 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAquaCast: Urban Water Dynamics Forecasting with Precipitation-Informed Multi-Input Transformer
Sep 11, 2025This work addresses the challenge of forecasting urban water dynamics by developing a multi-input, multi-output deep learning model that incorporates both endogenous variables (e.g., water height or discharge) and exogenous factors (e.g., precipitation history and forecast reports). Unlike conventional forecasting, the proposed model, AquaCast, captures both inter-variable and temporal dependencies across all inputs, while focusing forecast solely on endogenous variables. Exogenous inputs are fused via an embedding layer, eliminating the need to forecast them and enabling the model to attend to their short-term influences more effectively. We evaluate our approach on the LausanneCity dataset, which includes measurements from four urban drainage sensors, and demonstrate state-of-the-art performance when using only endogenous variables. Performance also improves with the inclusion of exogenous variables and forecast reports. To assess generalization and scalability, we additionally test the model on three large-scale synthesized datasets, generated from MeteoSwiss records, the Lorenz Attractors model, and the Random Fields model, each representing a different level of temporal complexity across 100 nodes. The results confirm that our model consistently outperforms existing baselines and maintains a robust and accurate forecast across both real and synthetic datasets.
Two-view 3D Reconstruction for Food Volume Estimation
Jan 12, 2017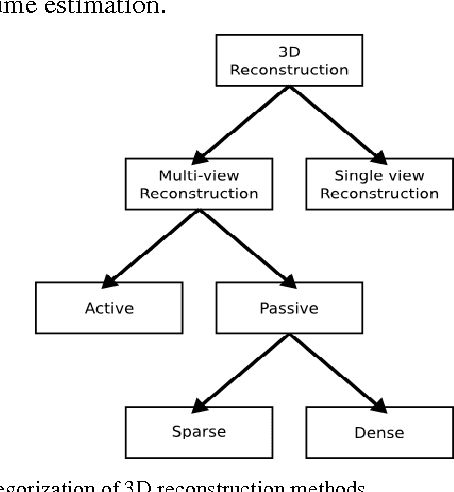
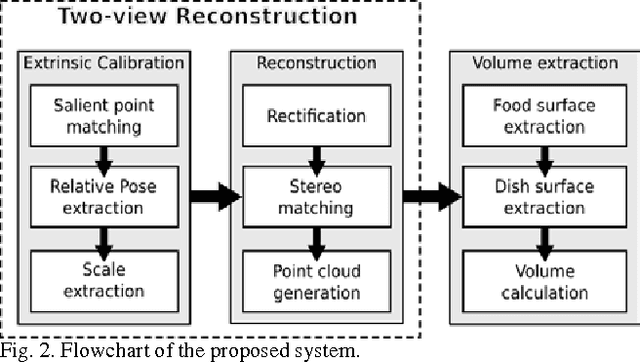
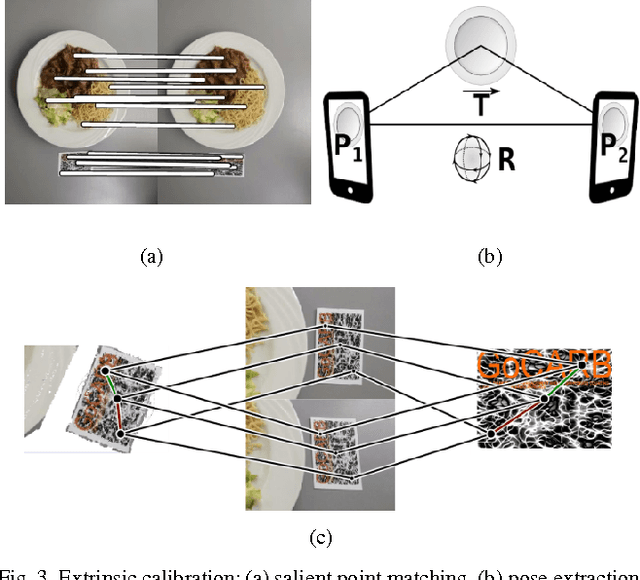
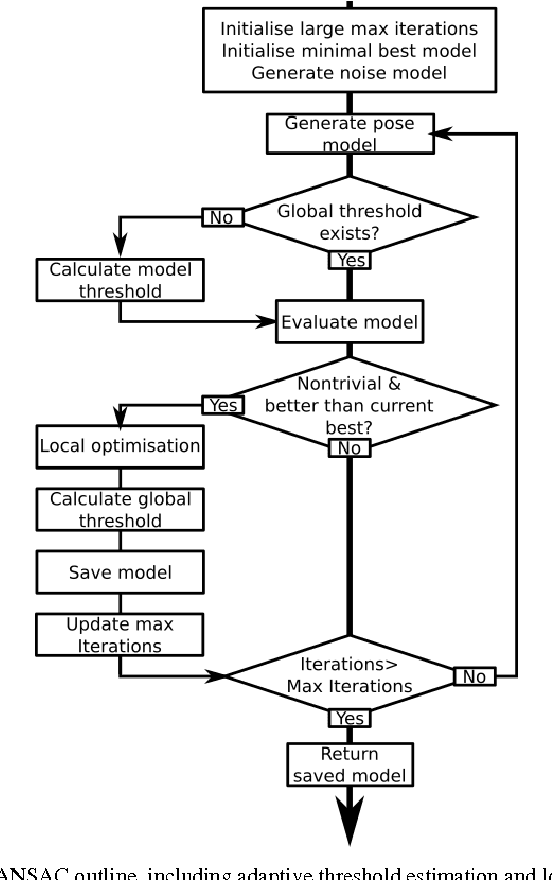
The increasing prevalence of diet-related chronic diseases coupled with the ineffectiveness of traditional diet management methods have resulted in a need for novel tools to accurately and automatically assess meals. Recently, computer vision based systems that use meal images to assess their content have been proposed. Food portion estimation is the most difficult task for individuals assessing their meals and it is also the least studied area. The present paper proposes a three-stage system to calculate portion sizes using two images of a dish acquired by mobile devices. The first stage consists in understanding the configuration of the different views, after which a dense 3D model is built from the two images; finally, this 3D model serves to extract the volume of the different items. The system was extensively tested on 77 real dishes of known volume, and achieved an average error of less than 10% in 5.5 seconds per dish. The proposed pipeline is computationally tractable and requires no user input, making it a viable option for fully automated dietary assessment.