 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Semi-Supervised Contrastive Learning Using In-Distribution Data as Positive Examples
Aug 03, 2024



Semi-supervised learning methods have shown promising results in solving many practical problems when only a few labels are available. The existing methods assume that the class distributions of labeled and unlabeled data are equal; however, their performances are significantly degraded in class distribution mismatch scenarios where out-of-distribution (OOD) data exist in the unlabeled data. Previous safe semi-supervised learning studies have addressed this problem by making OOD data less likely to affect training based on labeled data. However, even if the studies effectively filter out the unnecessary OOD data, they can lose the basic information that all data share regardless of class. To this end, we propose to apply a self-supervised contrastive learning approach to fully exploit a large amount of unlabeled data. We also propose a contrastive loss function with coefficient schedule to aggregate as an anchor the labeled negative examples of the same class into positive examples. To evaluate the performance of the proposed method, we conduct experiments on image classification datasets - CIFAR-10, CIFAR-100, Tiny ImageNet, and CIFAR-100+Tiny ImageNet - under various mismatch ratios. The results show that self-supervised contrastive learning significantly improves classification accuracy. Moreover, aggregating the in-distribution examples produces better representation and consequently further improves classification accuracy.
Noise Map Guidance: Inversion with Spatial Context for Real Image Editing
Feb 07, 2024Text-guided diffusion models have become a popular tool in image synthesis, known for producing high-quality and diverse images. However, their application to editing real images often encounters hurdles primarily due to the text condition deteriorating the reconstruction quality and subsequently affecting editing fidelity. Null-text Inversion (NTI) has made strides in this area, but it fails to capture spatial context and requires computationally intensive per-timestep optimization. Addressing these challenges, we present Noise Map Guidance (NMG), an inversion method rich in a spatial context, tailored for real-image editing. Significantly, NMG achieves this without necessitating optimization, yet preserves the editing quality. Our empirical investigations highlight NMG's adaptability across various editing techniques and its robustness to variants of DDIM inversions.
Compose and Conquer: Diffusion-Based 3D Depth Aware Composable Image Synthesis
Jan 17, 2024Addressing the limitations of text as a source of accurate layout representation in text-conditional diffusion models, many works incorporate additional signals to condition certain attributes within a generated image. Although successful, previous works do not account for the specific localization of said attributes extended into the three dimensional plane. In this context, we present a conditional diffusion model that integrates control over three-dimensional object placement with disentangled representations of global stylistic semantics from multiple exemplar images. Specifically, we first introduce \textit{depth disentanglement training} to