 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePragmatic Theories Enhance Understanding of Implied Meanings in LLMs
Oct 30, 2025The ability to accurately interpret implied meanings plays a crucial role in human communication and language use, and language models are also expected to possess this capability. This study demonstrates that providing language models with pragmatic theories as prompts is an effective in-context learning approach for tasks to understand implied meanings. Specifically, we propose an approach in which an overview of pragmatic theories, such as Gricean pragmatics and Relevance Theory, is presented as a prompt to the language model, guiding it through a step-by-step reasoning process to derive a final interpretation. Experimental results showed that, compared to the baseline, which prompts intermediate reasoning without presenting pragmatic theories (0-shot Chain-of-Thought), our methods enabled language models to achieve up to 9.6\% higher scores on pragmatic reasoning tasks. Furthermore, we show that even without explaining the details of pragmatic theories, merely mentioning their names in the prompt leads to a certain performance improvement (around 1-3%) in larger models compared to the baseline.
ClaimBrush: A Novel Framework for Automated Patent Claim Refinement Based on Large Language Models
Oct 10, 2024



Automatic refinement of patent claims in patent applications is crucial from the perspective of intellectual property strategy. In this paper, we propose ClaimBrush, a novel framework for automated patent claim refinement that includes a dataset and a rewriting model. We constructed a dataset for training and evaluating patent claim rewriting models by collecting a large number of actual patent claim rewriting cases from the patent examination process. Using the constructed dataset, we built an automatic patent claim rewriting model by fine-tuning a large language model. Furthermore, we enhanced the performance of the automatic patent claim rewriting model by applying preference optimization based on a prediction model of patent examiners' Office Actions. The experimental results showed that our proposed rewriting model outperformed heuristic baselines and zero-shot learning in state-of-the-art large language models. Moreover, preference optimization based on patent examiners' preferences boosted the performance of patent claim refinement.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Rapport-Driven Virtual Agent: Rapport Building Dialogue Strategy for Improving User Experience at First Meeting
Jun 14, 2024



Rapport is known as a conversational aspect focusing on relationship building, which influences outcomes in collaborative tasks. This study aims to establish human-agent rapport through small talk by using a rapport-building strategy. We implemented this strategy for the virtual agents based on dialogue strategies by prompting a large language model (LLM). In particular, we utilized two dialogue strategies-predefined sequence and free-form-to guide the dialogue generation framework. We conducted analyses based on human evaluations, examining correlations between total turn, utterance characters, rapport score, and user experience variables: naturalness, satisfaction, interest, engagement, and usability. We investigated correlations between rapport score and naturalness, satisfaction, engagement, and conversation flow. Our experimental results also indicated that using free-form to prompt the rapport-building strategy performed the best in subjective scores.
J-CRe3: A Japanese Conversation Dataset for Real-world Reference Resolution
Mar 28, 2024



Understanding expressions that refer to the physical world is crucial for such human-assisting systems in the real world, as robots that must perform actions that are expected by users. In real-world reference resolution, a system must ground the verbal information that appears in user interactions to the visual information observed in egocentric views. To this end, we propose a multimodal reference resolution task and construct a Japanese Conversation dataset for Real-world Reference Resolution (J-CRe3). Our dataset contains egocentric video and dialogue audio of real-world conversations between two people acting as a master and an assistant robot at home. The dataset is annotated with crossmodal tags between phrases in the utterances and the object bounding boxes in the video frames. These tags include indirect reference relations, such as predicate-argument structures and bridging references as well as direct reference relations. We also constructed an experimental model and clarified the challenges in multimodal reference resolution tasks.
A Gaze-grounded Visual Question Answering Dataset for Clarifying Ambiguous Japanese Questions
Mar 26, 2024



