 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Theoretical Advances in Non-Convex Optimization
Dec 11, 2020
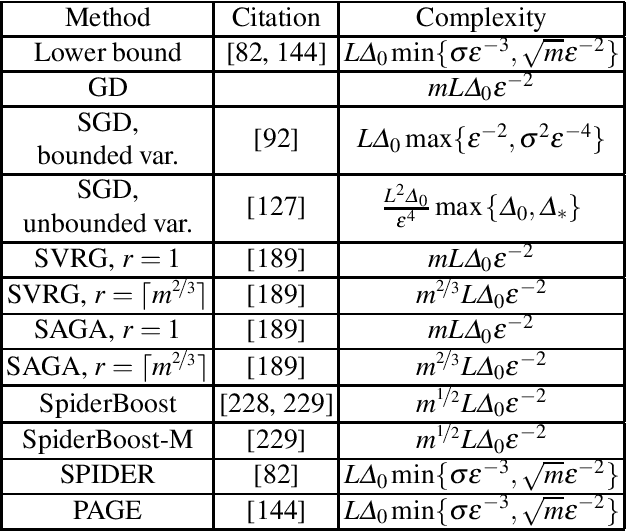

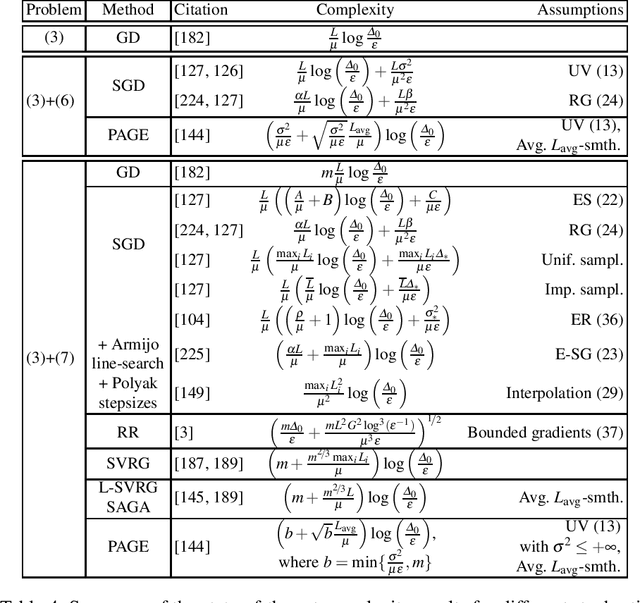
Motivated by recent increased interest in optimization algorithms for non-convex optimization in application to training deep neural networks and other optimization problems in data analysis, we give an overview of recent theoretical results on global performance guarantees of optimization algorithms for non-convex optimization. We start with classical arguments showing that general non-convex problems could not be solved efficiently in a reasonable time. Then we give a list of problems that can be solved efficiently to find the global minimizer by exploiting the structure of the problem as much as it is possible. Another way to deal with non-convexity is to relax the goal from finding the global minimum to finding a stationary point or a local minimum. For this setting, we first present known results for the convergence rates of deterministic first-order methods, which are then followed by a general theoretical analysis of optimal stochastic and randomized gradient schemes, and an overview of the stochastic first-order methods. After that, we discuss quite general classes of non-convex problems, such as minimization of $\alpha$-weakly-quasi-convex functions and functions that satisfy Polyak--Lojasiewicz condition, which still allow obtaining theoretical convergence guarantees of first-order methods. Then we consider higher-order and zeroth-order/derivative-free methods and their convergence rates for non-convex optimization problems.
On Accelerated Alternating Minimization
Jun 30, 2019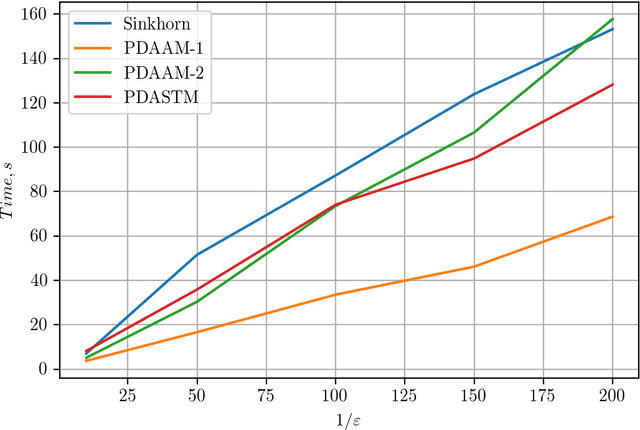
Alternating minimization (AM) optimization algorithms have been known for a long time and are of importance in machine learning problems, among which we are mostly motivated by approximating optimal transport distances. AM algorithms assume that the decision variable is divided into several blocks and minimization in each block can be done explicitly or cheaply with high accuracy. The ubiquitous Sinkhorn's algorithm can be seen as an alternating minimization algorithm for the dual to the entropy-regularized optimal transport problem. We introduce an accelerated alternating minimization method with a $1/k^2$ convergence rate, where $k$ is the iteration counter. This improves over known bound $1/k$ for general AM methods and for the Sinkhorn's algorithm. Moreover, our algorithm converges faster than gradient-type methods in practice as it is free of the choice of the step-size and is adaptive to the local smoothness of the problem. We show that the proposed method is primal-dual, meaning that if we apply it to a dual problem, we can reconstruct the solution of the primal problem with the same convergence rate. We apply our method to the entropy regularized optimal transport problem and show experimentally, that it outperforms Sinkhorn's algorithm.