leverage the relative depth of objects as an estimator, allowing the model to identify the absolute positions of unseen objects through the use of synthetic image triplets. We also introduce \textit{soft guidance}, a method for imposing global semantics onto targeted regions without the use of any additional localization cues. Our integrated framework, \textsc{Compose and Conquer (CnC)}, unifies these techniques to localize multiple conditions in a disentangled manner. We demonstrate that our approach allows perception of objects at varying depths while offering a versatile framework for composing localized objects with different global semantics. Code: https://github.com/tomtom1103/compose-and-conquer/
Topical Keyphrase Extraction with Hierarchical Semantic Networks
Oct 17, 2019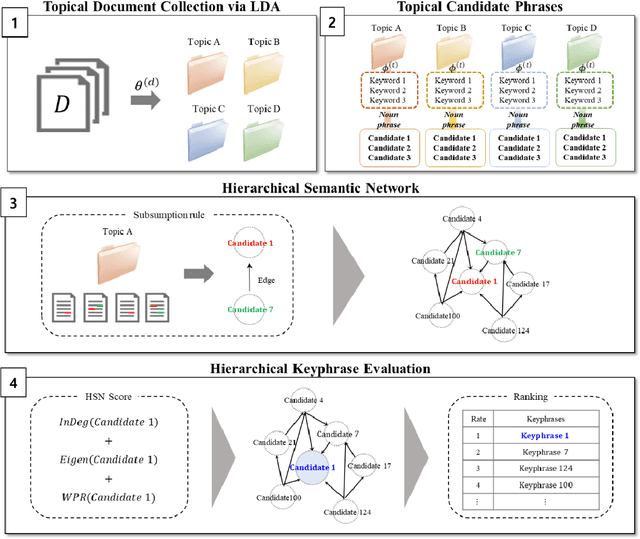
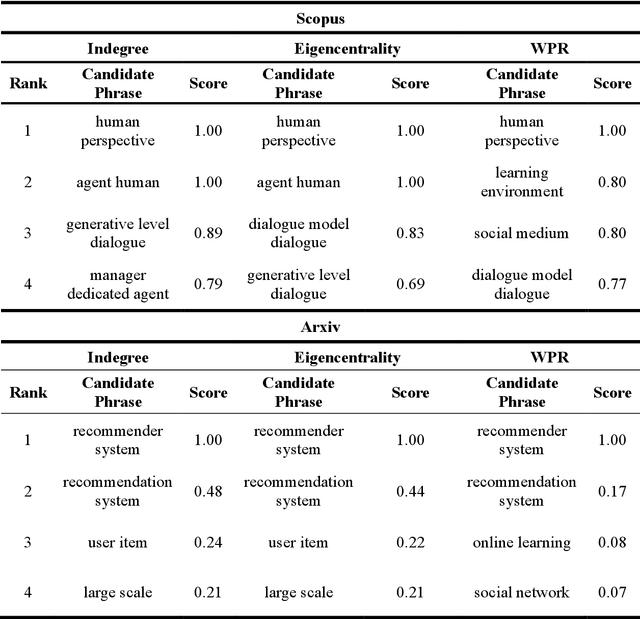
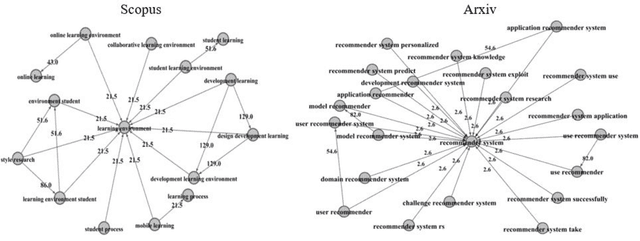

Topical keyphrase extraction is used to summarize large collections of text documents. However, traditional methods cannot properly reflect the intrinsic semantics and relationships of keyphrases because they rely on a simple term-frequency-based process. Consequently, these methods are not effective in obtaining significant contextual knowledge. To resolve this, we propose a topical keyphrase extraction method based on a hierarchical semantic network and multiple centrality network measures that together reflect the hierarchical semantics of keyphrases. We conduct experiments on real data to examine the practicality of the proposed method and to compare its performance with that of existing topical keyphrase extraction methods. The results confirm that the proposed method outperforms state-of-the-art topical keyphrase extraction methods in terms of the representativeness of the selected keyphrases for each topic. The proposed method can effectively reflect intrinsic keyphrase semantics and interrelationships.
Clear the Fog: Combat Value Assessment in Incomplete Information Games with Convolutional Encoder-Decoders
Nov 30, 2018StarCraft, one of the most popular real-time strategy games, is a compelling environment for artificial intelligence research for both micro-level unit control and macro-level strategic decision making. In this study, we address an eminent problem concerning macro-level decision making, known as the 'fog-of-war', which rises naturally from the fact that information regarding the opponent's state is always provided in the incomplete form. For intelligent agents to play like human players, it is obvious that making accurate predictions of the opponent's status under incomplete information will increase its chance of winning. To reflect this fact, we propose a convolutional encoder-decoder architecture that predicts potential counts and locations of the opponent's units based on only partially visible and noisy information. To evaluate the performance of our proposed method, we train an additional classifier on the encoder-decoder output to predict the game outcome (win or lose). Finally, we designed an agent incorporating the proposed method and conducted simulation games against rule-based agents to demonstrate both effectiveness and practicality. All experiments were conducted on actual game replay data acquired from professional players.