 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Generalization in Data-free Quantization via Mixup-class Prompting
Jul 29, 2025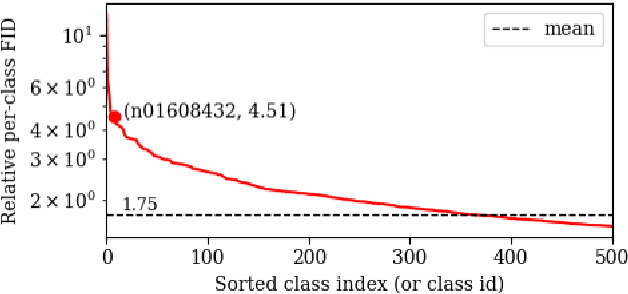
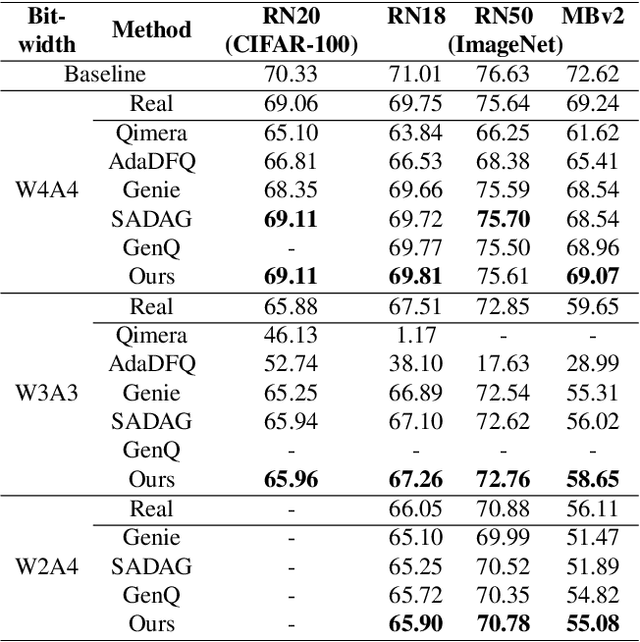
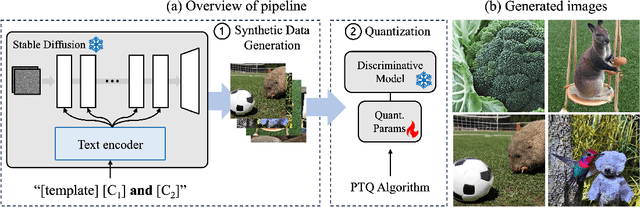
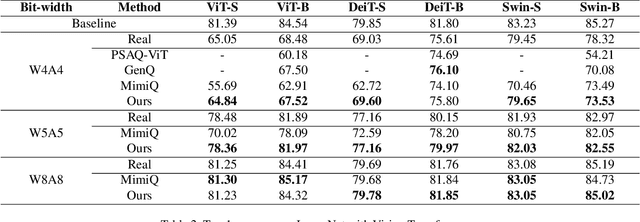
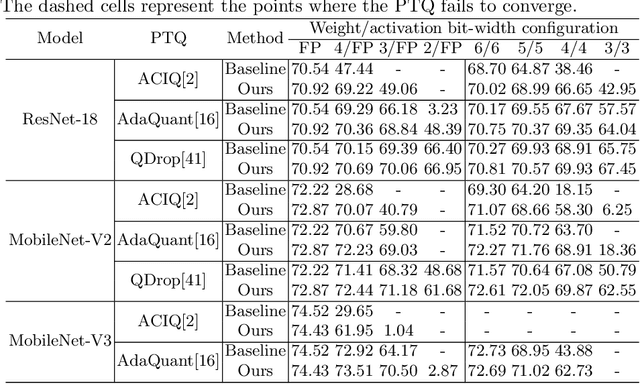
Post-training quantization (PTQ) improves efficiency but struggles with limited calibration data, especially under privacy constraints. Data-free quantization (DFQ) mitigates this by generating synthetic images using generative models such as generative adversarial networks (GANs) and text-conditioned latent diffusion models (LDMs), while applying existing PTQ algorithms. However, the relationship between generated synthetic images and the generalizability of the quantized model during PTQ remains underexplored. Without investigating this relationship, synthetic images generated by previous prompt engineering methods based on single-class prompts suffer from issues such as polysemy, leading to performance degradation. We propose \textbf{mixup-class prompt}, a mixup-based text prompting strategy that fuses multiple class labels at the text prompt level to generate diverse, robust synthetic data. This approach enhances generalization, and improves optimization stability in PTQ. We provide quantitative insights through gradient norm and generalization error analysis. Experiments on convolutional neural networks (CNNs) and vision transformers (ViTs) show that our method consistently outperforms state-of-the-art DFQ methods like GenQ. Furthermore, it pushes the performance boundary in extremely low-bit scenarios, achieving new state-of-the-art accuracy in challenging 2-bit weight, 4-bit activation (W2A4) quantization.
