick up on subtle clues in the music to identify the composer or performer. Here we suggest that a convolutional network may learn these subtle clues or features given an appropriate representation of the music. In this paper, we apply a deep convolutional neural network to a large audio dataset and empirically evaluate its performance on audio classification tasks. Our trained network demonstrates accurate performance on such classification tasks when presented with 5 s examples of music obtained by simple transformations of the raw audio waveform. A particularly interesting example is the spectral representation of music obtained by application of a logarithmically spaced filter bank, mirroring the early stages of auditory signal transduction in mammals. The most successful representation of music to facilitate discrimination was obtained via a random matrix transform (RMT). Networks based on logarithmic filter banks and RMT were able to correctly guess the one composer out of 31 possibilities in 68 and 84 percent of cases respectively.