Situated conversations, which refer to visual information as visual question answering (VQA), often contain ambiguities caused by reliance on directive information. This problem is exacerbated because some languages, such as Japanese, often omit subjective or objective terms. Such ambiguities in questions are often clarified by the contexts in conversational situations, such as joint attention with a user or user gaze information. In this study, we propose the Gaze-grounded VQA dataset (GazeVQA) that clarifies ambiguous questions using gaze information by focusing on a clarification process complemented by gaze information. We also propose a method that utilizes gaze target estimation results to improve the accuracy of GazeVQA tasks. Our experimental results showed that the proposed method improved the performance in some cases of a VQA system on GazeVQA and identified some typical problems of GazeVQA tasks that need to be improved.
What Should the System Do Next?: Operative Action Captioning for Estimating System Actions
Oct 06, 2022
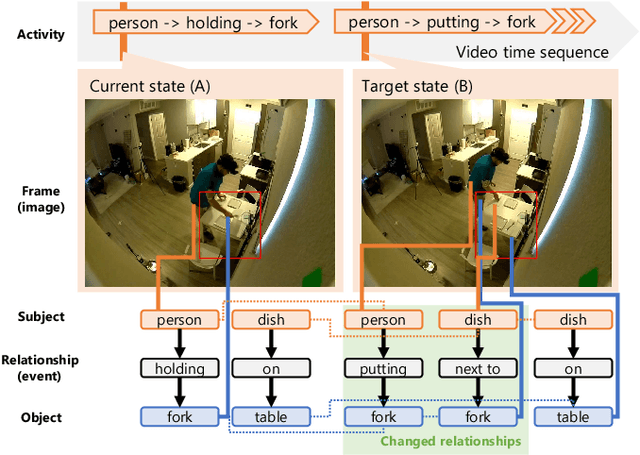
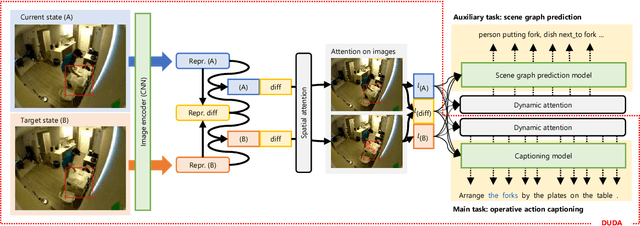
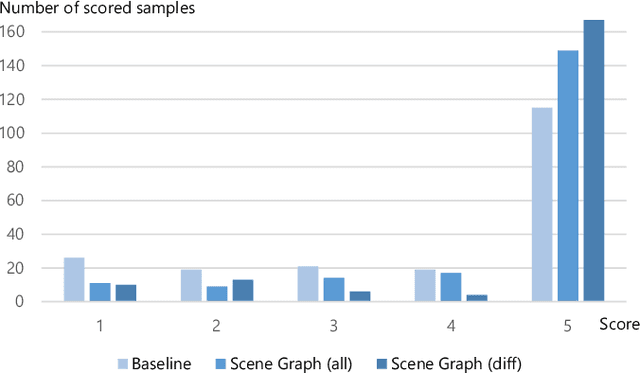
Such human-assisting systems as robots need to correctly understand the surrounding situation based on observations and output the required support actions for humans. Language is one of the important channels to communicate with humans, and the robots are required to have the ability to express their understanding and action planning results. In this study, we propose a new task of operative action captioning that estimates and verbalizes the actions to be taken by the system in a human-assisting domain. We constructed a system that outputs a verbal description of a possible operative action that changes the current state to the given target state. We collected a dataset consisting of two images as observations, which express the current state and the state changed by actions, and a caption that describes the actions that change the current state to the target state, by crowdsourcing in daily life situations. Then we constructed a system that estimates operative action by a caption. Since the operative action's caption is expected to contain some state-changing actions, we use scene-graph prediction as an auxiliary task because the events written in the scene graphs correspond to the state changes. Experimental results showed that our system successfully described the operative actions that should be conducted between the current and target states. The auxiliary tasks that predict the scene graphs improved the quality of the estimation results.