Symmetry Regularization and Saturating Nonlinearity for Robust Quantization
Jul 31, 2022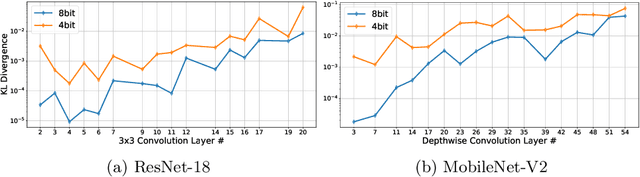
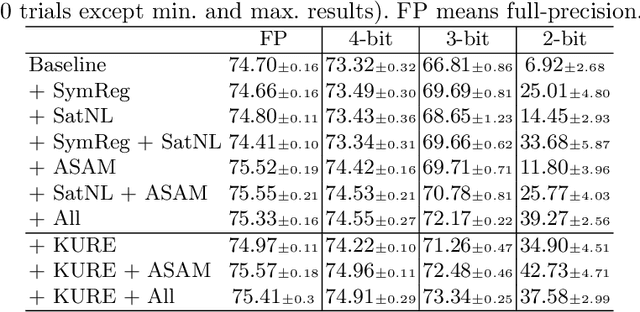
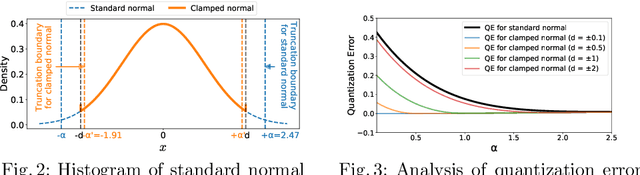
Robust quantization improves the tolerance of networks for various implementations, allowing reliable output in different bit-widths or fragmented low-precision arithmetic. In this work, we perform extensive analyses to identify the sources of quantization error and present three insights to robustify a network against quantization: reduction of error propagation, range clamping for error minimization, and inherited robustness against quantization. Based on these insights, we propose two novel methods called symmetry regularization (SymReg) and saturating nonlinearity (SatNL). Applying the proposed methods during training can enhance the robustness of arbitrary neural networks against quantization on existing post-training quantization (PTQ) and quantization-aware training (QAT) algorithms and enables us to obtain a single weight flexible enough to maintain the output quality under various conditions. We conduct extensive studies on CIFAR and ImageNet datasets and validate the effectiveness of the proposed methods.
NIPQ: Noise Injection Pseudo Quantization for Automated DNN Optimization
Jun 02, 2022
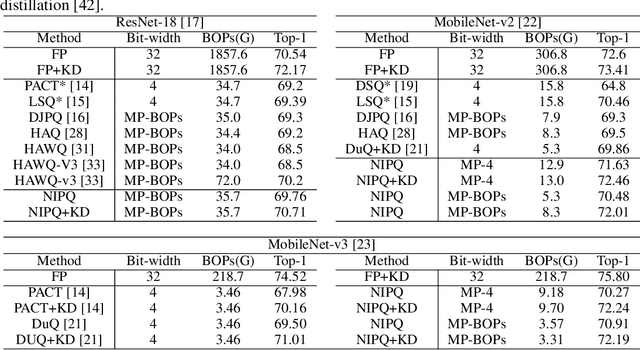
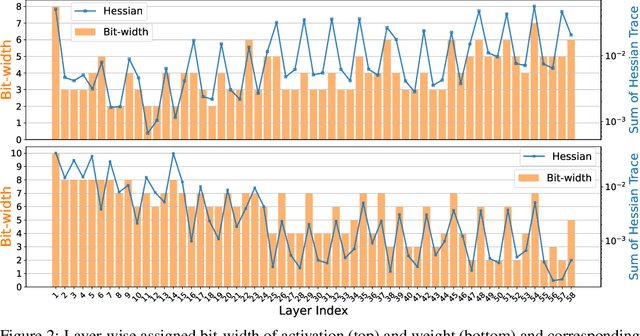
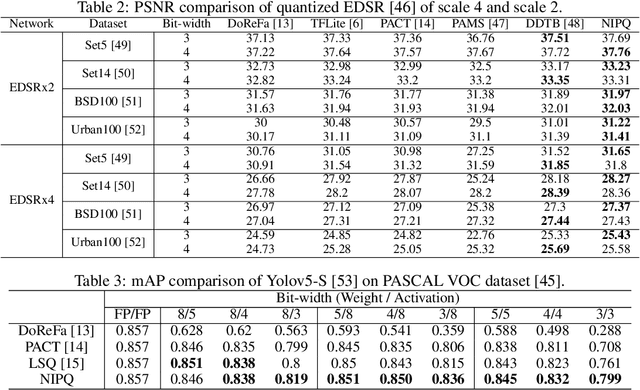
The optimization of neural networks in terms of computation cost and memory footprint is crucial for their practical deployment on edge devices. In this work, we propose a novel quantization-aware training (QAT) scheme called noise injection pseudo quantization (NIPQ). NIPQ is implemented based on pseudo quantization noise (PQN) and has several advantages. First, both activation and weight can be quantized based on a unified framework. Second, the hyper-parameters of quantization (e.g., layer-wise bit-width and quantization interval) are automatically tuned. Third, after QAT, the network has robustness against quantization, thereby making it easier to deploy in practice. To validate the superiority of the proposed algorithm, we provide extensive analysis and conduct diverse experiments for various vision applications. Our comprehensive experiments validate the outstanding performance of the proposed algorithm in several aspects.